







原文链接,欢迎评论
https://dreamhomes.top/posts/202010091143.html
核密度估计
核密度估计是采用平滑的峰值函数(“核”)来拟合观察到的数据点,从而对真实的概率分布曲线进行模拟,含义类似于数据直方图。
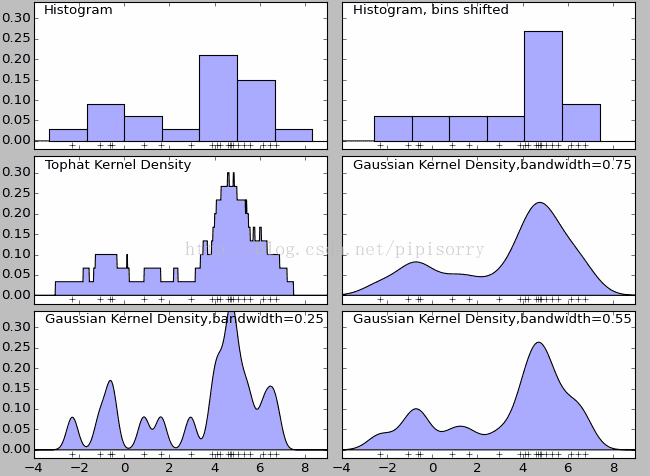
核密度估计(Kernel density estimation),是一种用于估计概率密度函数的非参数方法,为独立同分布的 n n n个样本点,设其概率密度函数为 f f f,核密度估计如下:
f ^ h ( x ) = 1 n ∑ i = 1 n K h ( x − x i ) = 1 n h ∑ i = 1 n K ( x − x i h ) \hat{f}_{h}(x)=\frac{1}{n} \sum_{i=1}^{n} K_{h}\left(x-x_{i}\right)=\frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{x-x_{i}}{h}\right) f^h(x)=n1i=1∑nKh(x−xi)=nh1i=1∑nK(hx−xi)
其中 K ( . ) K(.) K(.)为核函数(满足性质:非负、积分为1,符合概率密度性质,并且均值为0); h > 0 h>0 h>0为一个平滑参数,称作带宽(bandwidth)或者窗口;
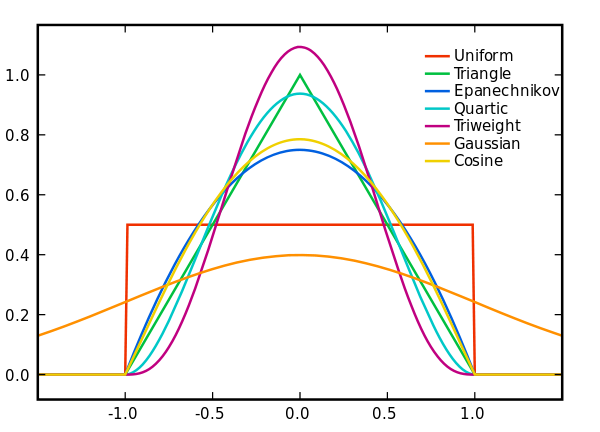
有很多种核函数,uniform,triangular, biweight, triweight, Epanechnikov,normal 等,函数形式如下:
