






一文搞懂深度学习中的感受野(receptive field)
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by).
—— A guide to receptive field arithmetic for Convolutional Neural Networks
1. 概念
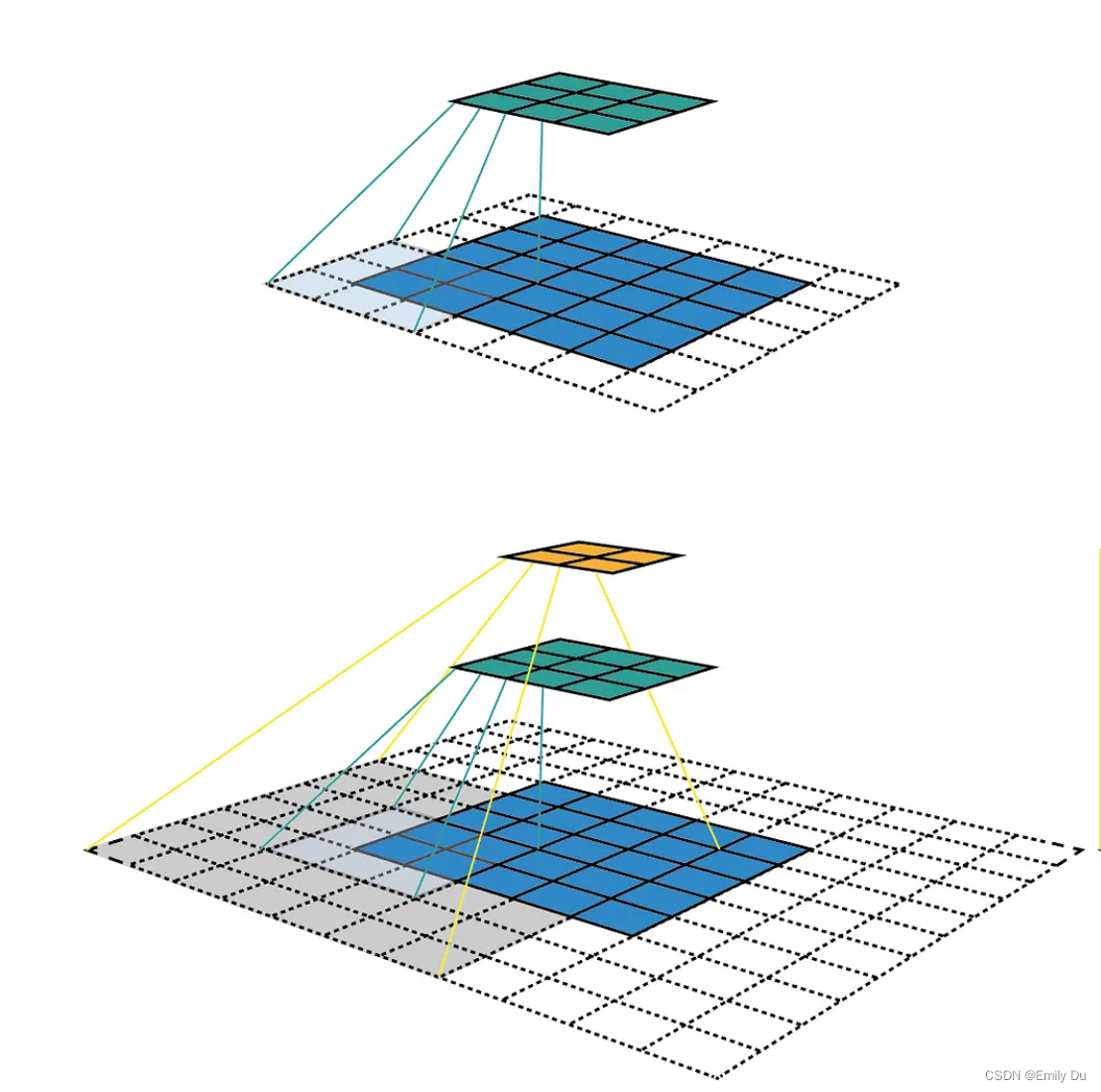
感受野(receptive field)是深度学习中一个特别重要的概念,是指经过卷积操作后的特征图对应到输入图像的区域。如图所示,蓝色区域为输入的图像,经过33卷积,stride为1,padding为1,后得到 33的绿色区域(计算公式为

(out = in - kernel_size + 2padding)/ stride + 1 ),再经过33的卷积(stride 为1,padding 为1)后,得到橙色的22区域,那么对于橙色特征图的其中一个特征,其对应到输入图像的感受野就是55。
2. 推算
为了更清楚的解释感受野,下面对图像进行编码,图像是由一个一个的像素组成,如下图
接下来我们使用一种并不常见的方式来展示CNN的层与层之间的关系(如下图,请将脑袋向左倒45°观看>_<),并且配上我们对原图像的编号。
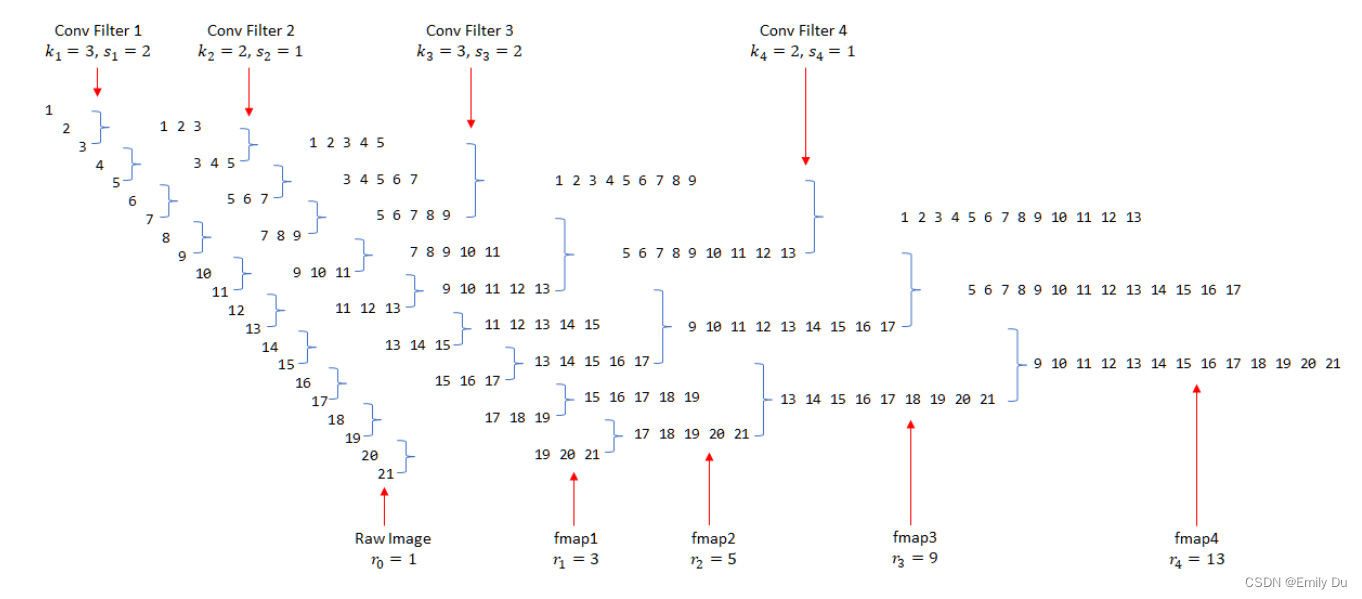
图中黑色的数字表示原图像,蓝色表示卷积操作。用
r
n
{r}_n
rn来表示第
n
{n}
n个卷积层中,每个单元的感受野(即数字序列的长度);用
k
n
{k}_n
kn 和
s
n
{s}_n
sn分别表示第
n
{n}
n个卷积层的kernel_size和stride。序列[1 2 3]表示fmap1的第一个单元能看见原图像中的1,2,3这三个像素,而第二个单元则能看见3,4,5。这两个单元随后又被kernel_size=2,stride 1的Filter 2进行卷积,因而得到的fmap2的第一个单元能够看见原图像中的1,2,3,4,5共5个像素(即取[1 2 3]和[3 4 5]的并集)。
接下来我们尝试一下如何用公式来表述上述过程。可以看到,[1 2 3]和[3 4 5]之间因为Filter 1的stride 2而错开(偏移)了两位,而3是重叠的。对于卷积两个感受野为3的上层单元,下一层最大能获得的感受野为 3 + 2 * 1 = 5 。
r
2
{r}_2
r2 =
r
1
{r}_1
r1 + (
k
2
−
1
)
{k}_2 - 1)
k2−1) *
s
1
{s}_1
s1
继续往下一层看,我们会发现[1 2 3 4 5]和[3 4 5 6 7]的偏移量仍为2,并不简单地等于上一层的
,这是因为之前的stride对后续层的影响是永久性的,而且是累积相乘的关系(例如,在fmap3中,偏移量已经累积到4了),也就是说
r
3
{r}_3
r3 =
r
2
{r}_2
r2 + (
k
3
−
1
{k}_3 -1
k3−1 ) *
s
2
{s}_2
s2 *
s
1
{s}_1
s1,
以此类推,
r
4
{r}_4
r4 =
r
3
{r}_3
r3 + (
k
4
−
1
{k}_4 -1
k4−1 ) *
