







特征缩放(Feature Scaling)
特征量纲差异的影响
举例(房价数据):
根据房屋尺寸
x
1
(
f
e
e
t
2
)
x_{1}(feet^2)
x1(feet2)的数据范围分别为300~2000,和房间数量
x
2
(
个
)
x_{2}(个)
x2(个)的数据范围分别为0~5,预测房屋价格
y
(
p
r
i
c
e
)
y(price)
y(price)。如一条房屋数据为
x
1
=
2000
,
x
2
=
5
,
p
r
i
c
e
=
500
k
x_{1}=2000,x_{2}=5,price = 500k
x1=2000,x2=5,price=500k。
较好的线性回归拟合模型为
p
r
i
c
e
(
500
k
)
=
0.1
∗
2000
+
50
∗
5
+
50
price(500k)=0.1*2000+50*5+50
price(500k)=0.1∗2000+50∗5+50,这里
w
1
=
0.1
,
w
2
=
50
w_{1}=0.1,w_{2}=50
w1=0.1,w2=50。

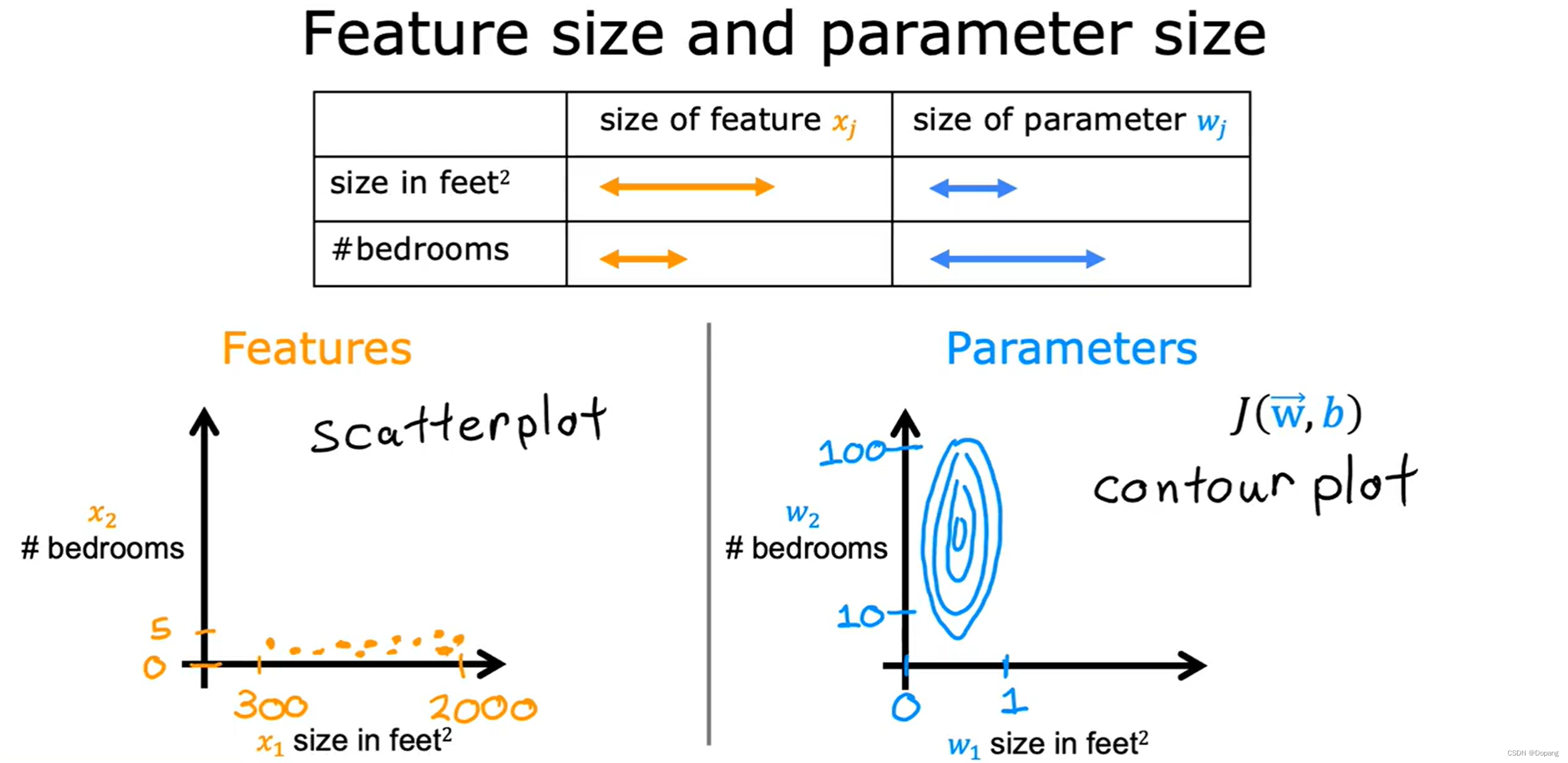
下图展示了不同的特征数据范围对应的模型参数范围,数据范围越大对应的参数范围就越小,数据范围越小对应的参数范围就越大。(这也是为什么不进行特征缩放的模型参数无法反映该特征的重要性)。
直观理解:
房屋尺寸由于数据大,所以它比较小的变动就会对结果产生影响,对应参数范围变动就要小;
房间数由于数据小,所以它需要比较大的变动才能对结果产生影响,对应的参数范围变动就要大。
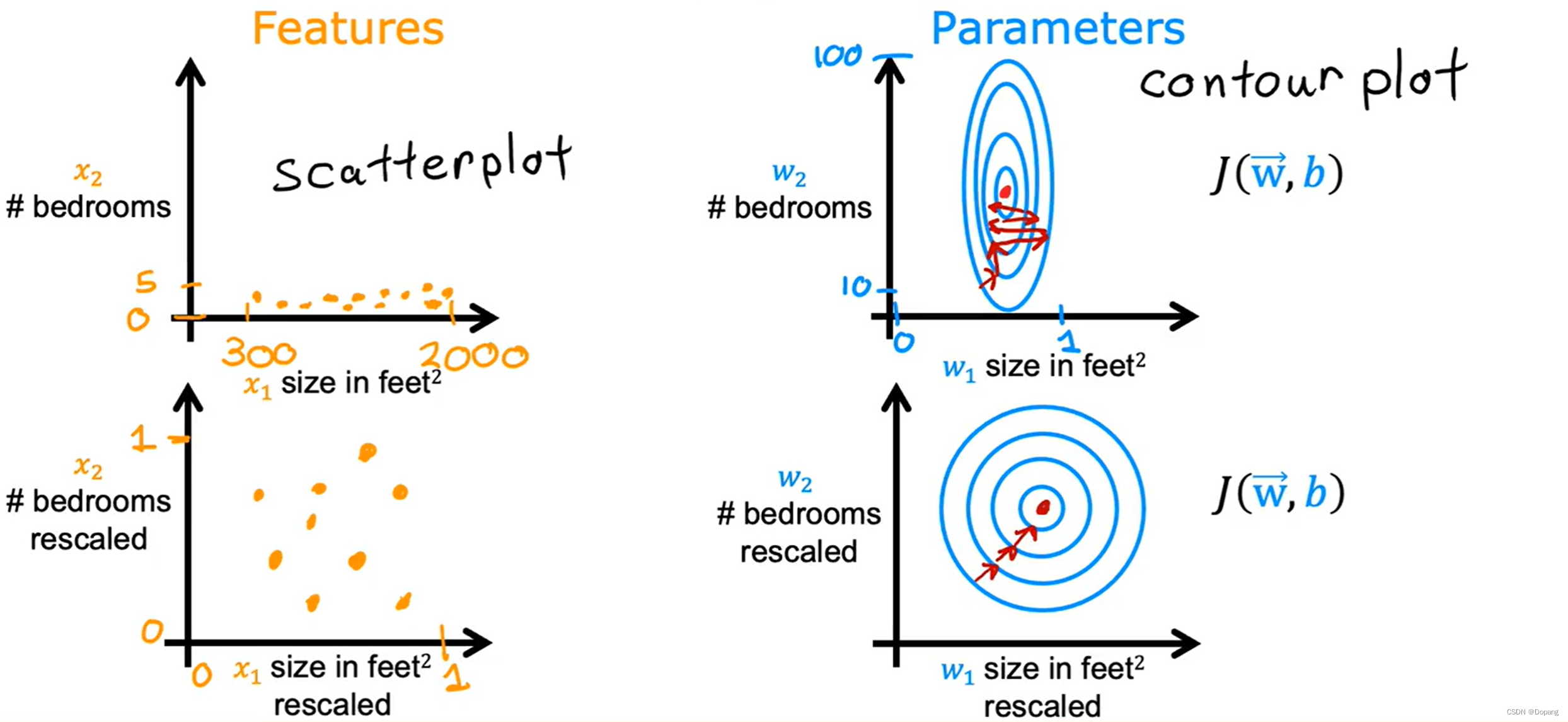
下图展示了如果不进行特征缩放,梯度下降算法会反复横跳。
原因:特征间的数据差距太大,根据偏导数公式
∂
J
(
w
⃗
,
b
)
∂
w
j
=
1
m
∑
i
=
1
m
