









一、CNN的训练,训练什么?
- 训练样本和类别是确定的。
- 训练的深度(隐藏层的层数)和卷积核(神经元)的数量、卷积核的大小,都是训练前根据经验设定的。
- 只有卷积核的参数是未知的。
二、如何训练?
训练是一种有监督学习。
在CNN开始训练之前,权重值是随机初始化的,此时过滤器并不知道该提取哪些特征值。
随着训练数据的输入,经过前向计算后,损失函数会计算网络输出与真实标签之间的误差,误差反向传播进行权重更新,这就是CNN训练的过程。

当我们生下来的时候,我们的思想是空白的,不知道什么是鸟什么是狗。类似在CNN开始训练之前,权重值也是随机初始化的,过滤器不知道提取哪些特征值。当我们长大一些的时候,父母和老师给我们看不同的图片并且告诉我们这些图片对应的是什么。这种思想或者方法就是给图片打标签,就是CNN训练的过程。
三、梯度下降法
想像你于伸手不见五指的黑夜身处一座地形复杂的山中。你看不清山的全貌,只能根据重力感知立足之处的坡度。如果想要下山,你该怎么做?你根据此处的重力感觉,向下坡最陡的方向迈一步。然后根据新位置的坡度,再向下坡最陡的方向迈出下一步。如果来到一个位置,你感觉已经站在了平地上,再没有下坡的方向,你也就无从迈出下一步了。此时你可能已经成功到达海拔最低的山底,但也有可能身处半山腰处一块平地或者一个盆地底部。
四、CNN反向传播计算过程
- 传统的神经网络是全连接形式的,如果进行反向传播,只需要由下一层对前一层不断的求偏导,即求链式偏导就可以求出每一层的误差项,然后求出权重和偏置项的梯度,即可更新权重。
- 卷积神经网络有两个特殊的层:卷积层和池化层。
- 池化层输出时不需要经过激活函数,是一个滑动窗口的最大值,一个常数,那么它的偏导是1。
- 从卷积后的feature_map反向传播到前一层时,由于前向传播时是通过卷积核做卷积运算得到的feature_map,所以反向传播与传统的也不一样,但同样需要求损失函数对于权值和偏置的梯度,利用梯度和误差项更新卷积核的参数。
五、欠拟合underfitting&过拟合overfitting
通俗对比:
欠拟合学得太少,分得太粗糙;
过拟合学得太多太细,拿着放大镜看世界,看到的都是差异看不到相同点。
六、学习率 learning rate ——权重更新的速度

七、数据归一化
归一化就是把数据经过处理后使之限定在一定的范围内。比如通常限制在区间[0, 1]或者[-1, 1]。本质是一种线性变换。
![]()
归一化解决奇异样本数据问题,奇异样本数据数据指的是相对于其他输入样本特别大或特别小的样本矢量。
归一化的方法:
最大-最小标准化是对原始数据进行线性变换,设minA和maxA分别是属性A的最小值和最大值,将A的一个原始值通过最大-最小标准化映射到区间[0, 1]的值,公式: ![]()
Z-score标准化是基于原始数据的均值和标准差进行的数据标准化。将属性A的原始数据X通过Z-score标准化成。Z-score标准化适用于属性A的最大值或者最小值未知的情况,或有超出取值范围的离散数据的情况,公式: ![]()
八、训练的方法
单样本训练(随机梯度下降SGD):
在标准BP算法中,每输入一个样本,都要回传误差并调整权值,这种对每个样本轮训的方法称为单样本训练。单样本训练只针对每个样本产生的误差进行调整,难免顾此失彼,使训练次数增加,导致收敛速度变慢。内存占用少,振荡、有遗忘问题。
批量训练(批量梯度下降BGD):
在所有样本输入后计算网络的总误差,再根据总误差调整权值,这种累积误差的批量处理方式称为“批训练”或“周期训练”。易于并行训练,样本量大的时候内存占用多,训练速度变慢。
小批量训练:
“小批量梯度下降训练法”是单样本和批量训练的折中办法,每次用小批量样本进行更新学习。

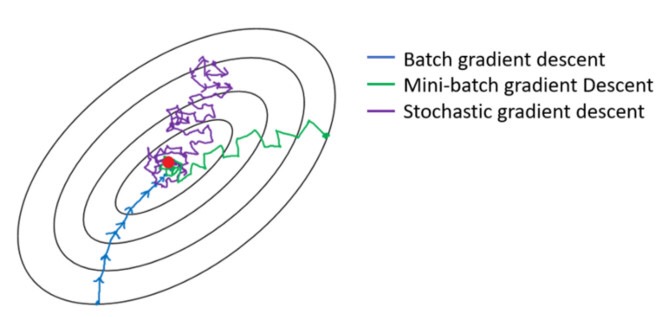
九、三种梯度下降法法的对比:
下图是梯度下降的变种方法以及它们朝向最小值的方向走势,与小批量版本相比,SGD的方向噪声很大。


















 2626
2626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











