







文章目录
Pytorch完成线性回归
目标
- 知道
requires_grad的作用- 知道如何使用
backward- 知道如何手动完成线性回归
1. 计算图节点参数/属性与前向计算
pytorch的一个重要特点就是动态计算图(Dynamic Computational Graphs)。计算图中每一个节点代表一个变量,变量间建立运算关系并且可以修改,而不像Tensorflow中的计算图是固定不可变的。
tensor用来构建一个计算图中的节点。对于该节点,有两个重要的特性:
- .data——获得该节点的深拷贝值,即tensor类型的值
- .grad——获得该节点处的梯度信息
关于tensor的参数之一“requires_grad”和特性之一“grad_fn”有要注意的地方,都和该变量是否是人自己创建的有关:
- requires_grad有两个值:True和False,True代表此变量处需要追踪计算梯度,False代表不需要。变量的“requires_grad”值是tensor的一个参数,默认是False。
- grad_fn的值可以得知该变量是否是一个计算结果,也就是说该变量是不是一个函数的输出值。若是,则grad_fn返回一个与该函数相关的对象,否则是None。
**对于pytorch中的一个tensor,如果设置它的属性
.requires_grad为True,那么它将成为计算图中的一个节点,会追踪对于该张量的所有操作。或者可以理解为,这个tensor是一个参数,后续会被计算梯度,更新该参数。
1.1 requires_grad和grad_fn原理示例
a = torch.randn(2, 2)
print(a)
print(a.requires_grad)
print(a.grad_fn)
"""
tensor([[-1.8105, -0.2128],
[-0.4172, -0.4649]])
False
None
"""
a.requires_grad_(True)
print(a)
print(a.requires_grad)
print(a.grad_fn)
"""
tensor([[-1.8105, -0.2128],
[-0.4172, -0.4649]], requires_grad=True)
True
None
"""
a = (a * a) / (a - 1)
print(a)
print(a.requires_grad)
print(a.grad_fn)
"""
tensor([[1.9326, 0.5264],
[0.8832, 0.9521]], grad_fn=<DivBackward0>)
True
<DivBackward0 object at 0x000001C68E459D90>
"""
b = (a * a).sum
print(b)
print(b.requires_grad)
print(b.grad_fn)
"""
tensor([[3.9326, 2.5264],
[2.8832, 2.9521]], grad_fn=<AddBackward0>)
True
<AddBackward0 object at 0x000001C68E459C70>
"""
c = torch.randn(2, 2)
c = c - b
print(c)
print(c.requires_grad)
print(c.grad_fn)
"""
tensor([[-3.7701, -2.0016],
[-2.4378, -2.7576]], grad_fn=<SubBackward0>)
True
<SubBackward0 object at 0x000001C692B957C0>
"""
with torch.no_grad():
d = c * 2
print(d)
print(d.requires_grad)
print(d.grad_fn)
"""
tensor([[-7.5401, -4.0032],
[-4.8756, -5.5151]])
False
None
"""
注意:
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
1.2 前向计算过程
假设有以下条件(1/4表示求均值,xi中有4个数),使用torch完成其向前计算的过程
o = 1 4 ∑ i z i z i = 3 ( x i + 2 ) 2 其 中 : z i ∣ x i = 1 = 27 \begin{aligned} &o = \frac{1}{4}\sum_iz_i \\ &z_i = 3(x_i+2)^2\\ 其中:&\\ &z_i|_{x_i=1}=27\\ \end{aligned} 其中:o=41i∑zizi=3(xi+2)2zi∣xi=1=27
如果x为参数,需要对其进行梯度的计算和更新
那么,在最开始随机设置x的值的过程中,需要设置他的requires_grad属性为True,因为其默认值为False
x = torch.tensor(np.arange(4,dtype=np.float32).reshape(2,2),requires_grad=True) # 初始化参数x并设置requires_grad=True用来追踪其计算历史
print(x)
print(x.grad_fn)
"""
tensor([[0., 1.],
[2., 3.]], requires_grad=True)
None
"""
y = x + 2 # 加法
print(y)
"""
tensor([[2., 3.],
[4., 5.]], grad_fn=<AddBackward0>)
"""
z = 3 * y.pow(2) # 乘法及平方
print(z)
"""
tensor([[12., 27.],
[48., 75.]], grad_fn=<MulBackward0>)
"""
out = z.mean() # 求均值
out
"""
tensor(40.5000, grad_fn=<MeanBackward0>)
"""
从上述代码可以看出:
- x的requires_grad属性为True
- 之后的每次计算都会修改其
grad_fn属性,用来记录做过的操作
- 通过这个函数和grad_fn能够组成一个和前一小节类似的计算图
2. 反向传播梯度计算与计算图节点属性转换
2.1反向传播梯度计算
对于1.2 中的out而言,我们可以使用
backward方法来进行反向传播,计算梯度
out.backward(),此时便能够求出导数 d o u t d x \frac{d out}{dx} dxdout,调用x.gard能够获取导数值
得到:tensor([[3.0000, 4.5000], [6.0000, 7.5000]])因为:
d ( O ) d ( x i ) = 3 2 ( x i + 2 ) \frac{d(O)}{d(x_i)} = \frac{3}{2}(x_i+2) d(xi)d(O)=23(xi+2)
在 x i x_i xi等于1时其值为4.5
在 x i x_i xi等于1时其值为4.5
在 x i x_i xi等于2时其值为6.0
在 x i x_i xi等于3时其值为7.5
注意:在输出为一个标量的情况下,我们可以调用输出
tensor的backword()方法,但是在数据是一个向量的时候,调用backward()的时候还需要传入其他参数。
很多时候我们的损失函数都是一个标量,所以这里就不再介绍损失为向量的情况。
loss.backward()就是根据损失函数,对参数(requires_grad=True)的去计算他的梯度,并且把它累加保存到x.gard,此时还并未更新其梯度
out.backward() # 反向传播
# z.backward() # 当不是标量进行反向传播时,需要传入一些参数,否则会报错
x.grad # 注意梯度会累加,所以每次反向传播前梯度要清零
"""
tensor([[3.0000, 4.5000],
[6.0000, 7.5000]])
"""
2.2 tensor.data与tensor.numpy()
注意点:
tensor.data:
- 在
tensor的require_grad=False,tensor.data和tensor等价require_grad=True时,tensor.data仅仅是获取tensor中的数据tensor.numpy():
require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
a = torch.ones(2, 2) # 在tensor的require_grad=False,tensor.data和tensor等价
a = a + 2
print(a)
print(a.data)
"""
tensor([[3., 3.],
[3., 3.]])
