









作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[Pytorch系列-21]:Pytorch基础 - 全自动链式求导backward_文火冰糖(王文兵)的博客-CSDN博客
目录
第一章 Pytorch自动求导的两种方法
Pytorch有两种方式进行自动求导。
1.1 半自动
这种方法,使用torch的全局函数,需要指定求导的函数以及相应的偏导数对象。
步骤1:y = wx + b
步骤2:dy = torch.autograd.grad(y, [w,b], retain_graph=True)
备注:这种方式获得的梯度,直接通过函数返回,并没有存放到w,b的tensor中。
详见:
[Pytorch系列-20]:Pytorch基础 - Varialbe变量的手工求导和半自动链式求导torch.autograd.grad_文火冰糖(王文兵)的博客-CSDN博客
1.2 全自动
这种方法,使用输出tensor的成员函数,不需要指定偏导数对象,它对函数中所有的表示了requires_grad=True的参数,自动全部求导。
步骤1:y = wx + b
步骤2:y.backward(retain_graph=True)
备注:这种方式获得的梯度,自动存放在w和b的tensor中。
第2章 自动求导的基本原理
2.1 自动链式求导的基本原理

2.2 前向计算数据流图与反向链式求导数据流图
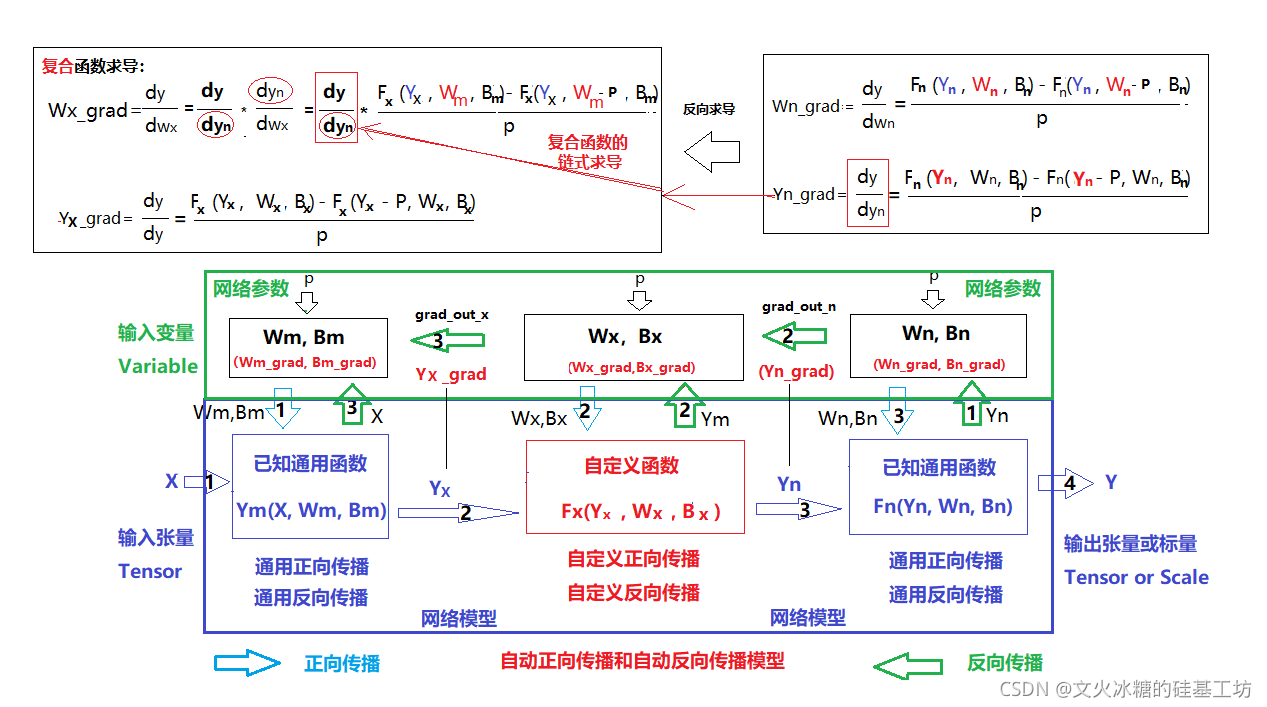
2.3 万能的数值求导的方法
[数值计算-19]:万能的任意函数的数值求导数方法_文火冰糖(王文兵)的博客-CSDN博客
2.4 自动求导关键代码的隐含操作!!!!
