







Tele-FLM(又名 FLM-2),是北京智源人工智能研究院和中国电信人工智能研究院(TeleAI)联合研发的全球首个低碳、高性能的开源多语言大模型,4月27日在中关村论坛年会未来人工智能先锋论坛上正式发布。
FLM 系列大模型解决了大模型超参敏感、成本极高的关键问题,实现大模型训练零调整,是全球首个实现了低碳预训练的大模型。
Tele-FLM 在基础模型评测中取得了领先的效果,BPB loss 指标在英文上优于Llama2-70B和 Llama3-8B,在中文上优于Qwen1.5-72B;对话模型 Tele-FLM-Chat 性能已经超过GPT-3.5。
为促进大模型社区的发展,Tele-FLM 的模型权重、核心技术和训练细节等已全面开源。
-
能力比肩Llama2-70B 和 GPT-3.5
语言模型的能力需要通过多种不同维度进行评价。研发团队对Tele-FLM进行了包括语言困惑度、基础模型评测、对话模型评测在内的多维度测试,结果表明Tele-FLM在显著更低的预训练消耗(52B模型,2.0T tokens)下,性能可以比肩常见的强基线模型,例如Llama2-70B和GPT-3.5。
1.1 语言困惑度评测
测试集上的语言困惑度是衡量大模型对数据集的压缩率的重要指标,直观反映了模型对语言的建模、生成、续写能力。研发团队使用Bits-Per-Byte (BPB)作为评测指标。BPB通过引入tokenizer的影响,解决了基于单token平均loss的指标难以公平地进行跨模型比较的问题。
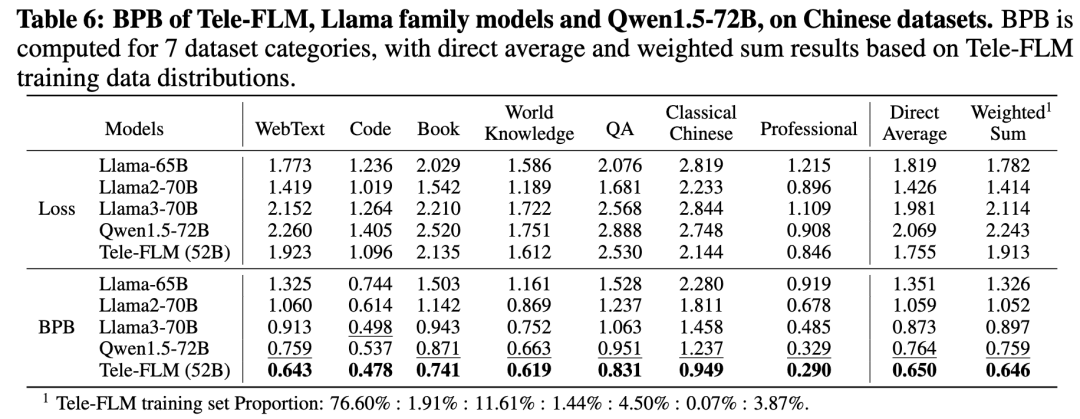
在英文上,团队选取了来自6个领域(网络文本、代码、百科知识、书籍、论文、问答)的文本作为测试集。结果显示,Tele-FLM的加权平均BPB优于Llama2-70B和Llama3-8B,仅次于使用了15T训练数据的Llama3-70B。注意到对于单个token的平均loss而言,Llama2-70B几乎持平于Tele-FLM,这反映了研发团队自行训练的tokenizer具有更高的英文压缩比,并带来优势。
