







1. 由来
神经网络是一种模仿动物或人类大脑的设计思路。虽然计算机有超强的计算能力但是只能线性的计算或处理简单的任务,并不能完成完成复杂的任务或者像人类一样模糊的认知(计算机只能做到0或1的绝对认知),比如这个动物看着有些像马也有些像驴,类似这样的认识。动物或人类的大脑是通过多个神经元相互连接并且相互传递信息形成一个网络最终输出结果的。如下图所示,

初始信号(数据)从最左端开始向右边传递,在传递过程中会有一些信息的加工或修改,最终到达重点的时候就变成了我们的反应或行为(结果)。当然外来信号可能不止一个,每一个树突都会接收一个信号,然后经过加工传递给轴突然后到达终端继续传递给下一个神经元。我们希望计算机可以模拟这一过程,如下图所示,

2. 激活函数
上图的信号a-h同时刺激这一个神经元,按照自然规律我们不是所有的外来信号都去理会的,太小的信号我们可能会忽略掉,比如蚊子停留在我们的皮肤上我们可能会毫无差距。因为如果过小的信息我们都要去理会或者刺激神经元的话,那我们可能会崩溃掉的。我们的神经网络也要模拟这一点特性。所以需要一个函数当信号强度达到一定程度的时候才会有反应。如下图所示,

但这个图形有些过于生硬,现实中没有这么绝对的,于是我们优化一下,使用s函数来作为激活函数。如下图所示,

3. 链接强度(链接权重)
这样一来就变成了多个输入的总和,然后将这个总和应用激活函数最终得到单个神经元的输出。但是这些输入不能单纯简单的求和,因为有些信息是我们所看重的有些则是我们不希望关注的,所以在求和时需要加入权重,那么整个过程如下图所示,

这样包含权重和激活函数的神经节点相互连接就可以达到模糊计算的效果了。接下来看看网络的结构。
4. 网络数据传递
由于每一个神经元前面和后面都连接了n个神经元,我们图形化这样的连接,如下图所示,

这里显示的连接,从输入到中间每层节点再到输出的结果,都用了全部连接(每个节点都相互连接)。当然在自然界这可能不现实,并不是每一个神经元都相互连接的,但是我们应用了权重这一因素,假设从节点1到节点6的连接是不存在的,那么将节点1到节点6的连接权重设置成0或者无限接近0即可达到断开连接的效果,并且这样设计成全部连接更方便的使计算机去计算神经网络。下面以一个简单的例子来说明数据的传递,如下图所示,

第一层作为输出层1.0和0.5直接进入节点不需要进行加工,这样数据从输入层传递到输出层(这里一共两层所以第二层就作为了输出层)就进行了权重求和以及激活函数最终得到两个结果,当然复杂一些的神经网络在输入层和输出层中间会有很多层,就像之前的图片看到的一样。中间的n层数据传递原理和这个道理相同。
5. 使用矩阵
如果神经网络层数多了之后整个计算会变得很庞大,需要一个很好的工具使计算机更有效的计算庞大的神经网络数据传递过程,这样完全连接的神经网络非常适合使用矩阵去计算。将上图的简单的例子矩阵化后,如下图所示,

根据公式每一层节点的最终输出都会作为下一层的输入结果,画一个图帮助我们理解,如下图所示,

设置好权重的初始值,这样整个网络雏形就构建好了。但是这样的网络不具备学习能力,不能根据具体的问题来得到最优化的答案。
6. 网络学习能力
6.1 反向传播误差
所谓学习能力就是要根据实际数据来调整神经网络以使输出结果更加准确。根据之前的设计可以进行调整的部分只有改变权重的大小和激活函数的形状,由于改变激活函数的形状过于复杂所以我们选择改变权重的大小来使其具备学习能力。我们使用与训练数据之间的误差来进行调整,这样我们每用一个训练数据训练一次神经网络,它的输出结果就离最优解近了一步。如果是一元的函数我们很容易推算误差,例如y(x) = 2x+1这个函数,我们得到结果y的误差是2,那么x的误差0.5,但是我们的神经网络是多元的(多条链接的),这样我们可能想到的有3种办法:
- 只调整单条链接的权重:忽略其他链接及其权重就是的神经网络失去了意义
- 每条链接平均分配:虽然看上去还不错,但是不够完美
- 按照每条链接占总链接的比例分配:根据权重占比,也就是每条链接对造成误差的贡献不同而划分,这样很合理
按照第三种方法去分配误差,如下图所示,

