






论文:Poly Kernel Inception Network for Remote Sensing Detection
文章地址:https://arxiv.org/pdf/2403.06258.pdf
code地址:GitHub - NUST-Machine-Intelligence-Laboratory/PKINet
环境安装:
首先,从AutoDL上面租一台服务器,服务器类型根据自己的情况选择吧,我选择的是3090单卡来跑实验。
这一步就是按照作者的配置:
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
conda install pytorch==1.11.0 torchvision==0.12.0 cudatoolkit=11.3 -c pytorch
pip install yapf==0.40.1
pip install -U openmim
mim install mmcv-full
mim install mmdet
mim install mmengine
git clone
cd PKINet
mim install -v -e .
这个环境还是很好安装的,没有出现向我以前复现的论文中mmcv环境问题的出现。
数据集的准备:
(如果你使用服务器的话需要进行ms或者ss类型的DOTA数据集跑程序,我建议你开服务器前扩容一下数据盘,因为后面我们需要对DOTA数据集进行分割。)
把数据集拷贝到程序中,我为了符合作者的路径,我在PKINet文件下创建了data/DOTA/文件夹。
接下来解压数据使用unzip解压。
然后就是数据集分割了,按照tools/data/dota文件夹中的README文件的指令进行分割,我这里选择分割为ms类型,就是多尺度的小目标类型。指令如下:
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_trainval.json
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_test.json
开始分割:
这个分割过程还是挺慢的。
然后改一下configs/_base_/datasets/dotav1_ms1024.py中的文件路径改成你自己存放的路径。
还有一个地方记住也要改,就是configs/pkinet/pkinet-s_fpn_o-rcnn-dotav1-ss_le90.py文件中的这个,如下图所示:改成你自己想要测试的尺度类型,就像我需要改为ms类型的。


开始训练:
使用如下图指令开始训练:
python /root/autodl-tmp/PKINet/tools/train.py /root/autodl-tmp/PKINet/configs/pkinet/pkinet-s_fpn_o-rcnn-dotav1-ss_le90.py
备注:pkinet-s_fpn_o-rcnn-dotav1-ss_le90.py,这个是你要跑的模型的代码,你也可以自己选择其他的。

我丢,mmcv报错还是来了,换个mmcv版本试一试。先去这个网站找适合我们pytorch和cuda版本的mmcv版本:Installation — mmcv 2.1.0 documentation
我换了1.7.1的mmcv-full,运行又出现问题,看看怎么回事。
这次的问题是初始化权重没有加载,哦,对了我忘记把预训练的权重加载进去了,再去把预训练权重下载过来。

此时,我们要改这里,看图说话:

备注:作者默认是多卡跑的。
再输入:python /root/autodl-tmp/PKINet/tools/train.py /root/autodl-tmp/PKINet/configs/pkinet/pkinet-s_fpn_o-rcnn-dotav1-ss_le90.py 跑一下,我丢怎么又报错。这玩意ValueError: need at least one array to concatenate,debug看下,发现导入数据集路径错了,导致未加载成功。改写后,再跑。

OK,能训练了,时间太久了,那先直接拿作者训练好的权重文件来测试吧。
这次错误的解决,主要是因为以前复现过LSKNet,文章中又提到了LSKNet,然后看了下LSK的train.py的代码,两者差不多,找到以前我看过LSKNet复现的帖子,才发现没导入权重文件和改单卡模式,LSKNet复现的帖子在这里ICCV 2023 | LSKNet【保姆级】训练自己的目标检测模型-CSDN博客,这个博主讲得很仔细。
测试:
我们进行测试和demo实验,从官网上下载权重文件,如下,我测试的是DOTAv1.0的,但是只有ss的权重文件,先试一试能不能跑,不能跑再换ss类型的数据集。

