







pandas.cut() 用于将连续变量分箱(分段),即将数据划分为不同的区间,并对每个数据点进行归类。常用于数据离散化,例如将年龄、价格等连续数据转换为类别变量。
函数语法
pandas.cut(x, bins, right=True, labels=None, retbins=False)
参数说明
-
x:-
需要进行分箱的一维数据(如
Series、NumPy 数组)。
-
-
bins:-
整数:指定分成多少个等宽区间(Pandas 自动计算分界点)。
-
列表或数组:指定手动分隔的区间边界(如
[0, 10, 20, 30])。
-
-
right(默认True):-
True:区间右闭合 ((a, b],即包含右边界b,不包含左边界a)。 -
False:区间左闭合 ([a, b),即包含左边界a,不包含右边界b)。
-
-
labels(默认None):-
None:返回的是区间(如(0, 10])。 -
列表:为每个分箱指定标签(如
['低', '中', '高'])。
-
-
retbins(默认False):-
False:仅返回分类后的数据。 -
True:同时返回实际使用的bins(区间分界点)。
-
示例 1:等宽分箱
import pandas as pd
import numpy as np
data = np.array([1, 7, 5, 11, 13, 21, 25])
bins = 3 # 指定分成3个等宽区间
result = pd.cut(data, bins)
print(result)
输出
[(0.976, 9.333], (0.976, 9.333], (0.976, 9.333], (9.333, 17.667], (9.333, 17.667], (17.667, 26.0], (17.667, 26.0]]
Categories (3, interval[float64, right]): [(0.976, 9.333] < (9.333, 17.667] < (17.667, 26.0]]
解释:
-
bins=3,Pandas 自动计算区间:-
(0.976, 9.333]
-
(9.333, 17.667]
-
(17.667, 26.0]
-
-
每个数据点被归入对应区间。
示例 2:自定义区间
bins = [0, 10, 20, 30] # 手动定义分箱边界
result = pd.cut(data, bins)
print(result)
输出
[(0, 10], (0, 10], (0, 10], (10, 20], (10, 20], (20, 30], (20, 30]]
Categories (3, interval[int64, right]): [(0, 10] < (10, 20] < (20, 30]]
解释:
-
0-10、10-20、20-30 三个区间。
-
结果显示每个数据点被归入哪个区间。
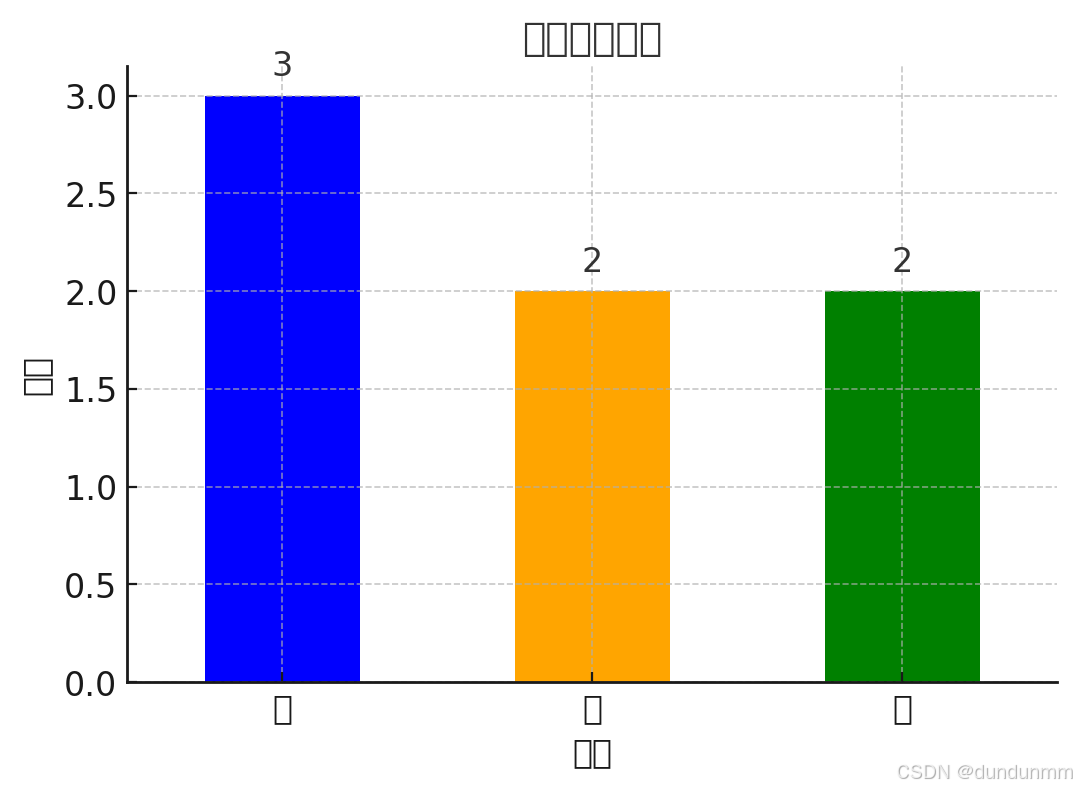
示例 3:自定义区间+标签
labels = ['低', '中', '高']
result = pd.cut(data, bins, labels=labels)
print(result)
输出
['低', '低', '低', '中', '中', '高', '高']
Categories (3, object): ['低' < '中' < '高']
解释:
-
低:0-10
-
中:10-20
-
高:20-30
-
结果以标签返回,而不是数值区间。
示例 4:返回分箱边界
result, bin_edges = pd.cut(data, bins, retbins=True)
print("分箱结果:", result)
print("实际使用的分箱边界:", bin_edges)
输出
分箱结果: [(0, 10], (0, 10], (0, 10], (10, 20], (10, 20], (20, 30], (20, 30]]
Categories (3, interval[int64, right]): [(0, 10] < (10, 20] < (20, 30]]
实际使用的分箱边界: [ 0 10 20 30]
解释:
-
retbins=True会返回实际的分箱边界(如[0, 10, 20, 30])。
总结
| 参数 | 作用 |
|---|---|
x | 需要分箱的数据 |
bins | 分箱个数(整数)或自定义分箱边界(列表) |
right | 是否包含右边界(默认 True) |
labels | 给分箱结果加上自定义标签 |
retbins | 是否返回实际的分箱边界 |
📌 适用场景
-
数据离散化(如把年龄划分为"青年"、"中年"、"老年")。
-
特征工程(如对连续变量进行分箱,提高模型稳定性)。
-
数据可视化(如将数据分类后统计频次)。

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