s
3
{s}_3
s3 *
s
2
{s}_2
s2 *
s
1
{s}_1
s1
得出递推公式
r
n
{r}_n
rn =
r
n
−
1
{r}_{n-1}
rn−1 + (
k
n
−
1
{k}_n -1
kn−1 ) *
∏
i
=
1
n
−
1
s
i
{\prod_{i=1}^{n-1} s_i}
∏i=1n−1si
3. 补充

4.代码
接下来,给出代码
computeReceptiveField.py
# [filter size, stride, padding]
#Assume the two dimensions are the same
#Each kernel requires the following parameters:
# - k_i: kernel size
# - s_i: stride
# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
#
#Each layer i requires the following parameters to be fully represented:
# - n_i: number of feature (data layer has n_1 = imagesize )
# - j_i: distance (projected to image pixel distance) between center of two adjacent features
# - r_i: receptive field of a feature in layer i
# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)
import math
convnet = [[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0],[6,1,0], [1, 1, 0]]
layer_names = ['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5','fc6-conv', 'fc7-conv']
imsize = 227
def outFromIn(conv, layerIn):
n_in = layerIn[0]
j_in = layerIn[1]
r_in = layerIn[2]
start_in = layerIn[3]
k = conv[0]
s = conv[1]
p = conv[2]
n_out = math.floor((n_in - k + 2*p)/s) + 1
actualP = (n_out-1)*s - n_in + k
pR = math.ceil(actualP/2)
pL = math.floor(actualP/2)
j_out = j_in * s
r_out = r_in + (k - 1)*j_in
start_out = start_in + ((k-1)/2 - pL)*j_in
return n_out, j_out, r_out, start_out
def printLayer(layer, layer_name):
