








数据集参考论文地址:

目录
暂存队列中的人工校正 (Manual Correction in the Holding Queue)
下载方式:
sklearn.datasets.fetch_rcv1(*, data_home=None, subset='all', download_if_missing=True, random_state=None, shuffle=False, return_X_y=False)| 类数 | 103 |
| 样本数 | 884414 |
| 维度 | 47236 |
Reuters 数据集简介
Reuters 数据集是一个由路透社(Reuters)提供的大型文本分类数据集,广泛用于自然语言处理(NLP)和机器学习领域的研究,尤其是在文本分类和信息检索任务中。
论文摘要
Reuters Corpus Volume I (RCV1) 是由路透社公司最近为研究目的发布的一个包含超过80万个手动分类新闻故事的档案。使用此数据进行文本分类研究需要对数据产生时所面临的现实约束有深入了解。通过与路透社人员的访谈和访问路透社文档,我们描述了用于生成 RCV1 数据的编码政策和质量控制程序、层级分类体系的预期语义以及移除错误数据所需的修正。我们将原始数据称为 RCV1-v1,将修正后的数据称为 RCV1-v2。我们在 RCV1-v2 上基准测试了几种广泛使用的监督学习方法,展示了该数据集的属性,提出了新的研究方向,并为未来的研究提供了基准结果。我们通过在线附录提供了详细的按类别实验结果,以及修正后的类别分配和分类结构。
文本分类简介
文本分类是根据自然语言文本的内容将其自动分配到预定义类别中的过程。它在多个信息处理任务中扮演着支持性技术角色,包括受控词汇索引、新闻及其他文本流的路由与打包、内容过滤(垃圾邮件、色情内容等)、信息安全、帮助台自动化等。与之密切相关的技术还适用于其他文本分类任务,包括根据个性化或新兴类别的分类(如警报系统、话题检测与跟踪)、非内容相关类别的分类(如作者识别、语言识别),以及文本与其他数据的混合分类(如多媒体与跨媒体索引、文本挖掘)。
文本分类在机器学习、信息检索、计算语言学等领域的研究兴趣日益增长。这部分反映了文本分类作为机器学习应用领域的重要性,同时也源于文本分类测试集的可用性。这些测试集是由人工索引员将预定义类别分配给文档所组成的集合。测试集使研究人员能够在不雇佣索引员的情况下测试想法,并(理想情况下)客观地与已发布的研究结果进行比较。
现有的文本分类测试集存在以下一个或多个缺陷:文档数量少、缺少完整的文档文本、类别分配不一致或不完整、文本属性异常和/或可用性有限。这些问题因缺乏有关测试集制作过程及其类别系统性质的文档而加剧。对于有兴趣进行层次化文本分类的研究人员来说,这一问题尤其严重,由于缺乏良好的集合和充分的文档,他们往往被迫自行为类别强加层次结构。
然而,即使当前的集合完美无缺,仍然存在对新数据集的需求。就像机器学习算法可能通过将分类器的参数调优以适应训练集的偶然特性而过拟合一样,研究社区也可能通过改进已经在现有数据集上表现良好的算法而发生过拟合。只有通过定期在新测试集上测试算法,才能验证进展。
Reuters Corpus Volume 1 (RCV1)(Rose、Stevenson 和 Whitehead,2003)有可能解决上述许多问题。它由超过 80 万条新闻wire故事组成,这些故事已经使用三个类别集进行了手动编码。然而,RCV1发布时仅仅是新闻wire故事的集合,而不是一个测试集。它包含了已知的类别分配错误,提供的类别描述列表与分配给文章的类别不一致,并且缺少关于类别分配意图语义的基本文档。
RCV1 数据的编码

RCV1 数据是在路透社有限公司的实际操作环境中生成的,按照当时的操作流程进行处理,这些流程现已被淘汰。最初,这些数据并非为研究用途而设计,因此在研究环境中通常会保留的信息并未被记录下来。特别是,当时 RCV1 数据生成时的编码实践并未留下正式的规范说明。
