







【大作业-22】使用deeplab进行视杯视盘分割
配合视频食用更美味!
之前我们有出过一期使用unet进行医学图像分割的视频,但是其中好多小伙伴反应自己的任务很多时候都是多分类的任务,使用unet风格的效果一般,所以这期我们使用deeplab来进行多类别语义分割,本次我们的内容将会涉及到3个类别,使用的数据为眼底图像,分割的对象为眼底图像的视盘和视杯, 我们将会根据分割之后的结果进行出行比值的计算,然后通过杯盘比来计算是否存在潜在的眼病风险。效果如下:
背景意义
眼底图像的视盘(Optic Disc, OD)和视杯(Optic Cup, OC)的提取是眼科医学图像处理中的一个重要任务,特别是在青光眼等眼部疾病的检测与诊断中具有重要意义。通过语义分割技术,自动、精确地提取视盘和视杯区域,可以有效提高诊断效率和准确性。
背景
- 眼底图像:眼底图像是通过眼底相机捕捉到的视网膜图像,通常用于检测多种眼科疾病,包括青光眼、糖尿病性视网膜病变和年龄相关性黄斑变性等。
- 视盘(OD)和视杯(OC):视盘是视神经进入眼球的地方,在眼底图像中呈现为圆形或椭圆形的亮区。视杯是视盘中心的凹陷区域,是视盘的一部分。视杯和视盘的形态及比例对于青光眼的诊断至关重要。
- 青光眼诊断:青光眼是一种眼内压升高导致的视神经损伤疾病,如果不及时治疗,会导致不可逆的视力丧失。视杯和视盘的比例(Cup-to-Disc Ratio, CDR)是判断青光眼的重要生物标志之一,CDR 越高,青光眼的风险越大。
意义
- 自动化诊断的基础:通过语义分割技术自动提取视盘和视杯区域,可以为青光眼的诊断提供关键的结构信息,特别是用于计算 CDR。传统的手工标注费时费力且易受人为误差影响,自动化方法则可以大幅提高效率和准确性。
- 辅助医生的决策:语义分割的结果可以作为辅助诊断工具,帮助医生更好地分析眼底图像中的细节,快速识别可能的异常区域。这对于医疗资源有限的地区尤为重要。
- 疾病进展监测:定期的眼底图像检查结合语义分割技术可以用于监测青光眼患者的病情进展,通过比较不同时间点的 CDR 变化,帮助医生调整治疗方案。
- 人工智能辅助系统的开发:精确的视盘和视杯分割是构建人工智能辅助诊断系统的重要模块。通过深度学习和语义分割技术,这类系统可以自主处理大量的眼底图像,提升医疗服务的覆盖率和诊断的一致性。
相关文献
在过去五年中,深度学习技术在眼底图像的视盘(Optic Disc, OD)和视杯(Optic Cup, OC)分割任务中的应用取得了显著进展。这一任务对于青光眼的检测和诊断尤为重要,因为视杯与视盘的比例(CDR)是青光眼的重要生物标志之一。
-
基于卷积神经网络的分割方法
大多数深度学习方法使用全卷积网络(FCN)来实现视盘和视杯的分割。例如,使用深度卷积神经网络的系统通过多层次特征提取,对视盘和视杯区域进行精确分割。研究者提出了一些改进的网络架构,比如在使用经典 U-Net 的基础上加入注意力机制,提升了分割的细节捕捉能力(BioMed Central)(SpringerLink)。
-
联合分割模型
近年来,联合分割模型得到了广泛关注。例如,研究人员提出了基于密集连接的卷积神经网络来同时分割视盘和视杯。这种方法利用了深度网络的特征提取能力,结合了多专家标注,提升了视杯的分割精度(BioMed Central)。
-
深度学习中的自监督学习
为了提升分割效果,一些研究采用了自监督学习方法。自监督预训练模型在分割过程中利用了更多未标注数据,从而提高了视盘和视杯区域的检测和分割精度(ar5iv)。
-
深度图像的应用
有研究使用深度图像和立体眼底图像进行视盘和视杯分割。深度信息有助于解决视杯的轮廓提取难题,尤其在病变区域中表现更加稳定。通过结合立体视觉和深度图的特征,分割模型能更好地处理复杂的三维结构(SpringerLink)。
-
挑战与方法:
数据质量与标注:高质量的眼底图像和精确的标注数据对训练分割模型至关重要。手工标注这些区域通常需要专业的眼科医生,因此构建大规模、高质量的标注数据集是一个挑战。
模型选择:常用的语义分割模型包括 U-Net、DeepLabV3、FCN(Fully Convolutional Networks)等,这些网络可以有效处理眼底图像的特征,并且可以结合注意力机制或多尺度信息以提高分割精度。
精度和泛化能力:由于不同患者的眼底图像在颜色、亮度和形态上可能存在较大差异,分割模型需要具有良好的泛化能力,以便能够在不同类型的眼底图像上取得稳定的分割效果。
本案例所使用方法
本文我们将会使用经典的deeplabv3和deeplabv3+来进行实验,并且通过将主干网络从resnet50更换为resnet18来让我们的模型更加轻量化。关于我们本次大作业中使用到的方法的详细描述如下:
deeplabv3
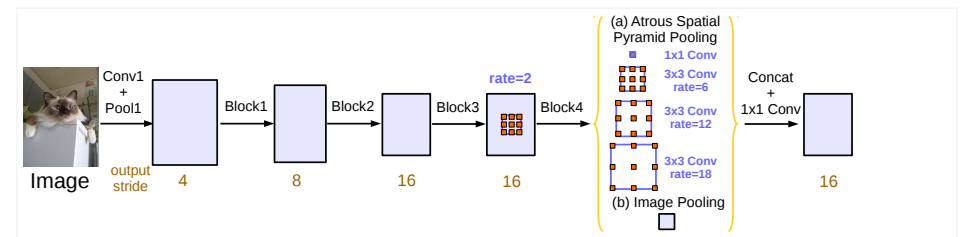
DeepLabV3 是一种先进的语义分割方法,基于深度卷积神经网络 (CNN) 的设计,在计算机视觉领域具有广泛的应用。它由 Google 提出,并逐步改进,以提高分割精度和处理复杂场景的能力。DeepLabV3 主要通过以下创新来实现高效的语义分割:
空洞卷积(Atrous Convolution)
DeepLabV3 引入了空洞卷积(也称为膨胀卷积),它通过在卷积核中加入“洞”(dilation rate)来扩展感受野,而不增加参数量或计算成本。这使得模型可以更好地捕捉多尺度的信息,并且不会丢失细节,特别适用于高分辨率的图像分割。
空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)
ASPP 是 DeepLabV3 的关键组件,它通过多个并行的空洞卷积分支,分别以不同的采样率进行卷积,从而提取不同尺度下的特征。这一机制使得模型能够有效处理图像中物体尺度的变化,对于复杂场景中的语义分割非常有帮助。
** 全局上下文信息的引入**
DeepLabV3 通过全局池化(Global Average Pooling)来提取全局上下文信息。它将整个特征图的平均值作为全局上下文,并将其与通过空洞卷积提取的局部特征结合,有助于提高分割的准确性,特别是在处理具有复杂背景的图像时。
可用于不同的主干网络
DeepLabV3 可以与多种主干网络(如 ResNet、Xception)结合使用。这些主干网络用于特征提取,而 DeepLabV3 模块则负责在高层特征上进行分割。这种模块化设计使得 DeepLabV3 可以适应不同的需求和应用场景。
deeplabv3+
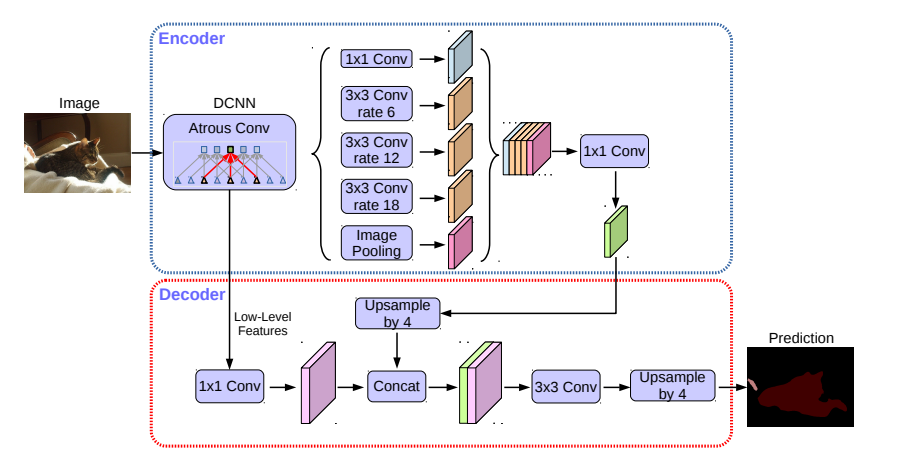
DeepLabV3+ 是 DeepLabV3 的增强版本,进一步提高了语义分割任务的精度,尤其是在处理物体边界和复杂细节方面。它保持了 DeepLabV3 的核心架构,特别是空洞卷积和空间金字塔池化(ASPP),但引入了一些关键改进来提升性能。
编码器-解码器结构: DeepLabV3+ 将编码器-解码器架构引入到模型中。编码器部分类似于 DeepLabV3,负责提取深层特征,而解码器部分则用于逐步恢复分辨率,细化分割结果。这个解码器模块通过融合低层次的空间信息,使得模型能够更好地处理边界区域和小物体
改进的空间信息恢复: 虽然 DeepLabV3 使用空洞卷积扩展了感受野,但它在恢复低分辨率特征时仍面临挑战。DeepLabV3+ 引入了解码器,通过对低层次特征进行融合来恢复细节,解决了高层特征图在分辨率上的损失问题,从而提高了边界处理的精度。
Xception 主干网络的增强: DeepLabV3+ 对 Xception 网络进行了优化,使用深度可分离卷积来减少计算开销,同时保留高效的特征提取能力。这个增强的主干网络帮助 DeepLabV3+ 在保持计算效率的同时,进一步提升了分割精度。
实验结果
ok,这里有一些指标上的实验结果和可视化的实验结果,大家拿到源码之后可以根据结果进行适当的补充。
指标方面,我们使用的是miou和macc。
mIoU 是评估语义分割模型性能最常用的指标之一。IoU(Intersection over Union)也称为 Jaccard Index,用于评估分割结果与真实标签之间的重叠程度。具体计算如下:

mAcc 是另一种衡量语义分割模型的指标,定义为每个类别的像素分类准确率的平均值。具体计算公式为:

m是mean的意思,相当于是计算完所有的类别之后对所有的类别进行平均。
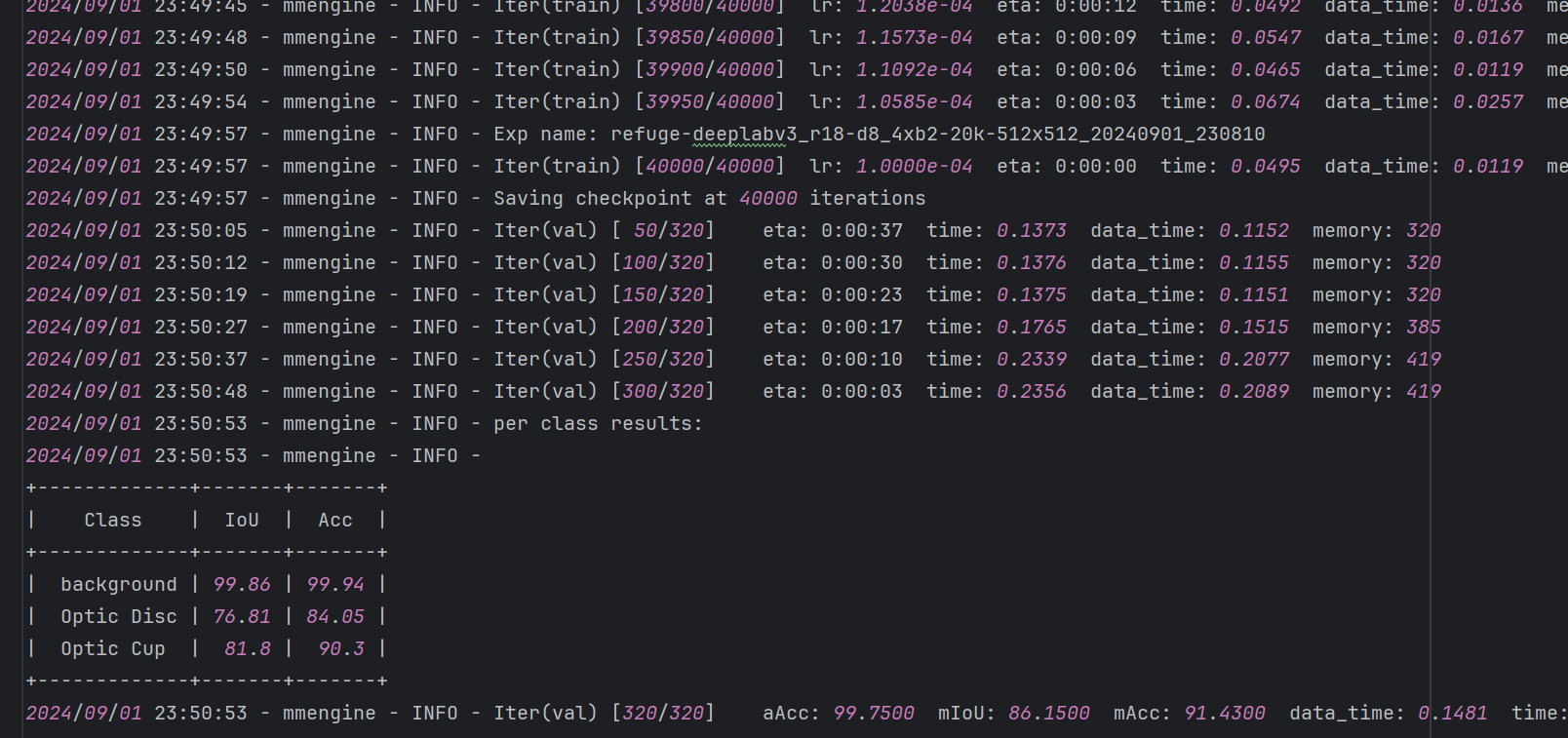
在本次的案例中,以我们的refuge-deeplabv3_r18-d8_4xb2-20k-512x512模型为例,可以得到下面所示的结果:
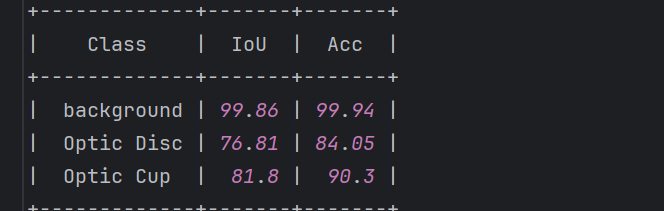
另外,这里也有一些可视化的效果,从这里的预测结果可以看出我们的模型可以很好地分割出眼底图像的视盘和视杯区域,为后面的占比计算提供了良好的基础
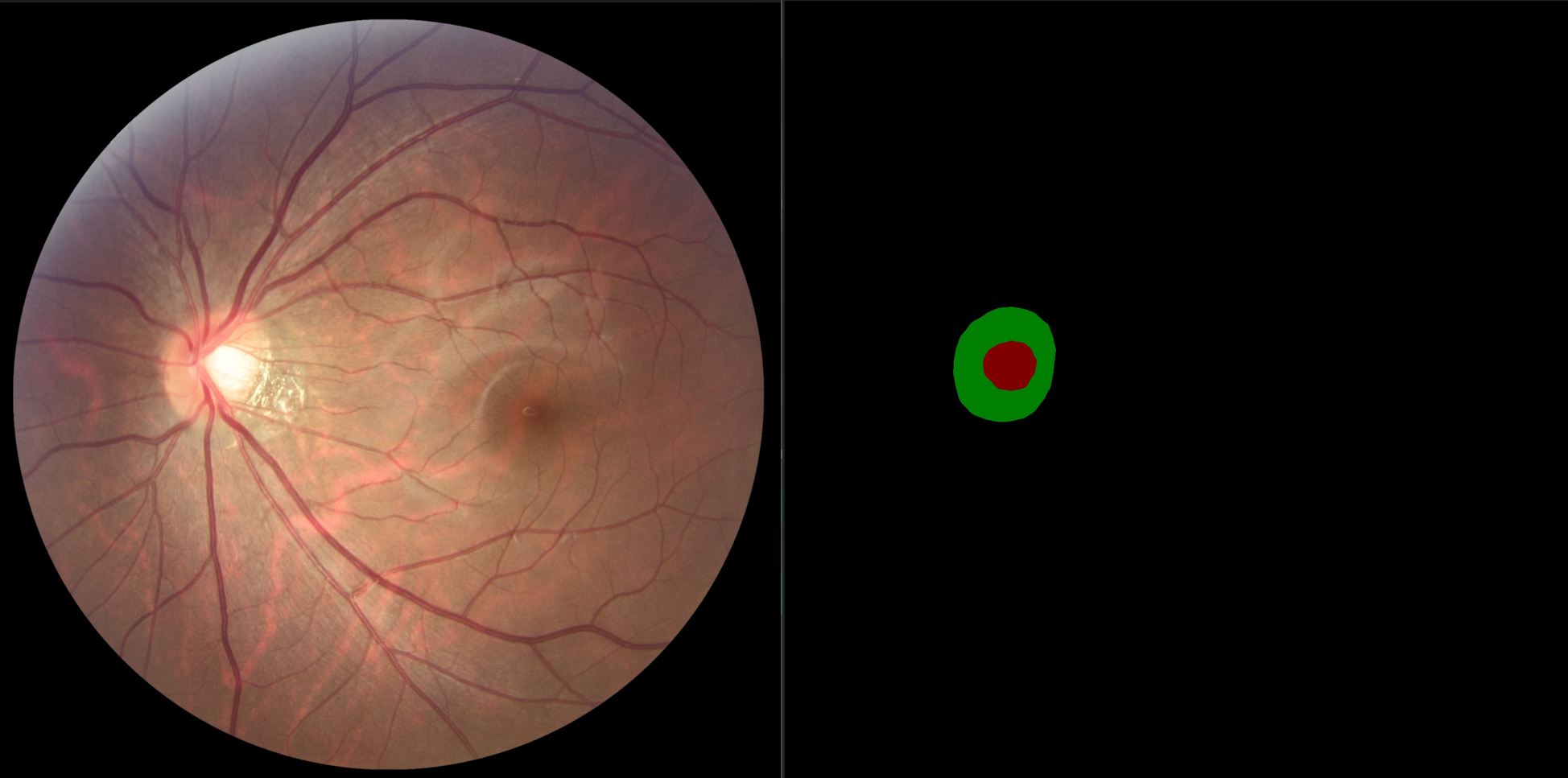
项目实战
为了方便大家使用,我在原始的代码上进行了修改,可以方便地对上面的案例进行预测,配套的资源可以在本博客的上方或者是在B站的工房中进行获取。拿到项目之后首先进行解压,解压后请将压缩包的文件夹放于英文目录下方,防止后面库的安装出现问题。

环境配置
创建适合于这个项目的虚拟环境并激活虚拟环境
# 安装并激活对应的虚拟环境
conda create -n eye42 python==3.8.5
cconda activate eye42
安装pytorch
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装openmim
pip install openmim
安装mmcv
mim install mmcv==2.1.0
安装其他的依赖库
pip install -r requirements.txt
pip install -v -e .
安装完毕之后你首先可以你执行第一个42_step0_demo.py做一个简单的测试,脚本的内容如下:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :mmsegmentation-main
@File :42_demo.py
@IDE :PyCharm