关键代码1(自动构建计算图):y = wx + b
- 自动创建前向传播的动态计算图
- 自动创建反向传播的动态计算图和上下文
关键代码2(半自动求导):dy = torch.autograd.grad(y, [w,b], retain_graph=True)
- 只对计算图中,指定的变量列表[ ] 进行求导
- 自动求导的最终输出结果,保放在dy中。
- 自动求导的中间输出结果,保存在y所指定的动态计算图以及自动求导的上下文中。
- 本次自动求导结束后,如果retain_graph=True,则保留、不释放由y指定的动态计算图以及上下文。
- 本次自动求导结束后,如果retain_graph=False,自动释放由y指定的动态计算图以及上下文。
关键代码3(全自动求导):y.backward(retain_graph=True)
- 对计算图中,标志位requires_grad = True的所有tensor/variable进行搜索并自动求导。
- 自动求导的最终输出结果,自动保放tensor/variabl各自对应的grad属性中。
- 自动求导的中间输出结果,保存在y所指定的动态计算图以及自动求导的上下文中。
- 本次自动求导结束后,如果retain_graph=True,则保留、不释放由y指定的动态计算图以及上下文。
- 本次自动求导结束后,如果retain_graph=False,自动释放由y指定的动态计算图以及上下文。
第3章 Variable对象的全自动链式求导案例
3.1 定义支持全自动求导的 Variable对象
print("自变量:张量tensor => 自变量值")
x_variable = Variable(torch.Tensor([0]), requires_grad = True)
print("x_variable =", x_variable)自变量:张量tensor => 自变量值 x_variable = tensor([0.], requires_grad=True)
3.2 一元函数全自动求导
# 一元函数全自动求导
# 自动求导只能在某一个点,如一元点(x)处一次自动求导,不能对一个点序列进行多次的连续自动求导
print("自变量:张量tensor => 自变量值")
x_variable = Variable(torch.Tensor([0]), requires_grad = True)
print("x_variable =", x_variable)
print("\n因变量:一元原函数 => 函数值")
y_variable = x_variable ** 2 + 1
print("y_variable =", y_variable)
print("\n因变量:自动求导前 => 导数值")
print("x_variable =", x_variable)
print("x_variable.grad =", x_variable.grad)
print("\n对原函数的所有变量分别自动求偏导(通过系统提供的backward()成员函数)")
y_variable.backward()
print("\n因变量:自动求导后 => 导数值 ")
print("x_variable =", x_variable)
print("x_variable.grad =", x_variable.grad)自变量:张量tensor => 自变量值 x_variable = tensor([0.], requires_grad=True) 因变量:一元原函数 => 函数值 y_variable = tensor([1.], grad_fn=<AddBackward0>) 因变量:自动求导前 => 导数值 x_variable = tensor([0.], requires_grad=True) x_variable.grad = None 对原函数的所有变量分别自动求偏导(通过系统提供的backward()成员函数) 因变量:自动求导后 => 导数值 x_variable = tensor([0.], requires_grad=True) x_variable.grad = tensor([0.])
