







博主虽然学计算机出身,惭愧的是对计算机的许多方向都不了解。决定从现在开始,多读书,对各个方向都看一看。刚看完数学之美这本书,介绍了许多数学原理在计算机行业的应用。博主想简单总结一下,本篇主要围绕搜索引擎技术来介绍。
当我们在Google搜索框里面打一个词时,Google可以立即返回全网的搜索结果。这看似简单的背后,其实有着很复杂的处理过程。能够这么快的返回查询结果,依赖于搜索引擎对全网知识所做的预处理。这个预处理就是网络爬虫和索引表。索引表类似于书本的目录,根据目录,可以迅速找到某些内容所在的页码。索引表存储的是从关键词到所在网页的映射关系。很容易想到,全网有着数亿计的网页数目,这个索引一定十分巨大。而且,每个关键字也对应着的许多网页,这就构成了我们在搜索引擎里输入一个词时的候选网页集合。当我们输入多个词时,会得到多个集合,它们的交集自然就是包含了所有关键字的候选网页。
1.爬虫
那么,索引表是如何产生的呢?互联网有着庞大的网页数目,而且网页信息是每天都在变的,怎么收集这么多网页信息呢?完成这个功能的部件一般称为网络爬虫。整个互联网可以用一个巨大的图来描述,每个网页都是其中一个节点,网页之间的链接可以描述为节点之间的边。网络爬虫的作用就是遍历整个图,收集信息。 假定以qq.com作为入口,爬虫首先采集该网页上的关键字信息,然后分析该页面直接链接出的所有网页,例如tech.qq.com, house.qq.com, jd.com等。接下来,从这些网页出发,又可以链接到更多的网页。重复这个过程,计算机就可以下载整个互联网的信息。爬虫一词比较形象的描述了这个过程。考虑到全网巨大的数据量,网页动态更新等问题,实际搜索引擎中的爬虫比这个复杂得多。
2.PageRank
根据索引表查询出来的候选集还不能直接返回给用户,虽然它可以包含了用户查找的所有关键字,但是网页质量参差不齐。网页质量是一个非常影响搜索结果体验的因素。Google一出来就能迅速占领搜索市场的一个很重要的因素就是它的返回的网页是根据质量排名的,用户能够很容易找到想要的结果。那么,网页质量该如何评价呢?Google在这一方面作出了革命性的贡献,这就是它的PageRank算法。PageRank的基本原理有两点:
(1)如果一个网页被很多其他网页链接,那么这个网页肯定是比较可靠和普遍信任的。就像是在淘宝上买东西一样,如果某个商品有大量人推荐,我们很容易相信它是比较靠谱的。
(2)如果一个可靠性较高的网页指向了另外一个网页,那么这另外一个网页也是比较可靠的。这就是所谓的名人推荐效应。名人代言一个广告,肯定比无名小辈好。
下面是来自wikipedia的一张图。图中ABCDEF均表示网页,球的大小表示了网页质量。从图中可以看出,指向B和E的网页均较多,因而B和E排名较高。另外,虽然指向C的网页很少,但是有排名较高的B指向了C,因而C的得分也比较高,排名甚至比E还好。
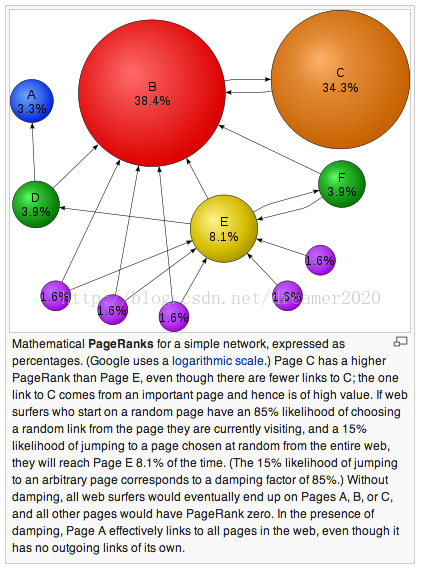
那么,如何计算PageRank呢?因为,一个网页的排名是依赖于指向它的网页的,所以很适合于用迭代法计算。假定初始条件下,N个网页的PageRank值都是1/N。如果网页k指向了n个网页,那么将k的PageRank值平摊给这n个网页。一个网页的PageRank取它所分得的所有平摊值的和。重复迭代计算直到结果收敛。上面只描述了一个简单的PageRank值的计算思路。事实上,网页之间的权值可以前很多比较复杂的计算办法。在实际应用中,网页数量也是一个巨大的数字,所以计算量大得难以估计。
3.网页相关性
在评估了网页质量后,下面就是如何度量网页和关键词相关性的问题了。使用过搜索引擎的人都知道,返回结果如果不是我想要的会令人非常恼火。一个简单的想法是,包含了关键词数量越多的网页,相关性就越大。这样,确实可以找到包含关键词数量比较多的网页,不过有一个漏洞,很明显,内容较长的网页很占便宜。所以,进一步的,可以考虑用关键词出现的频率作为比较依据,即搜索关键词数量除以文章的总词数,这个通常被称作单文本词频(Term Frequency)。如果一个查询包含了n个关键词,那么相关性可以用TF1+TF2+...+TFn来衡量。
进一步的,上述方法还有一个漏洞。比较“数学”和“勾股定理”两个词,数学更难识别,因为包含数学的网页数量较多,相反,包含“勾股定理”的网页就要少好多,更易于识别。因而,需要给每个词设置一个权重。如果这个词易于确定搜索主题,就给一个较大的权重。例如,“勾股定理”限定了网页的内容,相对的,数学这个词描述的内容则太宽泛了。根据统计经验,如果一个词出现过的网页数量越多,那么它越难锁定网页,它对应的权重应该较小。相反的,如果一个词在网页中很少出现,那么它很容易锁定搜索目标,这样权重就越大。在信息检索中,通常使用逆文本频率指数(Inverse Documentary Frequency,简写为IDF)来描述这个权重,这个值定义为log(D/Dw),其中D是全部网页数,Dw是单词w出现过的网页数目。如果一个词在所有网页中均出现,即Dw=D,那么这的IDF=log(1/1)=0,很好理解,它对于筛选搜索结果没有任何帮助。
这样,如果一个搜索结果有n个词,那么其网页相关性可以计算为TF1*IDF1+TF2*IDF2+...+TFn*IDFn。TF-IDF被公认为信息检索中最重要的发明。在搜索、文献分类等领域都有着广泛的应用。
关于搜索引擎的介绍,就说这么多。搜索引擎是一个非常复杂的系统,有许多值得深入研究的问题。例如,在全网这么大规模的数据量下,索引表该如何设计,爬虫怎么收集全网信息,怎么实时监测网页动态变化,PageRank中有没有更靠谱的权重计算方法,这些系统在分布式平台下如何实现等。当然,这些还是需要有实际工作经验的人来回答了。博主并不是专业做搜索引擎的,只能简单的概括一下了。















 5532
5532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