然而,通过结合相关文档和对路透社工作人员的采访,论文作者相信已基本重建了与文本分类研究相关的编码方面内容。
文档
路透社是全球最大的国际文字和电视新闻机构,其编辑部门每天用23种语言制作约11,000篇报道。这些报道既可以实时发布,也可通过在线数据库和其他存档产品获取。
RCV1 数据集源自这些在线数据库之一,原计划收录的全部内容仅包括路透社记者在 1996 年 8 月 20 日至 1997 年 8 月 19 日期间撰写的英语新闻稿。该数据集存储于两张 CD-ROM 中,并已被格式化为 XML 文件格式。整个归档过程以及随后对 XML 数据集的准备工作涉及大量的内容验证与确认,包括移除虚假或重复文档、规范化发布日期和署名格式、添加版权声明等。
这些报道涵盖了一个大型英语国际新闻通讯社的典型内容,长度从几百字到几千字不等。图 1 显示了一个示例新闻稿(为简洁起见,标记格式有所简化)。
分类
为了方便从数据库产品(例如路透社商业简报,RBB)中检索内容,新闻稿被分配了来自三个类别集合(主题 Topics、行业 Industries 和 地区 Regions)的分类代码。这些代码集合最初是为满足客户对公司和商业信息访问的需求而设计的,主要集中在公司编码及相关主题上。随着 RBB 产品的推出,重点扩展到大型企业、银行、金融服务、咨询公司、市场营销、广告和公关公司的终端用户。
主题代码 (Topic Codes)
主题代码用于标识报道的主要内容,并分为四个层级组织的组别:
- CCAT (公司/工业)
- ECAT (经济)
- GCAT (政府/社会)
- MCAT (市场)
这一代码集合是受控词汇方案如何体现特定数据集视角的典型例子。RCV1 的文章内容范围广泛,但代码集合仅强调对路透社客户而言重要的区分。例如,对于公司所有权变更,有三个不同的主题代码,而整个科学和技术仅用一个类别 (GSCI) 表示。
行业代码 (Industry Codes)
行业代码依据报道中提到的业务类型进行分配。这些代码分为10个子层级,例如:
- I2 (金属与矿产)
- I5 (建筑业)
行业代码是三个代码集合中最为庞大的一个,支持非常精细的分类。
地区代码 (Region Codes)
地区代码包括地理位置和经济/政治分组。然而,这一类别未定义层级分类体系。
编码政策
明确的编码分配政策通常有助于提高编码的一致性和实用性,尽管制定精确的政策具有一定难度(Lancaster, 1998, 第30-32页)。路透社的编码指导中包括以下两个主要政策(为了方便,我们对这些政策进行了命名,尽管路透社并未如此命名):
-
最少编码政策 (Minimum Code Policy)
每篇报道至少需要分配一个主题代码 (Topic Code) 和一个地区代码 (Region Code)。 -
层级政策 (Hierarchy Policy)
在编码过程中,应从主题和行业代码集 (Topic and Industry sets) 中分配最具体且适当的代码,并且(通常通过自动化方式)分配这些代码的所有上级代码。与某些编码系统不同,该政策对同一父类下可分配的代码数量没有限制。
这些政策通过人工和自动化手段结合的方式实施,但实施过程并不完美。
编码过程
在1996至1997年间,作为语料来源的时间段,路透社每年制作了超过80万篇英语新闻稿。编码是一项艰巨的任务。在某个阶段,路透社雇用了90人负责为每年约550万篇英语新闻稿进行编码。然而,这个数字包括了由路透社记者撰写的新闻稿以及来自其他来源的新闻稿,同时还包括了一些不属于RCV1数据的额外编码集。因此,专门用于RCV1所涵盖文档和代码的工作量并不清楚,但一个估计值约为12人年。
路透社制作的新闻稿的编码分为三个阶段:自动编码、人工编辑和人工校正。
自动编码 (Autocoding)