3.3 二元函数全自动求导案例
# 二元函数全自动求导
# 自动求导只能在某一个点,如二元点(x1,x2)处一次自动求导,不能对一个点序列进行多次的连续自动求导
print("自变量:张量tensor => 自变量值")
x_variable1 = Variable(torch.Tensor([-1]), requires_grad = True)
x_variable2 = Variable(torch.Tensor([1]), requires_grad = True)
print("x_variable1 =", x_variable1)
print("x_variable2 =", x_variable2)
print("\n因变量:二元原函数 => 函数值")
y_variable = x_variable1**2 + x_variable2**2 + 1
print("y_variable =", y_variable)
print("\n因变量:自动求导前 => 导数值")
print("x_variable1 =", x_variable1)
print("x_variable1.grad =", x_variable1.grad)
print("x_variable2 =", x_variable2)
print("x_variable2.grad =", x_variable2.grad)
print("\n对原函数的所有变量分别自动求偏导(通过系统提供的backward()成员函数)")
y_variable.backward()
print("\n因变量:自动求导后 => 导数值 ")
#获取导数值
print("x_variable1 =", x_variable1)
print("x_variable1.grad =", x_variable1.grad)
print("x_variable2 =", x_variable2)
print("x_variable2.grad =", x_variable2.grad)
自变量:张量tensor => 自变量值 x_variable1 = tensor([-1.], requires_grad=True) x_variable2 = tensor([1.], requires_grad=True) 因变量:二元原函数 => 函数值 y_variable = tensor([3.], grad_fn=<AddBackward0>) 因变量:自动求导前 => 导数值 x_variable1 = tensor([-1.], requires_grad=True) x_variable1.grad = None x_variable2 = tensor([1.], requires_grad=True) x_variable2.grad = None 对原函数的所有变量分别自动求偏导(通过系统提供的backward()成员函数) 因变量:自动求导后 => 导数值 x_variable1 = tensor([-1.], requires_grad=True) x_variable1.grad = tensor([-2.]) x_variable2 = tensor([1.], requires_grad=True) x_variable2.grad = tensor([2.])
3.4 梯度的自动累加现象
Pytorch全自动求导backward,有一个很奇特的现象:即每一次计算,都会在原有的梯度的基础之上,叠加上最新的导数值,导致每个参数变的梯度值不断的累加,如下所示:
# 梯度自动累加:即使点的位置没有变化,每次计算出来的梯度值是累加的。
x_variable = Variable(torch.Tensor([1]), requires_grad = True)
print("x_variable =", x_variable)
print("x_variable.grad = ", x_variable.grad)
y_variable = x_variable ** 2 + 1
print("y_variable=", y_variable)
# 自动求导
count = 5
while(count):
print("\n", count)
y_variable.backward(retain_graph=True)
y_variable = x_variable ** 2 + 1
print("x_variable=", x_variable)
print("y_variable=", y_variable)
print("x_variable.grad = ", x_variable.grad)
count = count - 1x_variable = tensor([1.], requires_grad=True) x_variable.grad = None y_variable= tensor([2.], grad_fn=<AddBackward0>) 5 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.]) 4 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([4.]) 3 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([6.]) 2 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([8.]) 1 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([10.])
3.5 梯度的清零操作:data.zero_()
在实际使用中,梯度的自动累加功能,并不是我们所期望的,这就需要在每次全自动求导后,
要对梯度进行手工清零:data.zero_()。
# 梯度自动累加
x_variable = Variable(torch.Tensor([1]), requires_grad = True)
print("x_variable =", x_variable)
print("x_variable.grad = ", x_variable.grad)
y_variable = x_variable ** 2 + 1
print("y_variable=", y_variable)
# 自动求导
count = 5
while(count):
print("\n", count)
y_variable.backward(retain_graph=True)
y_variable = x_variable ** 2 + 1
print("x_variable=", x_variable)
print("y_variable=", y_variable)
print("x_variable.grad = ", x_variable.grad)
count = count - 1
#清除x_variable以前的梯度值
x_variable.grad.data.zero_()x_variable = tensor([1.], requires_grad=True)
x_variable.grad = None
y_variable= tensor([2.], grad_fn=<AddBackward0>)
5
x_variable= tensor([1.], requires_grad=True)
y_variable= tensor([2.], grad_fn=<AddBackward0>)
x_variable.grad = tensor([2.])
4
x_variable= tensor([1.], requires_grad=True)
y_variable= tensor([2.], grad_fn=<AddBackward0>)
x_variable.grad = tensor([2.])