tensor([[3., 3.],
[3., 3.]])
"""
a = torch.ones(2,2,requires_grad=True) # require_grad=True时,tensor.data仅仅是获取tensor中的数据
b = a + 2
print(b)
b = a.data + 2
print(b)
"""
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
tensor([[3., 3.],
[3., 3.]])
"""
a = torch.ones(2,2,requires_grad=True)
print(a)
a.data = a.data + 2 # tensor.data是浅拷贝,获取数据内容,不带grad等属性
print(a)
"""
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[3., 3.],
[3., 3.]], requires_grad=True)
"""
a = torch.ones(2,2)
print(a.numpy())
"""
[[1. 1.]
[1. 1.]]
"""
a = torch.ones(2,2,requires_grad=True)
# print(a.numpy()) # 报错
a = torch.ones(2,2,requires_grad=True)
print(a.detach().numpy())
"""
[[1. 1.]
[1. 1.]]
"""
3. 线性回归实现
下面,我们使用一个自定义的数据,来使用torch实现一个简单的线性回归
假设我们的基础模型就是
y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8,分为下面步骤:
- 1、准备数据
- 2、计算预测值
- 3、计算损失,把参数的梯度置为0,进行反向传播
- 反向传播的loss.backward()梯度实际计算方式如下
∂ J ∂ W j = 1 m ∑ i = 1 m ( y ( i ) − ( W T x ( i ) + b ) ) ⋅ ( − x j ( i ) ) ∂ J ∂ b = − 1 m ∑ i = 1 m ( y ( i ) − ( W T x ( i ) + b ) ) \frac{\partial J}{\partial W_{j}}=\frac{1}{m} \sum_{i=1}^{m}\left(y^{(i)}-\left(W^{T} x^{(i)}+b\right)\right) \cdot\left(-x_{j}^{(i)}\right) \\ \frac{\partial J}{\partial b}=-\frac{1}{m} \sum_{i=1}^{m}\left(y^{(i)}-\left(W^{T} x^{(i)}+b\right)\right) ∂Wj∂J=m1i=1∑m(y(i)−(WTx(i)+b))⋅(−xj(i))∂b∂J=−m1i=1∑m(y(i)−(WTx(i)+b))
- 4、更新参数
import torch
import matplotlib.pyplot as plt
# 1、准备数据集即样本和标签、设置学习率
x = torch.rand([50, 1])
y_true = x * 3 + 0.8
learning_rate = 0.01
# 2、初始化参数
w = torch.rand([1, 1], dtype=torch.float32, requires_grad=True)
b = torch.tensor(0., requires_grad=True)
for i in range(5000):
# 3、利用参数预测结果
y_predict = torch.matmul(x, w)+b
# 4、利用标签和预测结果计算损失函数,并反向传播,注意反向传播前若参数梯度不为0需要置零避免梯度累加
loss = (y_true-y_predict).pow(2).mean()
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward()
# 5、梯度下降法更新参数
w.data -= learning_rate * w.grad
b.data -= learning_rate * b.grad
if not(i % 200):
print("w,b,loss:", w.item(), b.item(), loss.item())
# 6、可视化
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1), color='red')
y_predict = torch.matmul(x, w)+b
plt.plot(x.numpy().reshape(-1),
y_predict.detach().numpy().reshape(-1), color='blue')
plt.show()
图形效果如下:
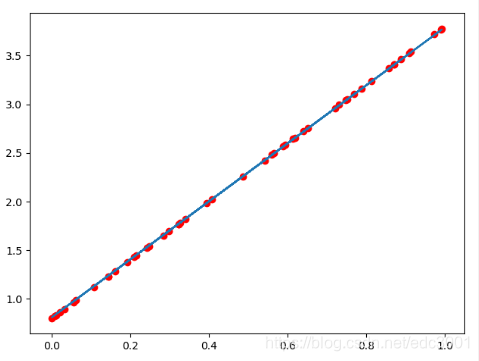
打印的最后一行w,b,loss,可有
w,b,loss: 2.9965360164642334 0.8019797205924988 9.723277116790996e-07可知,w和b已经非常接近原来的预设的3和0.8














 6788
6788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









