




 报告介绍了大数据时代下智能人才计算的重要性和挑战,包括招聘助手的规范化、智能人岗匹配的精准性与可解释性,以及高潜力人才预测。通过数据挖掘和深度学习技术,解决人才招聘和管理中的低效、主观性问题,提升人才服务的质量和效率。
报告介绍了大数据时代下智能人才计算的重要性和挑战,包括招聘助手的规范化、智能人岗匹配的精准性与可解释性,以及高潜力人才预测。通过数据挖掘和深度学习技术,解决人才招聘和管理中的低效、主观性问题,提升人才服务的质量和效率。

不到现场,照样看最干货的学术报告!
嗨,大家好。这里是学术报告专栏,读芯术小编不定期挑选并亲自跑会,为大家奉献科技领域最优秀的学术报告,为同学们记录报告干货,并想方设法搞到一手的PPT和现场视频——足够干货,足够新鲜!话不多说,快快看过来,希望这些优秀的青年学者、专家杰青的学术报告 ,能让您在业余时间的知识阅读更有价值。
人工智能论坛如今浩如烟海,有硬货、有干货的讲座却百里挑一。“AI未来说·青年学术论坛”系列讲座由中国科学院大学主办,百度全力支持,读芯术、paperweekly作为合作自媒体。承办单位为中国科学院大学学生会,协办单位为中国科学院计算所研究生会、网络中心研究生会、人工智能学院学生会、化学工程学院学生会、公共政策与管理学院学生会、微电子学院学生会。2020年5月30日,第15期“AI未来说·青年学术论坛”大数据线上专场论坛以“线上平台直播+微信社群图文直播”形式举行。中科大徐童带来报告《AI×Talent数据驱动的智能人才计算》。
中科大徐童的报告视频
徐童,中国科学技术大学副教授、硕士生导师。中国中文信息学会青年工作委员会委员、中国中文信息学会社会媒体处理专委会委员。主要研究方向为数据挖掘与社会媒体分析,近年来,在IEEE TKDE、IEEE TMC、IEEETMM、ACM TOIS等相关领域重要期刊,及KDD、WWW、SIGIR、AAAI等重要学术会议发表论文50余篇。受邀担任第11届IEEE国际知识图谱会议(ICKG 2020)、2018全国知识图谱与语义计算大会(CCKS 2018)、第九届全国社会媒体处理大会(SMP 2020)等会议领域/专题主席,及KDD、AAAI、SDM、EMNLP等重要国际会议程序委员会委员。
报告内容:大数据时代的来临为传统的人才管理战略带来了冲击,其低效率、主观化、缺乏可预测性的问题日益凸显。与此同时,数据科学的发展,也为破解这一困境提供了新的思路与手段。在本次报告中,我们将简要回顾智能人才分析方面的若干成果,即运用数据挖掘技术,揭示海量人才管理相关数据中潜藏的规律,并解决与人才招聘相关的岗位匹配、发展预测等一系列难题。

AI×Talent数据驱动的智能人才计算

徐童老师首先从招聘引出智能人才计算这个话题。企业现行招聘或者管理模式存在不少问题,我们开展智能人才计算研究本质上希望能够通过大数据或人工智能等技术,来帮助企业建立更加高效、更加公平的企业招聘或管理模式。
企业想招到优秀的人,也希望招聘到合适的人,这是企业在招聘过程中关注的问题,那么怎样从数据挖掘或者机器学习视角看待人才计算这个问题呢?(1)可以把它归纳为分类问题,这个员工适合不适合或者能不能满足企业需要;(2)可以转化成排序问题,当前候选人在所有候选人中间到底排到什么样的名次;(3)企业还希望能够看到这个员工在未来具有怎么样的发展前景。
面临这三个问题,通过大量人力资源管理实践和统计数据可以看到,传统人才招聘和管理模式实际运行起来非常低效且代价昂贵。比如说通过前两年美国招聘统计数据,无论是在金钱还是时间开支上,都远远超出人们想象,而且大量珍贵的在招聘过程中产生数据仍然处于沉睡状态。
这个问题发生根本原因是现有人才管理模式主要依赖于人工操作,由于人力没有办法充分消化和吸收这些问题和数据,很多高价值的规律并没有被充分挖掘,徐老师认为解决这个问题或者突破当前人力管理模式困境最本质解决方案是尝试用大数据方法、大数据技术代替人力去处理这些记录,从而获得更加高效的结果。
大数据是双刃剑,一方面意味着有很多新的机遇、新的价值等待我们去挖掘;另一方面意味着很多新的挑战。就以招聘简历为例,第一个挑战是简历的大批量和同质化,具体体现在同时拿到手多份简历其实十分相似,同质化的简历很难做一个合理区分,不容易找到企业想要的人。