@Author :肆十二(付费咨询QQ: 3045834499) 粉丝可享受99元调试服务
@Description :用来做初步验证主要是判断当前的模型配置是否存在问题
@Date :2024/8/27 16:24
'''
import torch
import matplotlib.pyplot as plt
from mmengine.model.utils import revert_sync_batchnorm
from mmseg.apis import init_model, inference_model, show_result_pyplot
config_file = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
checkpoint_file = 'pretrained_models/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# build the model from a config file and a checkpoint file
model = init_model(config_file, checkpoint_file, device='cpu')
# test a single image
img = 'demo/demo.png'
if not torch.cuda.is_available():
model = revert_sync_batchnorm(model)
result = inference_model(model, img)
# show the results
vis_result = show_result_pyplot(model, img, result, show=False)
plt.imshow(vis_result)
plt.show()
执行的结果如下,出现这样的结果说明你这里的环境安装是没有问题的:
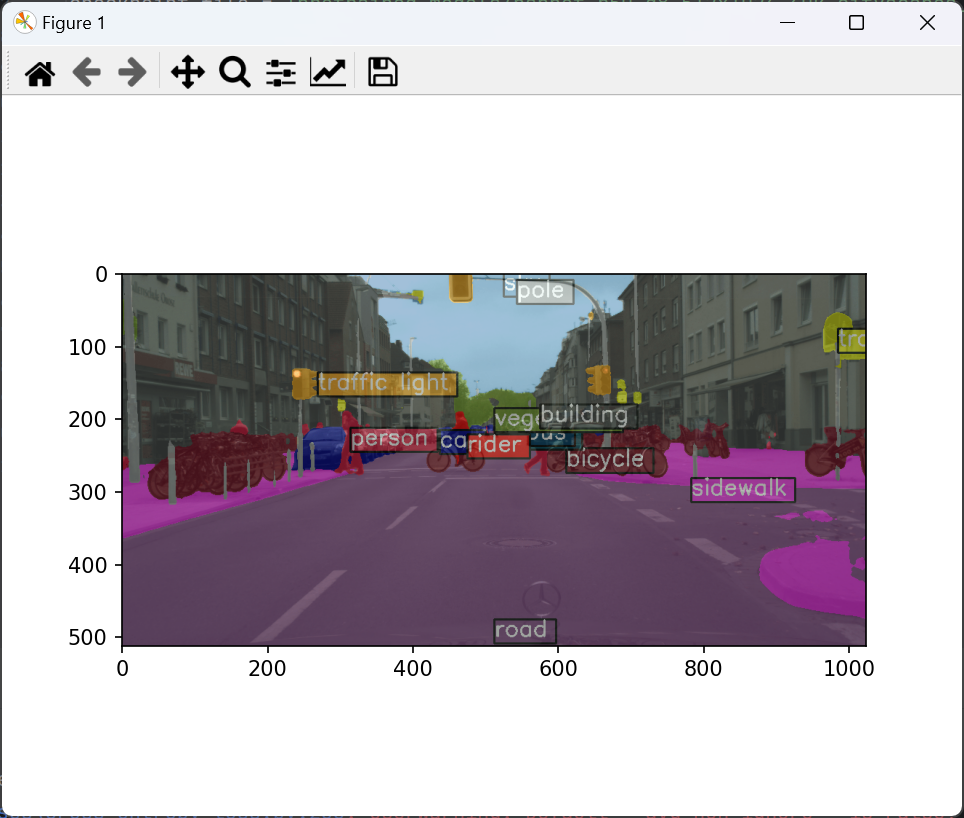
之后使用pycharm打开该项目并选择配套的虚拟环境即可。
数据集准备
模型训练开始之前,需要准备好语义分割的数据,主要是包含训练集的原始图像和标签,以及测试集的原始图像和标签。如下图所示:
其中原始图像就是正常的彩色图像,标签需要需要根据你的任务进行预处理,比如之前您的标签图像为彩色图像,需要将彩色的信息处理为代码可以识别的012的类别信息,处理完毕之后的图像看起来可能是全黑的,实际上是有类别信息的,如下图所示,其中左侧图像是使用labelme标注完成之后生产的彩色标签图像,右侧是处理完之后的黑色标签图像。

ok 不论是训练集还是测试集,请务必保持图像数量和标签数量是一致的,如下图所示:
另外,请记住类别数目和类别名称以及对应的彩色渲染颜色,后面我们将会使用到, 这里我也提供一下颜色转化的顺序。
# [[ 0 0 0]
# [128 0 0]
# [ 0 128 0]
# [128 128 0]
# [ 0 0 128]
# [128 0 128]
# [ 0 128 128]
# [128 128 128]
# [ 64 0 0]
# [192 0 0]
# [ 64 128 0]
# [192 128 0]
# [ 64 0 128]
# [192 0 128]
# [ 64 128 128]
# [192 128 128]
# [ 0 64 0]
# [128 64 0]
# [ 0 192 0]
# [128 192 0]
模型训练
模型训练方面我们只需要配置好配置文件,然后在使用train的脚本进行训练即可,如下图所示,是一个典型的deeplabv3的模型配置文件。
_base_ = [
'../_base_/models/deeplabv3_r50-d8.py', '../_base_/datasets/A_42_my_dataset.py',
'../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
]
norm_cfg = dict(type='BN', requires_grad=True)
crop_size = (512, 512)
data_preprocessor = dict(size=crop_size)
model = dict(
data_preprocessor=data_preprocessor,
decode_head=dict(num_classes=3),
auxiliary_head=dict(num_classes=3))
# 可视化操作
vis_backends = [dict(type='LocalVisBackend'),
dict(type='TensorboardVisBackend')]
visualizer = dict(
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
模型训练,只需要通过简单的脚本来执行即可。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :mmsegmentation-main