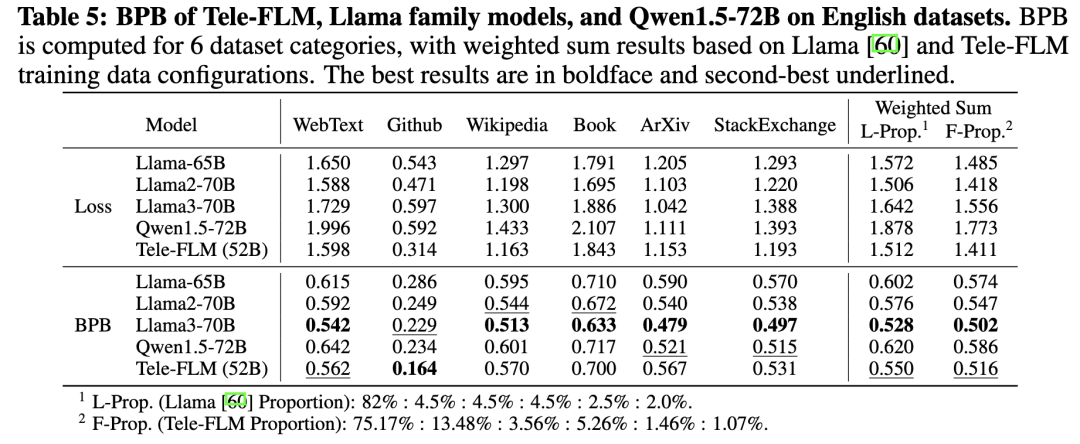
在中文上,类似地,团队选取7种来源(网络文本、代码、书籍、知识、问答、古文、专业领域)的文本作为测试集。结果显示,Tele-FLM的中文BPB低于Llama3-70B和Qwen1.5-72B。为了使模型具备多语言能力,研发团队在预训练数据集中引入了多语语料。
综上,Tele-FLM能够高效地建模中文和英文,同时具备较强的多语言能力。
1.2 基础模型评测
对于Tele-FLM基础模型,在英文上,研发团队选取Open LLM Leaderboard覆盖的6个测试基准,以及衡量代码能力的HumanEval、衡量推理能力的BBH进行评测,并选取Llama系列模型进行对比。结果如下:
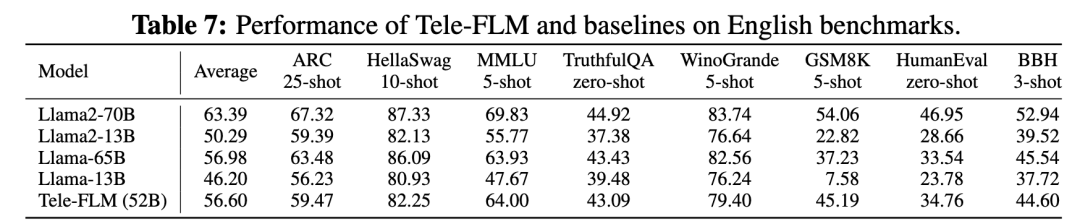
实验结果显示,Tele-FLM在英文评测上达到了Llama-65B的水平,与Llama2-70B可比。Tele-FLM的英文训练数据约为1.3T tokens,远少于Llama2-70B的2.0T,同时模型大小只有52B。这说明Tele-FLM对模型大小和训练数据的利用能力(scaling能力)略优于Llama系列。
在中文上,选取C-Eval, CMMLU, C^3, CHID和CSL作为测试基准,利用OpenCompass工具进行评测。结果如下:
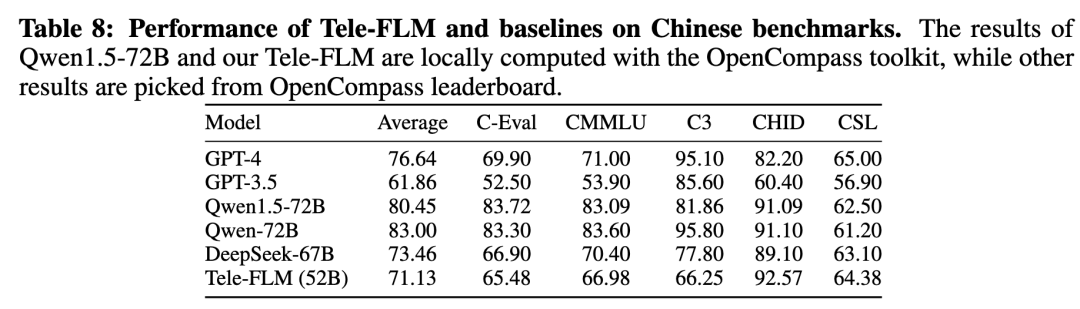
评测结果表明,Tele-FLM在几乎所有中文任务上优于GPT-3.5,并在大部分任务上接近GPT-4和DeepSeek-67B。在模型大小和数据规模上,Tele-FLM略低于DeepSeek-67B,并显著低于Qwen1.5-72B(3T预训练数据)和GPT-4。同时,在CHID和CSL等数据集上,Tele-FLM领先于几乎所有基线模型。因此,在中文上可以得到和英文一致的结论:Tele-FLM具有较好的scaling性质。
1.3 对话模型评测