第二个问题是简历的个性化表述,同样一件事情在不同人描述用词和表达语句完全不一样,这是自然语言处理的挑战;除此之外,在管理者或者招聘者这一方,由于招聘者主观性干扰,可能使相似求职者简历或者资历得到不同的评价,在这样的情况下很难获得一些相对比较精准的结果。
围绕着这些问题,中科大研究团队与百度人才智库(TIC)团队合作开展了三项工作,分别是智能招聘助手,岗位分配过程中智能人岗匹配,以及在人才管理中高潜力人才预测,徐老师也希望通过这三项任务介绍怎样通过海量人才大数据来为企业提供智能服务,帮助他们管理人才相关业务全链条。

一、智能招聘助手
智能招聘助手的核心目标在于帮助企业实现招聘环节的规范化,保障效率和公平。效率很好理解,用算法代替人,一般效率都会提升,但公平又受什么因素影响呢?招聘者各种主观因素,比如技术背景、学术观点、个人性格等等各方面都有可能对于评估结果产生影响。
下图所示这个例子,这个侯选者熟练掌握python和deep learning,很显然给他出相应试题的时候,肯定会与python和deep learning相关。其次,还要考虑应试者的拓展能力,即要考虑这个员工进入公司之后所承担岗位是否需要他具备其他技能。还是以候选人A为例,这样一个具有深度学习技能的候选人,他进入公司之后很可能从事和数据分析相关的工作,一个数据分析师可能还需要掌握大规模数据处理、数据可视化相关技能,所以在给他出题目的时候,有可能涉及类似于并行计算相关技能。这要求我们不仅要挖掘现有简历,还需要去对简历进行进一步拓展,提供关联考点。

我们可以通过建立技能图谱,把技能全部关联起来,最终实现个性化的试题推荐。首先要做的是提取,从海量个性化简历中抽取技能实体。值得注意的是,从简历中提取实体的过程会受到很多干扰,其中一个很大干扰是实体分类的效果往往不是很好,以至于最后提取实体有大量内容不是技能,这时候需要对实体进行进一步降噪。
降噪的思路是可以尝试用大规模查询日志通过标签传播方法实现,我们知道表达技能实体往往出现在一些特定的网站上,比如学术相关网站或者技术社区,而非技能实体出现的地方就广了。如果设计一个二部图,把查询和点击记录对应起来,通过标签传播方式把少量高质量技能实体所对应标签传播到其他技能实体上,在这个过程中把非技能实体扔掉,最终构造出技能的知识图谱,基于这样一个图谱可以通过技能关联实现有效的试题个性化推荐。
二、智能人岗匹配
智能人岗匹配的具体目标是要把每个人分配到合适岗位上。其实现有人岗匹配技术相对来说是一个比较粗糙的技术,当候选人规模不大或时间充足时,匹配的精度才可能相对精细一点。
如果候选人数多,实际上很多时候只能依赖非常简单的规则,所以公司一年半年内有非常高的转岗率或离职率,这就是糟糕的岗位分配导致的。
在人岗匹配过程中算法能做什么呢?其实主要是如何破解匹配过程中低效率或者主观性的问题,既然要实现合理、有效的分配,这个匹配就必须要做到有可解释性,你要能够为你的分配结果提供足够有说服力的依据。同时要知道人的简历和被提供的岗位描述都是自然语言,是大段文本,所以还需要对文本进行有效表征,从而使文本能够做到双向匹配,而不是单纯做简单关键字匹配。
除此之外,无论是简历也好还是工作描述也好,其实这些文字都具有多面性。比如说下面这个例子,上面一半是一个公司提供岗位描述,这个里面,四条描述对应到四个方面技能需求,前三条是技术相关的,分别涉及程序语言、机器学习和大规模数据处理,最后一条是综合性的素质要求,要求人们有很好沟通和团队合作能力。下面是两位候选人提供的简历,这时候我们会发现一方面每个人的简历也是有多样性的,它也会覆盖到不同的方面;另一方面,每个人对于工作需要、工作需求覆盖面不一样,他可能覆盖是不同的点,在这种情况下假如每个人对于岗位需求覆盖不一样,怎么做到合理的赋值权重,判断究竟谁匹配得更好呢?