@File :42_train.py
@IDE :PyCharm
@Author :肆十二(付费咨询QQ: 3045834499) 粉丝可享受99元调试服务
@Description :TODO 添加文件描述
@Date :2024/8/27 16:23
'''
import os
os.system("python tools/train.py configs/A_42_eye/refuge-deeplabv3_r18-d8_4xb2-20k-512x512.py")
os.system("python tools/train.py configs/A_42_eye/refuge-deeplabv3_r50-d8_4xb2-20k-512x512.py")
os.system("python tools/train.py configs/A_42_eye/refuge-deeplabv3plus_r18-d8_4xb2-40k_512x512.py")
os.system("python tools/train.py configs/A_42_eye/refuge-deeplabv3plus_r50-d8_4xb2-40k_512x512.py")
打开文件之后,右键执行即可。
训练结束之后,将会在workdirs的目录下面产生训练好的日志,里面包含了训练的日志记录,模型的配置文件以及模型的权重文件。

日志对你的报告构成非常重要,里面包含了训练过程中的loss信息以及你设备的信息和所使用库文件的版本信息。
模型测试
同样模型的测试也只需要通过简单的脚本来进行完成,只是脚本从上面的train更换为了val.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :mmsegmentation-main
@File :42_val.py
@IDE :PyCharm
@Author :肆十二(付费咨询QQ: 3045834499) 粉丝可享受99元调试服务
@Description :用于模型本地的验证测试
@Date :2024/8/27 16:23
'''
import os
os.system("python tools/test.py work_dirs/refuge-deeplabv3_r18-d8_4xb2-20k-512x512/refuge-deeplabv3_r18-d8_4xb2-20k-512x512.py work_dirs/refuge-deeplabv3_r18-d8_4xb2-20k-512x512/iter_40000.pth")
执行这个脚本之后将会输出miou等指标。
另外这里还提供了对图像、文件夹以及视频的预测脚本,如下所示,也是修改为你自己数据路径之后直接执行即可,详情可以直接查看Bz站的视频。
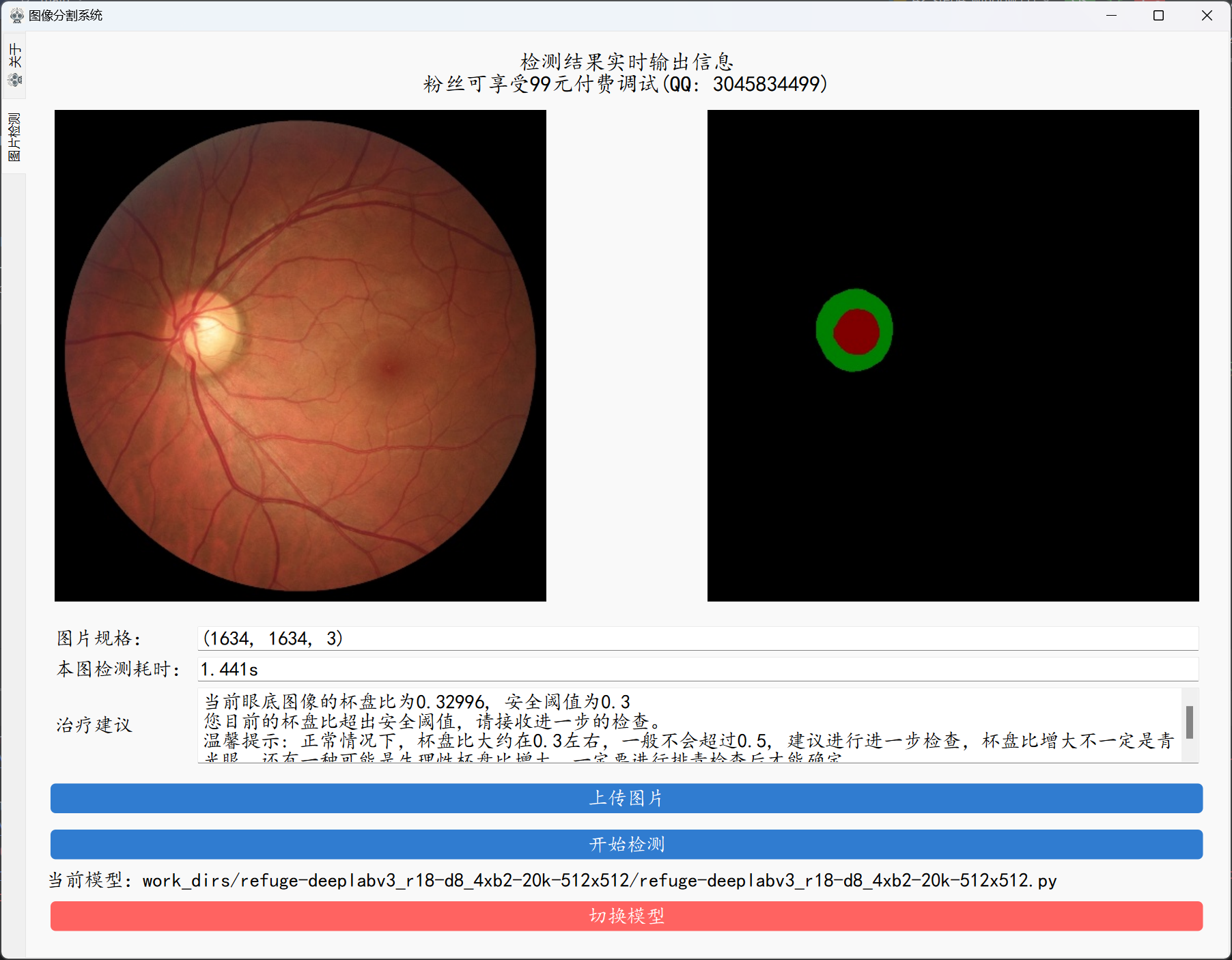
图形化界面封装
最后我们使用pyside6对图形化的界面进行封装,界面可以完成模型的加载、图像的上传和图像的检测,其中界面部分代码如下,基本使用的都是常用的图形化组件。
import shutil
import PySide6
from PySide6.QtGui import *
from PySide6.QtCore import *
from PySide6.QtWidgets import *
import threading
import sys
import cv2
import os.path as osp
import time
from mmseg.apis import inference_model, init_model, show_result_pyplot
import os
import copy
import numpy as np
# DEVICE = 'cuda:0' # 如果您的电脑是GPU的设备,请使用这个
DEVICE = 'cpu' # 如果您的电脑只有CPU,请使用这个
SYSTEM_INFO = ("以下是一些常见的治疗建议:"
"\n1.药物治疗:详细医疗建议3"
"\n2.物理因子治疗:详细医疗建议2"
"\n3.手术治疗:详细医疗建议3")
Window_TITLE = "图像分割系统"
ICON_PATH = "images/UI/lufei.png"
ZUOZHE = "<a href='https://space.bilibili.com/161240964'>作者:肆十二</a>"
WELCOME_LABEL = '欢迎使用基于深度学习的语义分割系统\n粉丝可享受99元付费调试(QQ: 3045834499)'
def model_load(model_path, config_path, device):
# model = init_segmentor(config_path, model_path, device=DEVICE)
model = init_model(config_path, model_path, device=device)