新闻稿首先经过一个基于规则的文本分类系统TIS(主题识别系统, Topic Identification System)的处理。TIS是由Carnegie Group为路透社开发系统的后继版本(Hayes 和 Weinstein, 1990)。大多数代码至少有一条规则用于分配,但某些代码因被认为超出了技术能力范围,未尝试进行自动化分配。两个被认为难以自动分配的代码是GODD(人文兴趣)和GOBIT(讣告)。值得注意的是,在实验中,这两个类别被证明是最难自动分配的类别之一。
进入系统的某些新闻稿已经由记者手动分配了来自不同代码集(称为“编辑代码”)的代码。使用了一些简单的“来源处理”规则,将这些代码映射到最终代码集中的等效代码。例如,带有编辑代码SPO(体育)的新闻稿会被自动分配最终代码GSPO。其他来源处理规则则触发于其他标记部分,例如将“slug”(新闻稿的一行简短标识信息)包含字符串“BC-PRESS DIGEST”的任何新闻稿自动分配到最通用的新闻代码(GCAT)。
此外,如第3节所述,为了执行层级政策或捕捉其他关系,某些主题、行业和地区代码会基于相同或不同类型的其他代码进行分配。
人工编辑 (Manual Editing)
TIS的输出会被自动检查是否符合“最少编码政策”。如果符合,新闻稿会被送到暂存队列;如果不符合,新闻稿会首先被发送给人工编辑。编辑会根据他们认为适用的代码进行分配,同时确保每篇新闻稿至少有一个主题代码和一个地区代码。编辑还可以删除或更改自动分配的代码。在这个阶段,编辑偶尔会修复新闻稿格式中的错误,但他们的主要职责是修正编码问题。编辑后的新闻稿会进入暂存队列,等待最终审查。
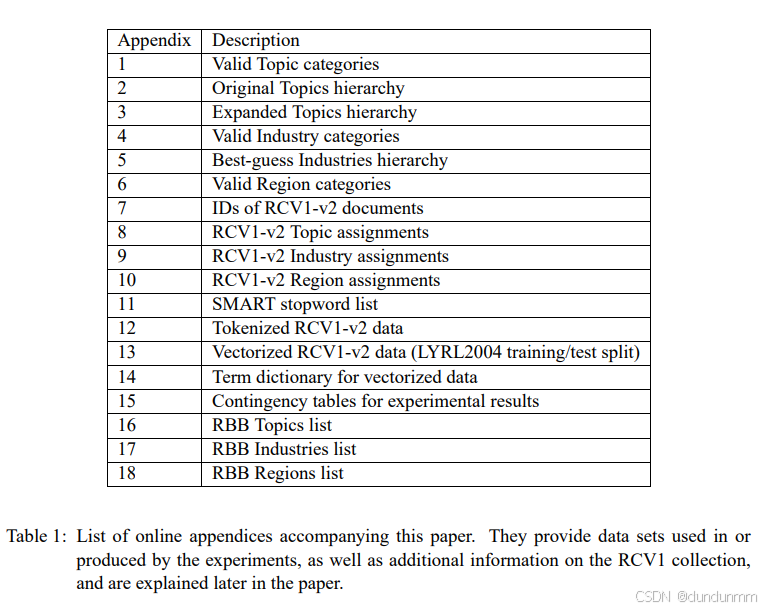
暂存队列中的人工校正 (Manual Correction in the Holding Queue)
每隔六小时,编辑会对暂存队列进行审查,纠正编码中的错误。一旦新闻稿通过暂存队列检查,它们会被打包并按批次加载到数据库中。
编码质量
人工编码不可避免地具有主观性。研究表明,不同数据集的索引员一致性水平可能存在显著差异(Cleverdon, 1991)。上述流程旨在为路透社的编码实现较高的一致性和准确性。定期对新闻稿进行抽样,并向编码员提供改进准确性的反馈。通过样本评估了编码员之间及与标准的一致性,发现一致性水平较高,但我们未能获得可供发表的定量数据。
表2提供了关于编码一致性的一些补充证据。该表展示了1997年期间,有多少新闻稿在自动编码阶段未通过“最少编码测试”并因此进行了人工编辑,以及有多少新闻稿在暂存队列中至少有一个代码被修正。需要注意的是,RCV1语料库包含了部分1996年和1997年的新闻稿,因此语料库中的新闻稿数量与表2中的数量并不相同。
总共有312,140篇新闻稿因自动编码未通过“最少编码测试”而进行了人工编辑。所有这些新闻稿也都经过了暂存队列中第二位编辑的复审,但只有23,289篇(即13.4%)的代码被第二位编辑更改。相比之下,505,720篇自动编码通过“最少编码测试”的新闻稿中,有334,975篇(即66.2%)在暂存队列中被更改。换句话说,经过人工编辑的编码比自动系统分配的编码在暂存队列中被修改的可能性要低得多。
需要注意的是,暂存队列中的编辑可以通过注释得知哪些新闻稿已经过人工编辑,这无疑影响了他们选择修改哪些新闻稿的决定。因此,表2不能被视为索引员一致性的客观衡量标准。然而,它为不同人工编码员对代码意义的大致共识提供了一些补充证据。Rose、Stevenson和Whitehead(2003)还提供了更多关于编辑修正的数据。
路透社编码方式的演变
需要提及的是,上述基于 TIS 和人工修正的编码方法现已在路透社被取代。TIS 的规则驱动方法存在一些缺陷:
- 制定规则需要专业知识,这减缓了新代码的添加以及规则对输入变化的适应速度。
- 规则无法提供输出结果的置信度。这意味着无法将编辑的修正工作聚焦于最不确定的情况,也无法检测(除非违反编码政策)新的新闻类型的出现,这可能表明需要对代码集进行更改或扩展。
目前,路透社已采用基于机器学习的文本分类方法。分类器通过大量训练数据生成,并引入了反馈机制:基于自动编码置信度评分触发人工编辑的参与,同时使用分析工具来指示何时可能需要新的训练数据或类别。