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\frac{\partial J(\vec{w},b)}{\partial w_{j}}=\frac{1}{m}\sum_{i=1}^{m}({\color{red} f_{\vec{w},b}(\vec{x}^{(i)})} -y^{(i)})x_{j}^{(i)}
∂wj∂J(w,b)=m1∑i=1m(fw,b(x(i))−y(i))xj(i),当学习率
α
\alpha
α确定时,数据范围
x
j
x_{j}
xj大的特征对应参数
w
j
w_{j}
wj更新幅度就大,导致整体方向会偏向更新幅度大的偏导数方向,并不是指向最小值的方向,所以会反复横跳,导致收敛速度会慢。当进行特征缩放时,各个特征量纲一致,计算的偏导数方向基本比较稳定(始终指向最小值),就能比较快的到达最优点。
特征缩放的方法
- 最大值标准化
如: 300 ≤ x 1 ≤ 2000 , 0 ≤ x 2 ≤ 5 300\le x_{1}\le2000, 0\le x_{2}\le5 300≤x1≤2000,0≤x2≤5
则: x 1 , s c a l e d = x 1 2000 , x 2 , s c a l e d = x 2 5 x_{1,scaled}=\frac{x_{1}}{2000},x_{2,scaled}=\frac{x_{2}}{5} x1,scaled=2000x1,x2,scaled=5x2
得: 0.15 ≤ x 1 , s c a l e d ≤ 1 , 0 ≤ x 2 , s c a l e d ≤ 1 0.15\le x_{1,scaled}\le1,0\le x_{2,scaled}\le1 0.15≤x1,scaled≤1,0≤x2,scaled≤1 - 均值标准化
如: 300 ≤ x 1 ≤ 2000 , μ 1 = 600 ; 0 ≤ x 2 ≤ 5 , μ 2 = 2.3 300\le x_{1}\le2000,\mu_1=600;0\le x_{2}\le5,\mu_2=2.3 300≤x1≤2000,μ1=600;0≤x2≤5,μ2=2.3