# 添加模型信息
model.dataset_meta['classes'] = ('background', ' Optic Cup', 'Optic Disc')
model.dataset_meta['palette'] = [[0, 0, 0], [128, 0, 0], [0, 128, 0]]
return model
def get_result(model, img_path):
"""
获取图像输出的结果
Args:
model: 已经加载好的模型
img_path: 需要进行分割的图像
Returns:
"""
# 通过模型直接进行推理和输出
result = inference_model(model, img_path)
vis_result = show_result_pyplot(model, img_path, result, show=False, out_file='demo/tmp/images_tmp.jpg', opacity=1.0, with_labels=False)
vis_result = cv2.cvtColor(vis_result, cv2.COLOR_BGR2RGB)
# 定制化需求,计算占比
ratio = 0
result_copy = copy.deepcopy(result)
numpy_data = result_copy.pred_sem_seg.numpy().data
cup_count = np.sum(numpy_data == 1)
Disc_count = np.sum(numpy_data == 2)
ratio = round(cup_count / (Disc_count+cup_count), 5)
return vis_result, ratio
# 眼底图像参考资料:https://zhuanlan.zhihu.com/p/384739958
class MainWindow(QTabWidget):
def __init__(self):
# 初始化界面
super().__init__()
self.setWindowTitle(Window_TITLE)
self.resize(1200, 800)
self.setWindowIcon(QIcon(ICON_PATH))
# 图片读取进程
self.output_size = 480
# todo 修改为你要加载得模型
self.device = DEVICE
self.MODEL_PATH = 'work_dirs/refuge-deeplabv3_r18-d8_4xb2-20k-512x512/iter_40000.pth'
self.CONFIG_PATH = 'work_dirs/refuge-deeplabv3_r18-d8_4xb2-20k-512x512/refuge-deeplabv3_r18-d8_4xb2-20k-512x512.py'
self.seg_model = model_load(model_path=self.MODEL_PATH,
config_path=self.CONFIG_PATH, device=self.device)
self.img2predict = ""
self.cd_th = 0.3
# # 初始化视频读取线程
self.vid_source = '0' # 初始设置为摄像头
self.stopEvent = threading.Event()
self.webcam = True
self.stopEvent.clear()
self.initUI()
'''
***界面初始化***
'''
def initUI(self):
# 图片检测子界面 整体是左右布局
font_title = QFont('楷体', 16)
font_main = QFont('楷体', 14)
img_detection_widget = QWidget()
img_detection_layout = QHBoxLayout()
#################### 图片布局 #################################
right_img_widget = QWidget()
right_img_layout = QHBoxLayout()
self.left_img = QLabel()
self.right_img = QLabel()
self.left_img.setPixmap(QPixmap("images/UI/up380.jpeg"))
self.right_img.setPixmap(QPixmap("images/UI/right380.jpeg"))
self.left_img.setAlignment(Qt.AlignCenter)
self.right_img.setAlignment(Qt.AlignCenter)
right_img_layout.addWidget(self.left_img)
right_img_layout.addStretch(0)