基于这样的需求,自然而然我们想到要用深度学习的方法,它可以做到以下两点,第一实现语义表征,既然简历和岗位需求都是文本,直接把这两部分全部做语义表征,映射到一个空间里,通过一个空间实现两方面的可比。第二部分给这两部分加额外注意力机制,作用在可解释性,可以衡量不同技能或者不同经历在不同条件下对于匹配过程贡献度到底是什么样子。在这里提出了两个层次的注意力,第一是在单个技能或者需求上,我们需要判断当每个人的技能存在或多或少差异情况下,究竟每一条技能对于匹配过程贡献度有多大,这是技能层次一个权重。第二是当涉及多条经历或者多条需求的时候,比如说同学会在简历写从大学到研究生各种各样的学习经历,可能个别同学还会有若干条工作或者实习经历,这么多条经历排下来,到底哪一条经历是我最看重的,这时候也需要注意力机制加以区分和判别的。
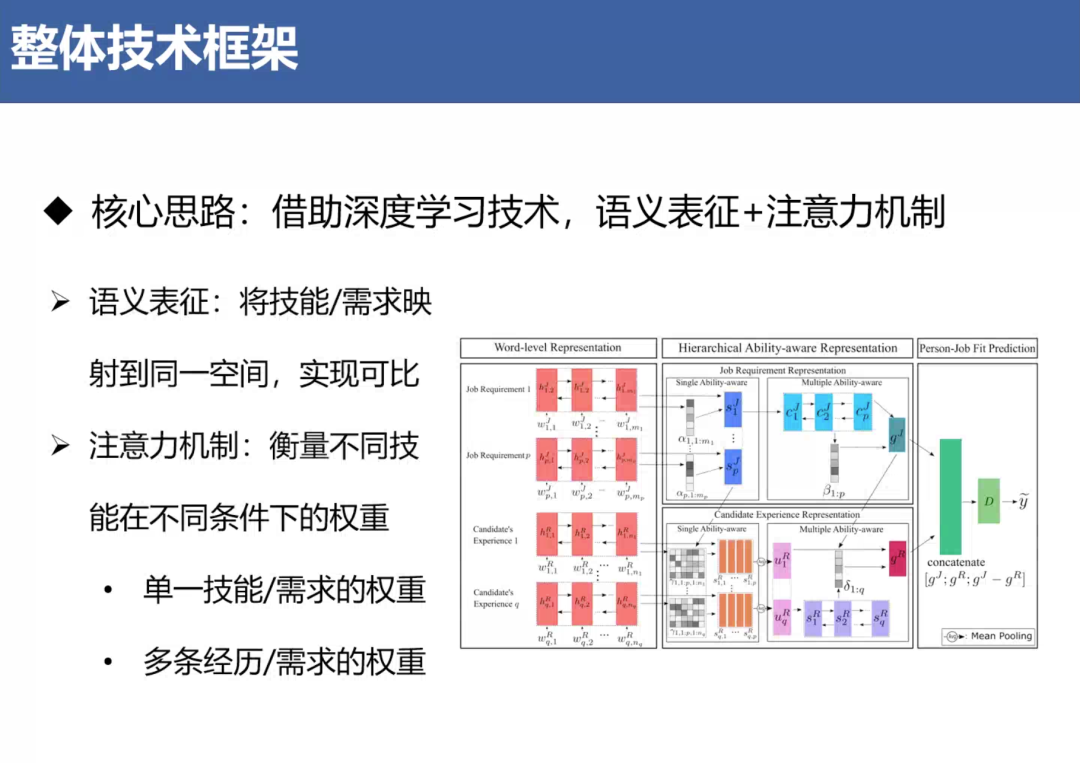
通过这些所有方法组合在一块,最后能够实现对于人岗匹配过程量化、精确、可解释的说明。其实对于不同技能而言,有时候人们会在技能前面加上一些程度描述词,这种情况下一般来说应聘者所精通的技能在匹配过程中相对贡献会更高。

三、尝试预测高潜力人才
尝试预测高潜力人才是指HR专家需要最短时间里从新员工中间判断究竟哪些人是比较有发展前途的,他们需
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