则: x 1 , s c a l e d = x 1 − μ 1 2000 − 300 , x 2 , s c a l e d = x 2 − μ 2 5 − 0 x_{1,scaled}=\frac{x_{1}-\mu_{1}}{2000-300},x_{2,scaled}=\frac{x_{2}-\mu_{2}}{5-0} x1,scaled=2000−300x1−μ1,x2,scaled=5−0x2−μ2
得: − 0.18 ≤ x 1 , s c a l e d ≤ 0.82 , − 0.46 ≤ x 2 , s c a l e d ≤ 0.54 -0.18\le x_{1,scaled}\le0.82,-0.46\le x_{2,scaled}\le0.54 −0.18≤x1,scaled≤0.82,−0.46≤x2,scaled≤0.54 - Z-score标准化
如: 300 ≤ x 1 ≤ 2000 , μ 1 = 600 , σ 1 = 450 ; 0 ≤ x 2 ≤ 5 , μ 2 = 2.3 , σ 2 = 1.4 , 300\le x_{1}\le2000,\mu_1=600,\sigma_1=450; 0\le x_{2}\le5,\mu_2=2.3,\sigma_2=1.4, 300≤x1≤2000,μ1=600,σ1=450;0≤x2≤5,μ2=2.3,σ2=1.4,
则: x 1 , s c a l e d = x 1 − μ 1 σ 1 , x 2 , s c a l e d = x 2 − μ 2 σ 2 x_{1,scaled}=\frac{x_{1}-\mu_{1}}{\sigma_1},x_{2,scaled}=\frac{x_{2}-\mu_{2}}{\sigma_2} x1,scaled=σ1x1−μ1,x2,scaled=σ2x2−μ2
得: − 0.67 ≤ x 1 , s c a l e d ≤ 3.1 , − 1.6 ≤ x 2 , s c a l e d ≤ 1.9 -0.67\le x_{1,scaled}\le3.1,-1.6\le x_{2,scaled}\le1.9 −0.67≤x1,scaled≤3.1,−1.6≤x2,scaled≤1.9