right_img_layout.addWidget(self.right_img)
right_img_widget.setLayout(right_img_layout)
left_show_widget = QWidget()
left_show_layout = QVBoxLayout()
left_show_title = QLabel("检测结果实时输出信息"
"\n粉丝可享受99元付费调试(QQ: 3045834499)")
left_show_title.setFont(font_title)
left_show_title.setAlignment(Qt.AlignCenter)
img_info_widget = QWidget()
img_info_layout = QGridLayout()
img_info_label0 = QLabel("图片规格:")
img_info_label2 = QLabel("本图检测耗时:")
img_info_label3 = QLabel("治疗建议")
self.img_info_edit0 = QLineEdit("")
self.img_info_edit1 = QLineEdit("")
self.img_info_edit2 = QLineEdit("")
self.img_info_edit3 = QTextEdit("")
self.img_info_edit3.setText(SYSTEM_INFO)
# img_info_edit4 = QLineEdit("")
img_info_layout.addWidget(img_info_label0, 0, 0)
img_info_layout.addWidget(self.img_info_edit0, 0, 1)
# img_info_layout.addWidget(img_info_label1)
# img_info_layout.addWidget(self.img_info_edit1)
img_info_layout.addWidget(img_info_label2)
img_info_layout.addWidget(self.img_info_edit2)
img_info_layout.addWidget(img_info_label3)
img_info_layout.addWidget(self.img_info_edit3)
# img_info_layout.addWidget(img_info_label4)
# img_info_layout.addWidget(img_info_edit4)
img_info_widget.setLayout(img_info_layout)
img_info_widget.setFont(font_main)
up_img_button = QPushButton("上传图片")
det_img_button = QPushButton("开始检测")
up_img_button.clicked.connect(self.upload_img)
det_img_button.clicked.connect(self.detect_img)
up_img_button.setFont(font_main)
det_img_button.setFont(font_main)
up_img_button.setStyleSheet("QPushButton{color:white}"
"QPushButton:hover{background-color: rgb(2,110,180);}"
"QPushButton{background-color:rgb(48,124,208)}"
"QPushButton{border:2px}"
"QPushButton{border-radius:5px}"
"QPushButton{padding:5px 5px}"
"QPushButton{margin:5px 5px}")
det_img_button.setStyleSheet("QPushButton{color:white}"
"QPushButton:hover{background-color: rgb(2,110,180);}"
"QPushButton{background-color:rgb(48,124,208)}"
"QPushButton{border:2px}"
"QPushButton{border-radius:5px}"
"QPushButton{padding:5px 5px}"
"QPushButton{margin:5px 5px}")
left_show_layout.addWidget(left_show_title)
left_show_layout.addWidget(right_img_widget)
left_show_layout.addWidget(img_info_widget)
left_show_layout.addWidget(up_img_button)