累积分布函数
从数学上来说,累积分布函数(Cumulative Distribution Function, 简称CDF)是概率分布函数的积分;而在绘制累积分布函数的时候,由于真实的概率分布函数未知,因此往往定义为直方图分布的积分:
cdf
(
x
)
≈
∫
−
∞
x
d
t
histo
(
t
)
\operatorname{cdf}(x) \approx \int_{-\infty}^{x} \mathrm{d} t \operatorname{histo}(t)
cdf(x)≈∫−∞xdthisto(t)
与直方图、核密度估计相比,累积分布函数存在以下几个特点:
- 累积分布函数是X轴单调递增函数。
- 累积分布函数更加平滑,图像中噪音更小。
- 累积分布函数没有引入带宽等外部概念,因此不会丢失任何数据信息。对于给定的数据集,累积分布函数是唯一的。
- 累积分布函数一般都经过归一化处理,单调递增且趋近于1。
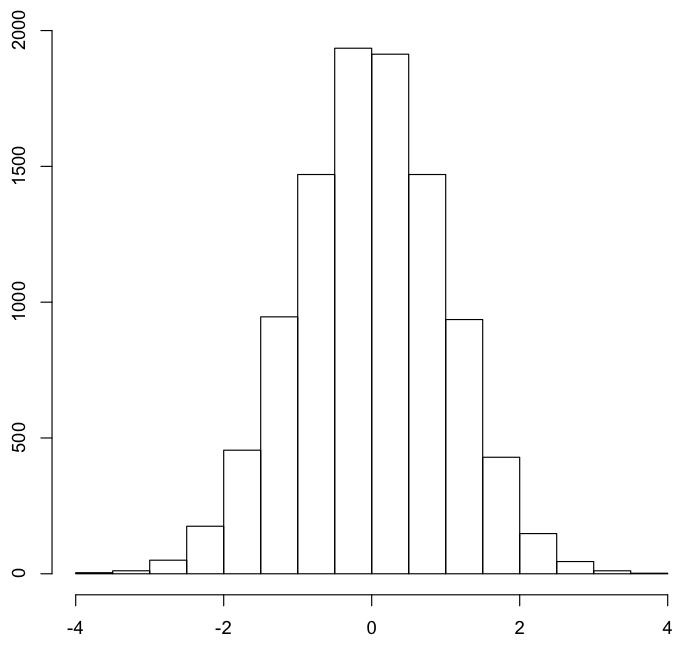
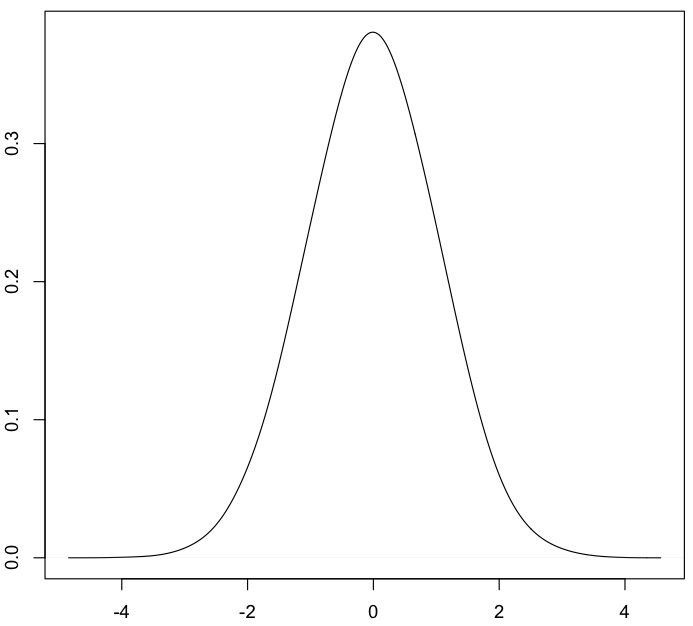
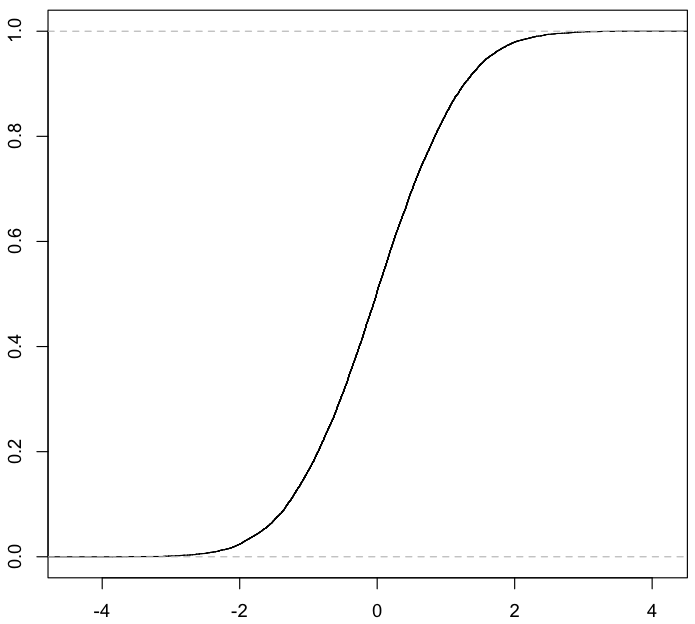
实例
以-4到4之间分布的10000个数据点为例,绘制成直方图,核密度估计和累积分布函数如下所示:
直方图
核密度估计
累积分布函数














 3785
3785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