RCV1 与文本分类研究
测试集不仅仅是一个语料库。本节将探讨 RCV1 的生成方式及其特点如何影响其在文本分类研究中的应用。在第 4 节中,我们将描述如何修正原始 RCV1 数据(称为 RCV1-v1)中的错误,以生成用于文本分类测试的集合(称为 RCV1-v2)。因此,本节展示了两个版本数据的统计信息,并指出它们的差异之处。
文档
RCV1 包含的文档数量是流行的 Reuters-21578 集合及其变体(Lewis, 1992, 1997)的 35 倍(RCV1-v1 有 806,791 篇文档,RCV1-v2 有 804,414 篇文档),并且其编码可靠的文档数量是其 60 倍。事实上,目前唯一与之规模相当的公开文本分类测试集合是 OHSUMED(Hersh, Buckley, Leone, and Hickman, 1994; Lewis, Schapire, Callan, and Papka, 1996; Yang and Pedersen, 1997; Yang, 1999),其包含 348,566 篇文档。然而,OHSUMED 存在一些不足:
- 不包含文档的完整文本;
- 其医学语言对非专业人士来说难以理解;
- 其类别层次结构(MeSH)庞大且结构复杂。
RCV1 也比以往的集合更“干净”。每篇新闻独立存储于一个文件中,并拥有唯一的文档 ID。ID 范围为 2286 至 810597(RCV1-v1),以及 2286 至 810596(RCV1-v2)。
原始 RCV1-v1 的 ID 范围中存在间隙,而 RCV1-v2 中由于文档被删除则出现了更多的间隙。遗憾的是,ID 的顺序并不对应于新闻的时间顺序,即使是在日的层面也是如此。不过,文档确实包含时间戳(位于 <newsitem> 元素中),可以通过这些时间戳在日的层面确定时间顺序。由于这些新闻是从档案数据库中提取的,而不是从最初的新闻传输流中获取的,因此时间戳并未精确到某一天中的具体时间。
RCV1 中的文本和元数据采用 XML 格式,这简化了数据的使用。此外,这些新闻来自一个档案数据库,这意味着其中包含较少的简短警报(例如 Reuters-21578 中著名的“blah, blah, blah”新闻)、对之前新闻的更正以及其他异常内容。RCV1 包含了一年时间间隔内某一特定类型的全部或几乎全部新闻内容。对于时间性研究而言,这相比 Reuters-21578(其覆盖时间较短且内容分散)是一个显著的优势。
然而,用于生成档案数据库及后续研究语料库的过程不可避免地存在一些不完美之处。Khmelev 和 Teahan(2003)讨论了语料库中的一些异常,包括约 400 篇外语文档的存在。他们还特别指出了重复文章和近似重复文章的情况。其中一些情况仅反映了非常相似的新闻偶尔出现的事实,特别是包含财务数据的文章。在其他情况下,同一篇新闻的多个草稿被保留下来。此外,也有一些显然属于偶然的错误。
我们发现约有 2,500 到 30,000 篇文档可以被视为其他文档的重复内容,这取决于如何定义重复性。我们的分析与 Teahan 和 Khmelev 的结果一致,他们发现 27,754 篇重复或实质性重叠的文档。
是否认为 RCV1 中的重复文档、外语文档以及其他异常问题会造成困扰,取决于研究者使用 RCV1 研究的具体问题。我们认为,这些问题的数量要么足够少,要么与实际应用环境中的水平相似,因此对于大多数研究目的来说,这些问题是可以忽略的。
机器学习研究在很大程度上依赖于可用的数据集,文本分类的监督学习也不例外。RCV1 有潜力支持在层次分类、学习算法的扩展、低频类别的有效性、采样策略以及其他领域的显著研究进展。截至 2004 年 1 月 5 日,该数据集已经被路透社分发给了 520 个研究小组,这表明它可能会得到广泛应用。
目前这个数据集在文本分析领域确实应用广泛。。。

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