left_show_layout.addWidget(det_img_button)
self.model_label = QLabel("当前模型:{}".format(self.CONFIG_PATH))
self.model_label.setFont(font_main)
change_model_button = QPushButton("切换模型")
change_model_button.setFont(font_main)
change_model_button.setStyleSheet("QPushButton{color:white}"
"QPushButton:hover{background-color: rgb(236,99,97);}"
"QPushButton{background-color:rgb(255,99,97)}"
"QPushButton{border:2px}"
"QPushButton{border-radius:5px}"
"QPushButton{padding:5px 5px}"
"QPushButton{margin:5px 5px}")
left_show_layout.addWidget(self.model_label)
left_show_layout.addStretch()
left_show_layout.addWidget(change_model_button)
left_show_layout.addStretch()
left_show_widget.setLayout(left_show_layout)
img_detection_layout.addWidget(left_show_widget)
# img_detection_layout.addWidget(right_img_widget, alignment=Qt.AlignCenter)
img_detection_widget.setLayout(img_detection_layout)
vid_detection_widget = QWidget()
vid_detection_layout = QHBoxLayout()
vid_info_widget = QWidget()
vid_info_layout = QGridLayout()
vid_info_label0 = QLabel("视频单帧规格:")
vid_info_label1 = QLabel("目标检测数量:")
vid_info_label2 = QLabel("目标坐标:")
vid_info_label3 = QLabel("FPS:")
vid_info_label4 = QLabel("当前检测总帧数:")
vid_info_edit0 = QLineEdit("")
vid_info_edit1 = QLineEdit("")
vid_info_edit2 = QLineEdit("")
vid_info_edit3 = QLineEdit("")
vid_info_edit4 = QLineEdit("")
vid_info_layout.addWidget(vid_info_label0, 0, 0)
vid_info_layout.addWidget(vid_info_edit0, 0, 1)
vid_info_layout.addWidget(vid_info_label1)
vid_info_layout.addWidget(vid_info_edit1)
vid_info_layout.addWidget(vid_info_label2)
vid_info_layout.addWidget(vid_info_edit2)
vid_info_layout.addWidget(vid_info_label3)
vid_info_layout.addWidget(vid_info_edit3)
vid_info_layout.addWidget(vid_info_label4)
vid_info_layout.addWidget(vid_info_edit4)
vid_info_widget.setLayout(vid_info_layout)
vid_info_widget.setFont(font_main)
vid_info_title = QLabel("检测结果实时输出")
vid_info_title.setAlignment(Qt.AlignCenter)
vid_info_title.setFont(font_title)
self.webcam_detection_btn = QPushButton("摄像头实时监测")
self.mp4_detection_btn = QPushButton("视频文件检测")
self.vid_stop_btn = QPushButton("停止检测")
self.webcam_detection_btn.setFont(font_main)
self.mp4_detection_btn.setFont(font_main)
self.vid_stop_btn.setFont(font_main)