print(layer_name + ":")
print("\t n features: %s \n \t jump: %s \n \t receptive size: %s \t start: %s " % (layer[0], layer[1], layer[2], layer[3]))
layerInfos = []
if __name__ == '__main__':
#first layer is the data layer (image) with n_0 = image size; j_0 = 1; r_0 = 1; and start_0 = 0.5
print ("-------Net summary------")
currentLayer = [imsize, 1, 1, 0.5]
printLayer(currentLayer, "input image")
for i in range(len(convnet)):
currentLayer = outFromIn(convnet[i], currentLayer)
layerInfos.append(currentLayer)
printLayer(currentLayer, layer_names[i])
print ("------------------------")
layer_name = raw_input ("Layer name where the feature in: ")
layer_idx = layer_names.index(layer_name)
idx_x = int(raw_input ("index of the feature in x dimension (from 0)"))
idx_y = int(raw_input ("index of the feature in y dimension (from 0)"))
n = layerInfos[layer_idx][0]
j = layerInfos[layer_idx][1]
r = layerInfos[layer_idx][2]
start = layerInfos[layer_idx][3]
assert(idx_x < n)
assert(idx_y < n)
print ("receptive field: (%s, %s)" % (r, r))
print ("center: (%s, %s)" % (start+idx_x*j, start+idx_y*j))
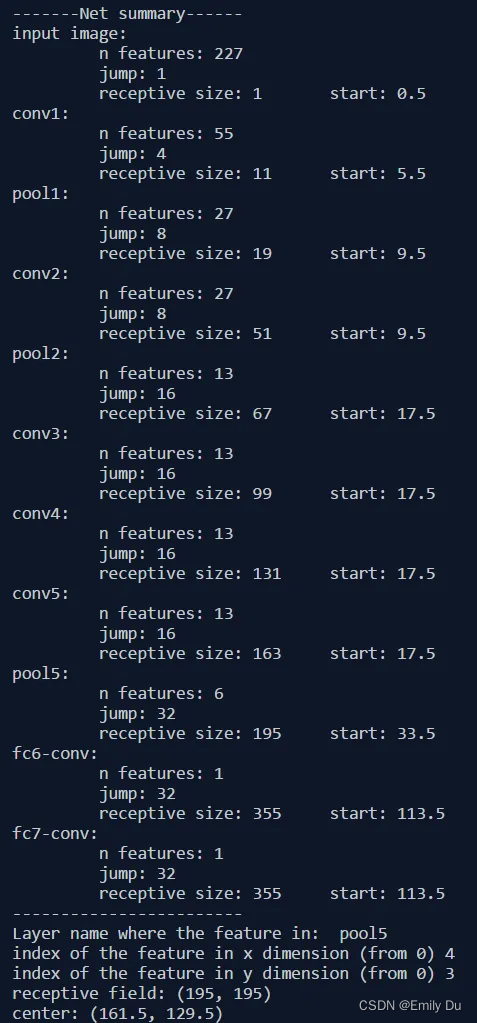
5.例子
AlexNet的例子
参考文献:
【1】A guide to receptive field arithmetic for Convolutional Neural Networks
【2】深度神经网络中的感受野(Receptive Field)
【3】彻底搞懂感受野的含义与计算
【4】computeReceptiveField.py















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