3
x_variable= tensor([1.], requires_grad=True)
y_variable= tensor([2.], grad_fn=<AddBackward0>)
x_variable.grad = tensor([2.])
2
x_variable= tensor([1.], requires_grad=True)
y_variable= tensor([2.], grad_fn=<AddBackward0>)
x_variable.grad = tensor([2.])
1
x_variable= tensor([1.], requires_grad=True)
y_variable= tensor([2.], grad_fn=<AddBackward0>)
x_variable.grad = tensor([2.])3.6 数据图的手工重选构建
在上面的案例中,每次进行全自动求导时,都会设置retain_graph=True,如:
y_variable.backward(retain_graph=True)
设置该标志位的原因是:Pytorch是动态构建数据图,每一次被调用,执行自动求导前,都会重选构建反向求导的数据图和上下文,执行完自动求导后,都会释放相应数据图和上下文。
为了能够进行多次迭代求导,执行万一次自动求导后,需要保留数据图和上下文,这就是这个标志位的作用。但这种方法的缺点是,最后的数据图和上下文需要手工释放。
为了克服上述缺点,也可以有采用另一种方法:
在每次自动求导前,手工构建数据图和上下文,自动求导后,由backward自动释放。
# 重选构建数据图和自动求导的上下文
y_variable = x_variable ** 2 + 1
# 执行自动求导,自动释放自动求导的上下文
y_variable.backward()
其作用与y_variable.backward(retain_graph=True) 是相似的,但程序迭代后,不需要手工释放自动求导的上下文。
详细代码如下:
# 梯度自动累加
x_variable = Variable(torch.Tensor([1]), requires_grad = True)
print("x_variable =", x_variable)
print("x_variable.grad = ", x_variable.grad)
y_variable = x_variable ** 2 + 1
print("y_variable=", y_variable)
# 自动求导
count = 5
while(count):
print("\n", count)
# 重选构建数据图和自动求导的上下文
y_variable = x_variable ** 2 + 1
# 执行自动求导,自动释放自动求导的上下文
y_variable.backward()
y_variable = x_variable ** 2 + 1
print("x_variable=", x_variable)
print("y_variable=", y_variable)
print("x_variable.grad = ", x_variable.grad)
count = count - 1
#清除x_variable以前的梯度值
x_variable.grad.data.zero_()x_variable = tensor([1.], requires_grad=True) x_variable.grad = None y_variable= tensor([2.], grad_fn=<AddBackward0>) 5 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.]) 4 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.]) 3 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.]) 2 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.]) 1 x_variable= tensor([1.], requires_grad=True) y_variable= tensor([2.], grad_fn=<AddBackward0>) x_variable.grad = tensor([2.])
3.7 全自动求导的应用:梯度下降迭代
(1)迭代过程
print("定义迭代的自变量参数以及初始值")
x1_variable = Variable(torch.Tensor([2]), requires_grad = True)
x2_variable = Variable(torch.Tensor([2]), requires_grad = True)
print("x1_variable =", x1_variable)
print("x2_variable =", x2_variable)
# 定义原函数
def loss_fun(x1, x2):
y = x1**2 + x2**2 + 1
return (y)
# 获取y初始值
y_variable = loss_fun (x1_variable, x2_variable)
print("y_variable =", y_variable)
#定义学习率
learnning_rate = 0.1
#定义迭代次数
iterations = 30
#定义存放迭代过程数据的列表
x1_data = []
x2_data = []
y_data = []
# 保存初始值:需转换成numpy,便于matlab可视化
x1_data.append(x1_variable.data.numpy())
x2_data.append(x2_variable.data.numpy())
y_data.append(y_variable.data.numpy())
print("\n初始点:", x1_data[0], x2_data[0], y_data[0])
while(iterations):
# 对任意函数在当前位置求导数
y_variable.backward()
# 梯度下降迭代
x1_variable.data = x1_variable.data - learnning_rate * x1_variable.grad
