






242.有效的字母异位词
1、链接:
https://leetcode.cn/problems/valid-anagram/
2、思路

关注!!此处字符串只包含了26小写字母,因此可以使用数组来做哈希表
分析:
需要保证每个字母出现的数量一样,即为有效—>true
因此需要判断某个字母是否在集合中---->哈希表
先创建数组,指定大小为26。
因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
储存第一个字符串中的每个字母出现的频次。在第二个数组中,减去每个字母出现的频次
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
3、解答
class Solution(object):
def isAnagram(self, s, t):
"""-》分析字母组成是否相同
判断元素在不在集合中-》哈希表
26个字母,范围有限-》哈希表选数组
:type s: str
:type t: str
:rtype: bool
"""
# 初始化哈希表 | 大小,初始值为0
hashtable = [0] * 26
# print(hashtable)
# 第一个序列,出现则次数加1
for i in range(len(s)):
# ord()返回ascii码
# 统计某个字母出现的频率
hashtable[ord(s[i]) - ord('a')] += 1 # 减a是为了,自动获取下标。因为字母的ascii码是连续的
for i in range(len(t)):
hashtable[ord(t[i]) - ord('a')] -= 1
for i in range(26):
if hashtable[i] != 0:
return False
return True
4、注意
- 此处26个字母,范围有限,可以使用数组作为哈希表
- python中获取字母的ascii码:ord()
349.两个数组的交集
1、链接
https://leetcode.cn/problems/intersection-of-two-arrays/

2、思路
如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费!
采用集合
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
3、解答
方法一:
直接返回两个set的交集
return list(set(nums1) & set(nums2))
方法二:
数组法,统计出现频率。若均大于0,则视为重合
class Solution(object):
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
# 法一数组法 | 统计出现频率,若均大于0,则重合
count1 = [0]*1001
count2 = [0]*1002
result = [] # 存放结果
for i in range(len(nums1)):
count1[nums1[i]] += 1
for j in range(len(nums2)):
count2[nums2[j]] += 1
for k in range(1001):
if count1[k] * count2[k] > 0:
result.append(k)
return result
4、注意
- 集合:set 指的是无序的不重复的元素序列
- 集合操作:交集、并集、差集
- 创建集合

- 创建空的集合
必须使用set( ) , 而不是{ } 。
因为{ }是用来创建空字典的 - 集合间的运算!
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
- 集合的基本操作
添加元素:s.add( x )
或 s.update( x ) # 这里的元素可以数列表,元组,字典等
移除元素:s.remove( x )
s.discard ( x )
s.pop() # 随机删除集合中的一个元素
202.快乐数
1、链接
https://leetcode.cn/problems/happy-number/
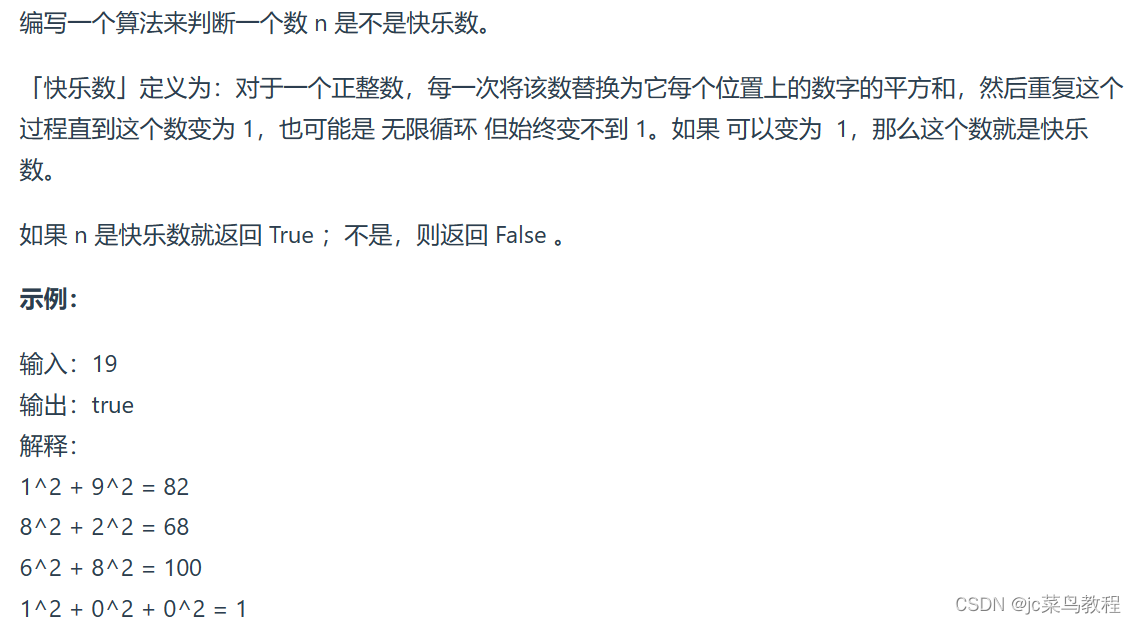
2、思路
首先要拆解个位,十位进行求和。和sum会重复出现–>快速判断一个元素是否会在集合中出现!!!----> 哈希表
若重复出现 --> return false
若sum == 1 --> return true
3、解答
4、注意
python
创建空集合
set1 = ()
1.两数之和
1、链接
https://leetcode.cn/problems/two-sum/