基于Tele-FLM基础模型,研发团队对人工收集的对话数据进行了监督微调(SFT),得到多轮对话模型Tele-FLM-Chat。为了评价模型的对话能力,研发团队建立了包含2500+单轮、多轮对话交互的内部评测系统,涵盖闲聊问答、专业知识、翻译、逻辑思维、长文写作、幻觉测试、安全测试、角色扮演、任务执行、数学能力等多个维度,并使用Judge模型基于详细的评价指标文档进行自动打分。在当前评测数据上,Tele-FLM-Chat的综合平均得分为82.5,高于GPT-3.5的82.3。这一结果表明,Tele-FLM模型能较好地支持下游任务应用。
-
训练零调整助力低碳
大模型对超参非常敏感,超参直接会影响到大模型的收敛性、稳定性,进而直接影响到模型的最终表现。优化和调整超参需要多次重复训练模型,由于单次模型训练的成本已经很高,多次试错带来的成本将会使模型成本进一步攀升。因此需要找到一种方法,在训练开始前,就可以利用少量算力计算出模型的最优超参,并一次训练成功。
Tele-FLM使用896张A800 GPU,训练数据为2T tokens。与Llama-3可能使用的近5万张H100的基础算力相比,硬件的高利用率和训练的低试错率显得尤为重要。为了获得最佳利用率,Tele-FLM使用了3D并行+序列并行的训练框架;为了降低试错成本,研发团队首先使用一个宽度为512的中介小模型进行超参数搜索,并通过μP技术将最优超参数传递到大模型上。以上技术使模型的零调整高效训练成为可能。Tele-FLM是目前使用μP技术直接训练的最大的开源模型,也是首次开源零调整低碳训练模式的大模型。
-
全面开源助力社区发展
为最大限度地回馈开源社区,研发团队已经全面开源Tele-FLM的核心技术、训练细节和模型参数。
3.1 模型参数全面开源
研发团队现已将Tele-FLM的基础模型权重在HuggingFace上进行了开源。而模型的Chat版本也将在更细致打磨后进行开源。
https://huggingface.co/CofeAI/Tele-FLM
Tele-FLM—HuggingFace页面
3.2 训练细节全面开源