这样节点3和4的输出误差就反向传递到连接节点3和4的链接上,然后根据链接继续传递到上一层的节点上,如下图所示,

我们之前数据传递从输入到输出是正向的,而误差则是反向传播的,从输出一层一层传递到输入层,这样每一层都有对应的误差了。接下来就是如何让计算机去计算整个反向传播过程,我们依旧采用矩阵的方式,根据上图的例子转化成矩阵,如下图所示,

因为有分数的存在使得整个计算不但看上去复杂实际计算也变得复杂了很多,分数的出现是因为我们想得到某一个链接的比重,如果我们把分母想像成一个整体,单纯从分子上我们依然可以分辨出哪一个链接比重大哪一个比重小,只不过忽略分母的话整个比重会变得大了些,然后乘以误差的话扩大了误差的大小,因为我们的神经网络学习是迭代学习的,就算扩大了误差大小,但是在迭代过程中一点一点还是会趋向与最好的结果的,所以去掉分母并不会给我们带来什么问题,反而让我们的公式变得清晰简单了许多。简化后我们再来看看反向传播的误差矩阵与正向传播的数据矩阵之间的关系,还是以上面的例子为例,如下图所示,

上图可以看出,反向传播误差矩阵中的权重矩阵沿对角线反转后变成了正向传播中的权重矩阵,所以公式可以变成上图所写的这样。这样整个网络的误差就可以获取了,接下来就是根据误差去更新权重。
6.2 更新权重(最核心的部分)
前面我们已经得到了每一个节点上的误差,网络学习的目的是让误差减小到最低,而导致这些误差的是从上一层的每个节点连接到该节点的所有权重。我们需要求的是当权重(W)为什么值时误差(E)最小。也就是误差(E)与权重(W)之间关系的函数,如果给我们一个已知的一元函数,那我们很容易的找出这个W的值,比如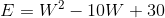

左右两边分别是两次向下探路,我们可以看到右边这次到达了山谷,因为W是很多个的,所以真正的山谷也可能不止这几个,但是多次尝试总有更好的结果的。每一个位置都可以产生对应的切线(斜率),斜率的绝对值越大坡度越陡,当斜率为0时表示到达了山底(也可能是山谷,我们统一先认为是山底,表示梯度下降结束)。这样我们就可以根据斜率来更新权重了。图中可以看到当斜率为正时我们向左走(W减小,也就是要
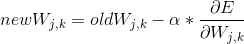
我们加了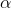
,绝对值的方法导致函数图形呈V字形,这样梯度下降在山底会来回震荡,效果不好
,平方的方法比较平滑,效果很好
然后我们将式子做一下变形,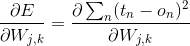
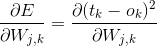
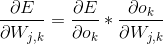
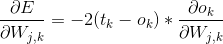
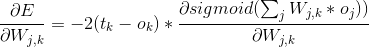
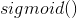
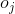
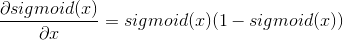
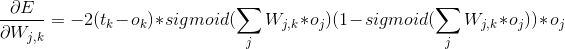
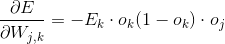
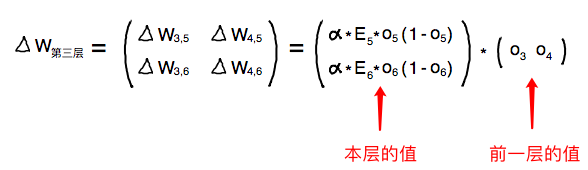
可以看到最后一项正好是之前正向传播第二层输出矩阵的反转,并且我们把斜率的负号给省略了,因为斜率的负号正好可以与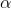
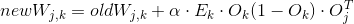
7. 细节优化
7.1 输入数据
通过之前的s函数图像可以看到,当输入值过大时,函数值的变化就会非常小,这样我们进行梯度学习的时候学习效果会非常差,图中刻度可以看到-1到1之间函数值的变化非常大,负数不予以考虑然后0会使权重更新表达式变为0从而丧失学习能力,所以最后输入的取值范围最好在0.01-1.0之间。
7.2 输出数据
通过之前的s函数图像可以看到,函数最大值不会大于等于1,所以我们的神经网络输出的值也不会大于等于1,那么训练数据就不能大于等于1,否则训练不出结果的。所以需要将训练数据缩小到0.01-0.99的范围。
7.3 初始权重
由于权重同样是输出结果重要的组成部分并且结果不能过大,那么权重也应该尽量的小,最简单的是将初始权重从-1.0到1.0之间随机取值。但是数学家所得到的经验是,在一个节点传入链接数量平方根倒数的大致范围内随机采样效果最好。也就是如果每个节点具有3条传入链接,那么初始权重取值范围是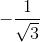
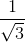
8. 总结
以上就是前馈神经网络的大致框架,我们可以根据不同任务去优化网络,例如:学习因子的大小(















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