vid_left_widget = QWidget()
vid_left_layout = QVBoxLayout()
vid_left_layout.addWidget(vid_info_title)
vid_left_layout.addWidget(vid_info_widget)
vid_left_layout.addWidget(self.webcam_detection_btn)
vid_left_layout.addWidget(self.mp4_detection_btn)
vid_left_layout.addWidget(self.vid_stop_btn)
vid_left_widget.setLayout(vid_left_layout)
self.webcam_detection_btn.clicked.connect(self.open_cam)
self.mp4_detection_btn.clicked.connect(self.open_mp4)
self.vid_stop_btn.clicked.connect(self.close_vid)
self.vid_img = QLabel()
self.vid_img.setPixmap(QPixmap("images/UI/up.jpeg"))
self.vid_img.setAlignment(Qt.AlignCenter)
vid_detection_layout.addWidget(vid_left_widget)
vid_detection_layout.addWidget(self.vid_img)
vid_detection_widget.setLayout(vid_detection_layout)
# todo 关于界面
about_widget = QWidget()
about_layout = QVBoxLayout()
about_title = QLabel(WELCOME_LABEL) # todo 修改欢迎词语
about_title.setFont(QFont('楷体', 18))
about_title.setAlignment(Qt.AlignCenter)
about_img = QLabel()
about_img.setPixmap(QPixmap('images/UI/logo.jpg'))
about_img.setAlignment(Qt.AlignCenter)
label_super = QLabel() # todo 更换作者信息
label_super.setText(ZUOZHE)
label_super.setFont(QFont('楷体', 16))
label_super.setOpenExternalLinks(True)
# label_super.setOpenExternalLinks(True)
label_super.setAlignment(Qt.AlignRight)
about_layout.addWidget(about_title)
about_layout.addStretch()
about_layout.addWidget(about_img)
about_layout.addStretch()
# about_layout.addWidget(self.model_label)
# about_layout.addStretch()
# about_layout.addWidget(change_model_button)
# about_layout.addStretch()
about_layout.addWidget(label_super)
about_widget.setLayout(about_layout)
change_model_button.clicked.connect(self.change_model)
self.left_img.setAlignment(Qt.AlignCenter)
self.addTab(about_widget, '关于')
self.addTab(img_detection_widget, '图片检测')
# self.addTab(vid_detection_widget, '视频检测')
self.setTabIcon(0, QIcon('images/UI/lufei.png'))
self.setTabPosition(QTabWidget.West)
# 设置背景颜色
# img_detection_widget.setStyleSheet("background-color:rgb(255,250,205);")
# self.setTabIcon(1, QIcon('images/UI/lufei.png'))
# self.setTabIcon(2, QIcon('images/UI/lufei.png'))
执行结果如下:
















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