研发团队公开了Tele-FLM训练数据的语种配比和领域配比等细节。Tele-FLM的训练数据包含了以中、英文为主的共计超过十余种语言。经实验调整,最终确定英文比中文为2:1,在中文数据量并不突出的情况下依靠语料质量获得了优秀的中文性能。
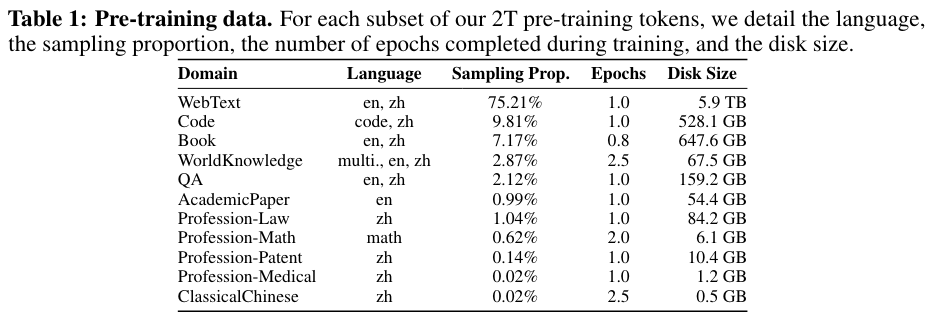
Tele-FLM训练数据配比
Tele-FLM的一个重要特点就是低碳训练,这得益于研发团队使用的μP高效超参搜索技术。团队在小模型上进行网格搜索获得最优参数后,经过映射,直接获得大模型上对应的最优超参,保障了大模型训练的收敛性和稳定性。本次发布,团队也将超参搜索过程、最优超参配置,以及大模型训练全程的loss、gradnorm、以及评测曲线全面公开。
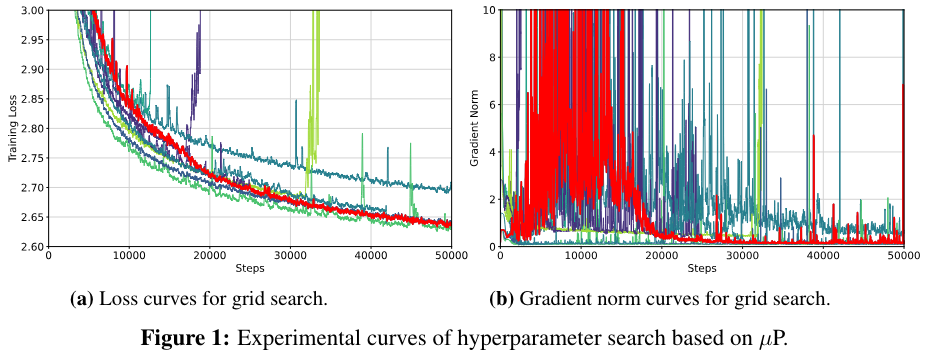
Tele-FLM超参数搜索loss/gradnorm曲线
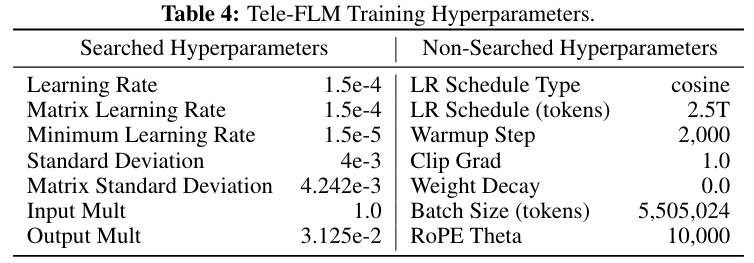
Tele-FLM训练超参
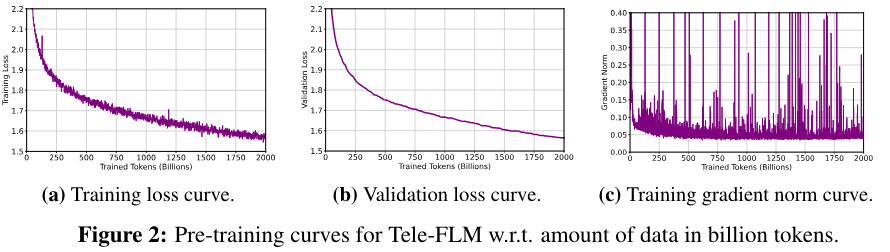
Tele-FLM训练全程loss/gradnorm曲线
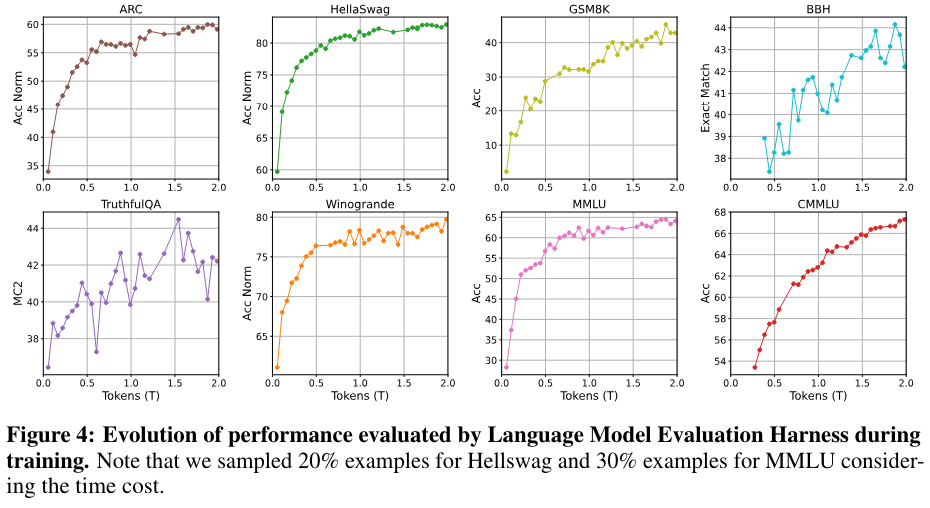
Tele-FLM训练全程性能评测曲线
3.3 核心技术全面开源
模型发布的同时,Tele-FLM的技术报告也已在Arxiv上发布。
https://arxiv.org/abs/2404.16645

Tele-FLM涉及的损失预测、模型生长等团队前期技术成果也均可通过代码、文章形式获取。
模型生长:
https://openreview.net/pdf?id=rL7xsg1aRn
https://github.com/cofe-ai/MSG
损失预测:
https://arxiv.org/pdf/2304.06875
https://github.com/cofe-ai/Mu-scaling
FLM-101B:
https://arxiv.org/pdf/2309.03852
