







前言
本文详细介绍一下milvus的数据插入,索引构建和数据查询的实现细节
数据插入
在milvus里面,我们可以对每个集合设置多个分片(shard),每个分片都有对应的虚拟通道(vchannel).从下面的图中我们可以看到,milvus给日志代理的每个vchannel都分配了一个物理channel(pchannel)。每个进来的插入/删除请求通过主键的哈希值被路由到对应的分片。
因为milvus没有复杂的事务能力,所以DML请求的有效性验证被前移到了代理。代理需要为每个插入/删除请求从TSO(timestamp oracle)获取一个时间戳,它是与根协调器共存的定时模块.时间戳将会决定数据请求的有序处理,旧的时间戳数据会被新的重写。代理从数据协调者批量检索信息,包括实体的分段和主键,以提高整体吞吐量并避免中心节点负担过重。
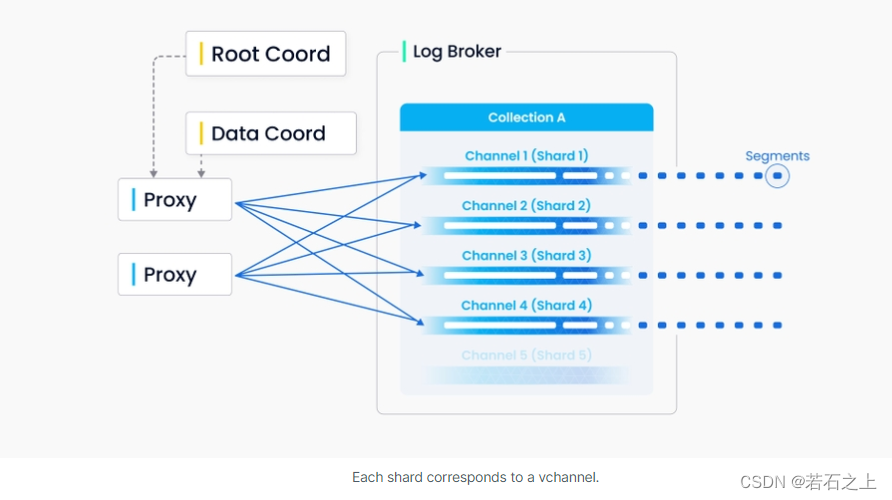
DML操作和DDL操作都会被写入日志序列,只是因为DDL操作是低频发生的,所以它仅仅被分配到一个channel里面。
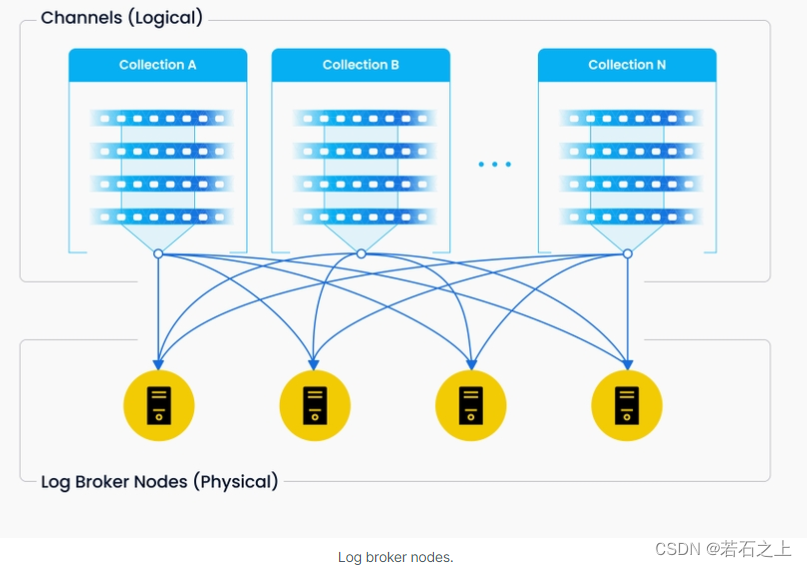
Vchannel维护在底层日志代理节点中。每个channel都是物理隔离的,并且只能被一个节点使用。当数据摄入速率达到瓶颈时,考虑两个事情:日志代理节点是否过载了并需要扩容,是否有足够的分片来为每个节点做负载均衡。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