在服务器上可以输入:
python ./tools/test.py \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/pkinet_s_o-rcnn_dotav1-ss.pth --format-only \
--eval-options submission_dir=work_dirs/Task1_results
结果:
时间太久了吧,快两个小时了,有实力的童鞋可以等着看看结果,我直接进行demo实验吧。
Demo实验:
使用这段指令进行demo实验:
demo/huge_image_demo.py \
demo/dota_demo.jpg \
configs/pkinet/pkinet-s_fpn_o-rcnn-dotav1-ss_le90.py \
PKINet/pkinet_s_o-rcnn_dotav1-ss.pth \
我在pycharm上跑的结果如下:
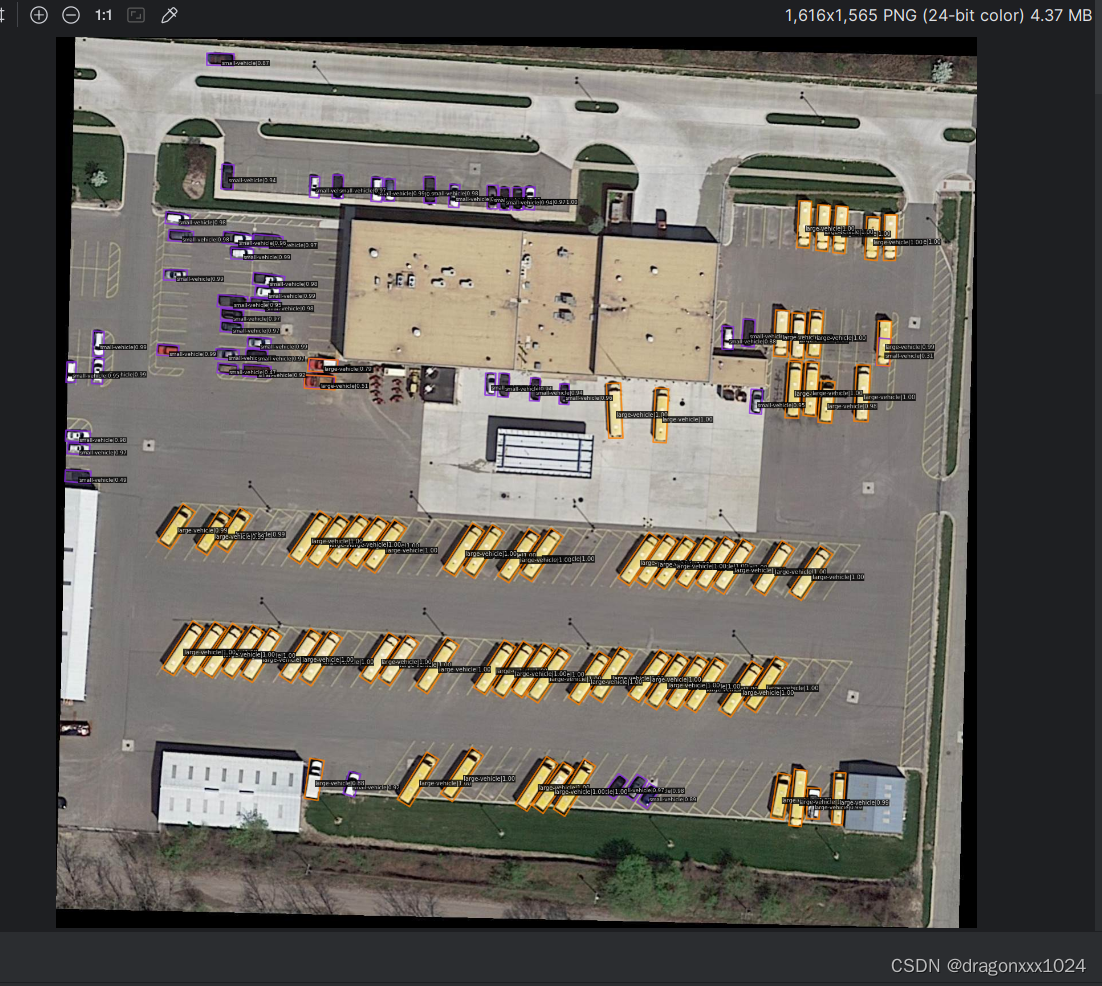

这里导入的权重文件一定要对号入座,我就犯了一个错误,用错了权重文件,导致检测的目标不完整。
本次复现也踩了很多的坑,这也是我第一篇博客,不对之处请各位指教,也当做我自己的一个笔记吧,毕竟好记性不如烂笔头。















 1497
1497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