2、思路
1、暴力法
很明显暴力的解法是两层for循环查找,时间复杂度是O(n^2)。
2、哈希表
存储遍历过的下标
两数之和—> target - num 看得到的结果是否遍历过!
3、解答
seen = set()
for i,num in enumerate(nums):
completment = target - num
if completment in seen:
return [nums.index(completment),i]
seen.add(num)
4、注意
脑子要转过来!!!指定了两个数的和 —》 求差,看这个差值是否遍历过
454.四数相加Ⅱ
1、链接
https://leetcode.cn/problems/4sum-ii/

注意!!这里是四个数字来自于四个数组!!!
2、思路
先定义一个map,用于存放a+b的和,记录和即出现的频率
再遍历c和d, 看 -c-d是否存在于map中,若存在,则结果 += 出现的频率
3、解答
class Solution(object):
def fourSumCount(self, nums1, nums2, nums3, nums4):
"""
:type nums1: List[int]
:type nums2: List[int]
:type nums3: List[int]
:type nums4: List[int]
:rtype: int
"""
# 使用字典
hashmap = dict() # 初始化字典
# 存放a+b的和
for i in nums1:
for j in nums2:
if i + j in hashmap:
hashmap[i+j] += 1 # 若之前已经出现,则频率+1
else:
hashmap[i+j] = 1 # 若第一次出现,频率为1
count = 0
for i in nums3:
for j in nums4:
temp = -i-j
if temp in hashmap:
count += hashmap[temp] # 若存在,则count+频率
return count
4、注意
求和的时候,要拆解为差!!
舍弃空间换时间 --》 工业开发也是这样
383.赎金信
1、链接
https://leetcode.cn/problems/ransom-note/

2、思路
哈希
哈希
数组!
3、解答
法三
hashmap = [0]*26
for i in ransomNote:
hashmap[ord(i) - ord('a')] += 1
for i in magazine:
if hashmap[ord(i) - ord('a')] != 0:
hashmap[ord(i) - ord('a')] -= 1
if sum(hashmap) == 0:
return True
else:
return False
# 法一 使用数组
ransom_count = [0]*26
magazine_count = [0]*26
for c in ransomNote:
ransom_count[ord(c) - ord('a')] += 1
for c in magazine:
magazine_count[ord(c) - ord('a')] += 1
# randsom字母频率要低于magzine字母频率
return all(ransom_count[i] <= magazine_count[i] for i in range(26))
4、注意
all的使用














 2869
2869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









