







 本文深入探讨Augmented Random Search(ARS)算法,一种高效无模型的强化学习方法,旨在解决持续控制问题。ARS通过线性策略简化传统无模型RL,提高训练效率至少15倍。文章解析ARS原理,包括基础随机搜索(BRS)及其改进版本,强调算法的实用性和对现实环境的适应性。
本文深入探讨Augmented Random Search(ARS)算法,一种高效无模型的强化学习方法,旨在解决持续控制问题。ARS通过线性策略简化传统无模型RL,提高训练效率至少15倍。文章解析ARS原理,包括基础随机搜索(BRS)及其改进版本,强调算法的实用性和对现实环境的适应性。
Augmented Random #Search(ARS)学习笔记
一、增强随机搜索(ARS)缘起
在看一篇DRL相关文章时,提到有模型和无模型的增强学习,且无模型的增强学习虽然有的众多缺点,但受到热捧。
而ARS作为全新的增强学习算法,以其出众的表现,秒杀各无模型的增强学习,对此我比较好奇,觉得可以学习一下ARS。
百度搜索ARS文章不多,还是直接找国外的看吧。
这是ARS权威文章,是算法的发明人发布的文章
https://arxiv.org/pdf/1803.07055.pdf
开源的实现
https://github.com/modestyachts/ARS
下面以此文章为主线,逐步研究。
二、ARS简介
鉴于普通无模型(model-free)RL的低效和缺乏鲁棒性等缺点,算法发明人提出了一种解决持续控制问题的线性策略,这种算法至少比最快的无模型RL算法提高15倍的效率。
算法发明人认为,无模型RL目前多数用于游戏等虚拟环境,很难应用于现实环境,其原因是:首先,无模型RL需要大量的训练数据而影响训练效率,其二,即使也有提出很多的优化算法,但对特定任务如何选择算法,如何部署又产生了新问题。
算法发明人还认为,人们为解决问题,又提出更复杂的算法,导致可复现性和鲁棒性的不断降低的恶性循环。
以上都导致无模型RL难于用于现实环境。
基于以上讨论,简化的RL算法才是王道。
三、ARS原理
现在进入正题,讲算法原理。
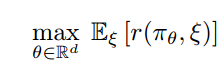
RL就是为了在给定的任务里,得到最大平均回报(reward),上面公式中 r(πθ, ξ) 表示参数θ对应策略πθ和环境编码后得到的随机变量ξ对应的回报,通过Eξ的一系列活动后,得到最大平均回报。
3.1 基础随机搜索(Basic random search,BRS)
BRS的伪代码

ARS算法是在BRS基础上扩展和改进的。
BRS被Flaxman称为“土匪梯度下降”(Bandit Gradient Descent),大概指它的简单粗暴,ARS发明人说这个BRS算法有很多名称,至少有50年的历史了,近期被一些旨在优化算法的社团挖掘出来。
我讲讲我对这个算法的理解,不一定对,请大家指正。
(由于字体大小不方便调整,所以下标都用同样字体了,请海涵)
伪代码中θj表示训练中第j步的策略参数矩阵。πθj就是第j步的策略,r(πθj) 就是第j步的策略(使用θ参数)得到的回报(reward)。
关键地方来了,怎样从第j步的参数θj推导出j+1步的参数θj+1呢?我们可以想象在一个空间里的一个点,这个点可以向各方向移动,但不同的方向会得到不同的回报,我们要找到最接近最大回报的方向。
我们可以用一个统计规律来解决这个问题。我们围绕这个点,做一个足够小的半径的球形,球形上随机且均匀分布的取足够多的点,然后计算这些点及这些点在球上对称点的回报,某点及这些点在球上对称点的回报的差值越大表示这个点越接近最大回报的方向。把所有点和球上对称点的回报的差值乘上方向向量求总和,再取平均值,将得到最大回报方向的近似值(我的理解是,非最大回报方向的向量都会被其他方向的向量抵消掉)。
表示球上任意取一点为k点的策略和其球上对称点的策略:
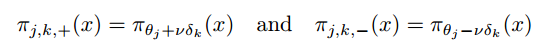
表示第j步的参数,加上最大回报向量,得到第j+1步的参数。(α是步长):
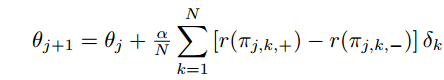
3.2 ARS 的三个版本
ARS的各版本伪代码:

ARS V1:在BRS基础上,把所有点和球上对称点的回报的差值乘上方向向量求总和,再取平均值,再除以所有回报值的标准差,用以调整步长(也就是变化越大,步长越小,变化越小,步长越大)。
ARS V2:加上根据平均值和方差线性映射状态找到最大回报方向。(发明人会后面解释)
ARS V1-t,ARS V2-t:这个是对ARS V1,ARS V2的训练中,排除了部分对回报作用最少的干扰项向量。(发明人也会后面解释)

















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









