






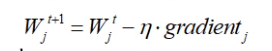

1.学习率η设置大那么,Wj每次调整的幅度就大。
2.设置小的话,那么Wj就调整小,那么如果η设置的小,那就需要更多的迭代次数才能走到最低点
3.η设置的大容易一下跨到最低点的另一侧,然后来回震荡。(当然也是可行的,最终也能够收敛)
4.η设置的太大,数据有可能就不收敛。
5.所以学习率不能设置太大,也不能设置太小。
6.一般我们会设置一个固定的值,0.1,0.001,0.0001等等,然后设置一个机制随着迭代次数增加学习率逐渐变小。
深度学习的优化算法会自己控制这个值。
1.学习率η设置大那么,Wj每次调整的幅度就大。
2.设置小的话,那么Wj就调整小,那么如果η设置的小,那就需要更多的迭代次数才能走到最低点
3.η设置的大容易一下跨到最低点的另一侧,然后来回震荡。(当然也是可行的,最终也能够收敛)
4.η设置的太大,数据有可能就不收敛。
5.所以学习率不能设置太大,也不能设置太小。
6.一般我们会设置一个固定的值,0.1,0.001,0.0001等等,然后设置一个机制随着迭代次数增加学习率逐渐变小。
深度学习的优化算法会自己控制这个值。
 8466
590
8466
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