https://huggingface.co/CofeAI/FLM-101B
-
基础模型训练的经验和教训
Lesson 1:当训练数据的“质”和“量”不可兼得时,优先考虑“质”
预训练数据最重要的两点是“质”和“量”。中英双语大模型,目前典型且安全的做法为中英比例处于1:1左右。经过长时间积累,中文语料的“量”已经比较可观,但是“质”参差不齐。当“质”和“量”不可兼得时,优先保障“质”更重要。Tele-FLM在保证中文“质”的前提下,采用了中文:英文为1:2的比例,实验结果证明,模型取得了优秀的中文能力表现。
Lesson 2:使用超参搜索技术,提前锁定优秀的超参
学习率等关键超参,直接影响模型最终的性能。为了降低成本,保护投资,建议采用损失预测技术附带的超参搜索能力,在小参数规模上提前搜索最优超参,使得大模型的正式训练具备更好的稳定性和收敛性。
Lesson 3:训练 loss 的 spike 一定条件下是正常的
首先,基础模型的训练loss 应该在0.5T数据内快速下降,如果无法快速下降到理想值,建议及时调整。其次,训练loss的 spike 不一定需要严格避免,如果grad norm是正常的,且loss 快速回到正常范围,那么spike 可接受,研发团队在训练过程中多次观察到该现象。现代大模型的结构,特别是具有非bias设计和截断 norm初始化的结构的模型,结合有效的超参数搜索,是具备足够的鲁棒性应对spike。不健康的spike会导致loss的持续崩溃,这种不健康的spike 可以通过小参数调参及早识别并避免。
Lesson 4:Grad Norm 形态可能是迥异的
早期的grad norm 形态并不是训练稳定性的强有力的指示。研发团队发现了多种形态迥异的健康的grad norm,形态区别非常大,但是都可以稳定收敛。一般情况下,只要不会发生持续快速上升,都是潜在的可能的健康状态,可采用损失预测技术观察全程来最终定夺。















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