最大值标准化 |

均值标准化 |

Z-score标准化 |

判断是否标准化 |
判断梯度下降算法是否收敛(Convergence)
一般有两种方法判断:
- 看迭代图,下面左图中红色部分就是收敛了(推荐这种,比较直观且容易发现错误)
- 设置一个阈值 ε \varepsilon ε,当每次迭代后 J J J的减少值小于 ε \varepsilon ε,就说是收敛了(通常情况下 ε \varepsilon ε比较难以确定)
注:当使用批梯度下降算法(batch gradient descent)发现每次迭代
J
J
J有增大情况,则查看是否代码错误或学习率
α
\alpha
α是否设置得当,因为
J
J
J每次迭代应该减少。

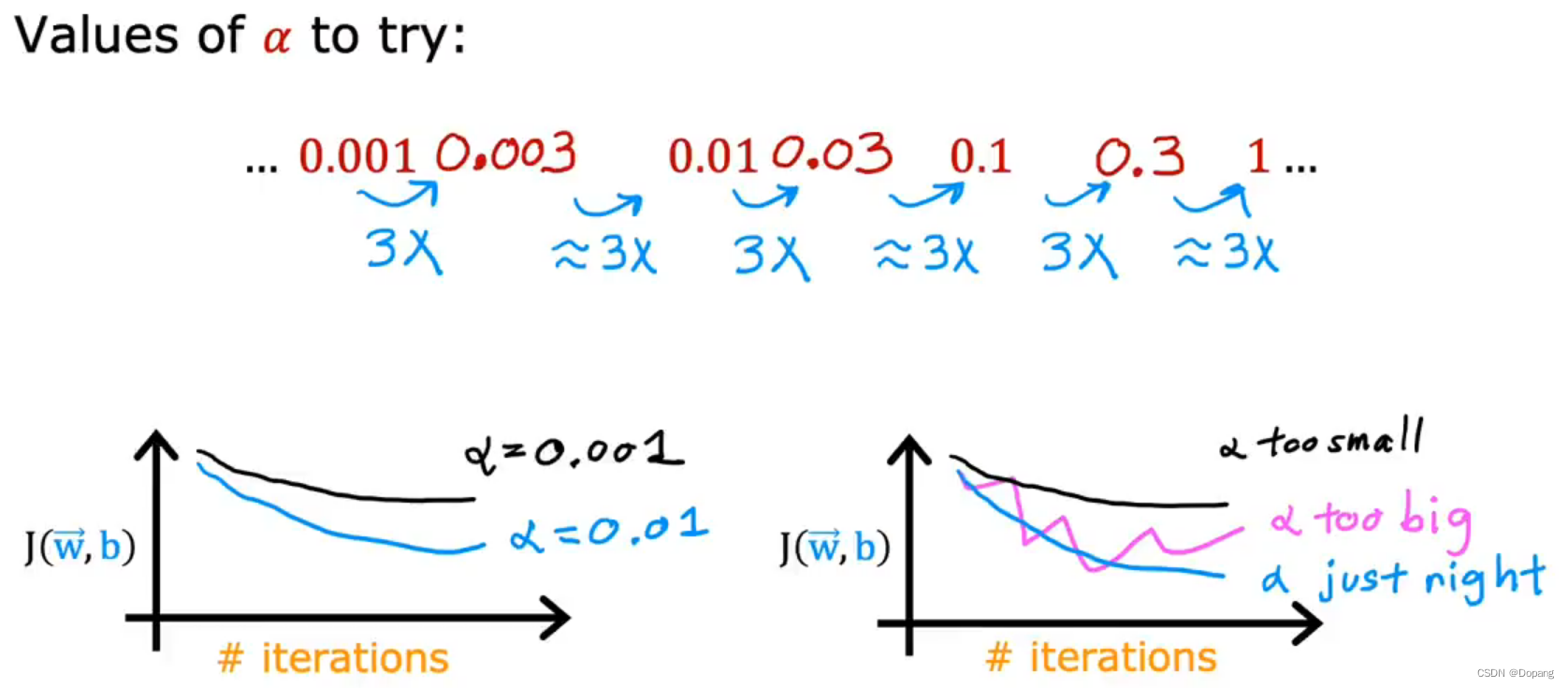
如何设置学习率(Learning Rate)
当设置一个很小的学习率
α
\alpha
α时,梯度下降算法理论上每次迭代都会使代价函数
J
J
J变小,如果没有变小的话就看是否代码有误。但当学习率
α
\alpha
α很小时算法的收敛速度会变慢。所以我们可以多次尝试选择合适学习率
α
\alpha
α,如先设置
α
=
0.001
\alpha=0.001
α=0.001,然后每次乘以3,得到
0.003
,
0.01
,
0.03
,
0.1
,
0.3
,
1
0.003, 0.01, 0.03, 0.1,0.3,1
0.003,0.01,0.03,0.1,0.3,1,观察不同学习率下的收敛情况然后选择合适的学习率
α
\alpha
α。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