x2_variable.data = x2_variable.data - learnning_rate * x2_variable.grad
#计算当前最新的y值
y_variable = loss_fun (x1_variable, x2_variable)
#保存数据
x1_data.append(x1_variable.data.numpy())
x2_data.append(x2_variable.data.numpy())
y_data.append(y_variable.data.numpy())
#下次迭代做准备
iterations = iterations -1
x1_variable.grad.data.zero_()
x2_variable.grad.data.zero_()
print("\n迭代后的数据:")
print("x1_variable =", x1_variable.data.numpy())
print("x2_variable =", x2_variable.data.numpy())
print("y_variable =", y_variable.data.numpy())
定义迭代的自变量参数以及初始值 x1_variable = tensor([2.], requires_grad=True) x2_variable = tensor([2.], requires_grad=True) y_variable = tensor([9.], grad_fn=<AddBackward0>) 初始点: [2.] [2.] [9.] 迭代后的数据: x1_variable = [0.00247588] x2_variable = [0.00247588] y_variable = [1.0000123]
(2)迭代过程的可视化
fig = plt.figure()
ax1 = plt.axes(projection='3d') #使用matplotlib.pyplot创建坐标系
ax1.scatter3D(x1_data, x2_data, y_data, cmap='Blues') #绘制三维散点图
plt.show()
(3)原函数的可视化
# 可视化原函数的图形
x1_sample = np.arange(-10, 10, 1)
x2_sample = np.arange(-10, 10, 1) #X,Y的范围
x1_grid, x2_grid = np.meshgrid(x1_sample,x2_sample) #空间的点序列转换成网格点
y_grid = loss_fun(x1_grid,x2_grid) #生成z轴的网格数据
figure = plt.figure()
ax1 = plt.axes(projection='3d') #创建三维坐标系
ax1.plot_surface(x1_grid, x2_grid, y_grid ,rstride=1,cstride=1,cmap='rainbow')
第4章 Tensor对象的全自动该链式求导拆解
4.1 环境准备
#环境准备
import numpy as np
import math
import matplotlib.pyplot as plt
%matplotlib inline
import torch
from torch.autograd import Variable
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())4.2 Variable对象与Tensor对象的统一
print("定义样本tensor")
x = torch.Tensor([2.])
y = torch.Tensor([2.])
print("定义参数tensor")
w = torch.Tensor([1.])
b = torch.tensor([1.], requires_grad=True) # 使能自动梯度计算方法1
print(x)
print(w)
print(b)
print("\n使能tensor的梯度属性,替代variable变量")
w.requires_grad_() # 使能自动梯度计算方法2
print(w)
print(b)
print("\n生成loss函数的动态数据流图")
f_pred = w * x + b
loss = (f_pred - y)**2
print("\n自动计算梯度")
torch.autograd.grad(loss, [w,b], retain_graph=True)
print(loss)
print(w.grad) #autograd.grad的计算结果被函数返回,并为存放到w和b的grad参数中!!!
print(b.grad)
print("\n生成loss函数的动态数据流图")
f_pred = w * x + b
loss = (f_pred - y)**2
print("自动反向求梯度")
loss.backward()
print(loss)
print(w.grad)
print(b.grad)定义样本tensor 定义参数tensor tensor([2.]) tensor([1.]) tensor([1.], requires_grad=True) 使能tensor的梯度属性,替代variable变量 tensor([1.], requires_grad=True) tensor([1.], requires_grad=True) 生成loss函数的动态数据流图 自动计算梯度 tensor([1.], grad_fn=<PowBackward0>) None None 生成loss函数的动态数据流图 自动反向求梯度 tensor([1.], grad_fn=<PowBackward0>) tensor([4.]) tensor([2.])
4.3 定义支持自动求导的tensor
print("定义样本数据")
x = torch.Tensor([1])
print("\n定义参数tensor")
w2 = torch.tensor([4.], requires_grad=True)
b2 = torch.tensor([5.], requires_grad=True)
w1 = torch.tensor([2.], requires_grad=True)
b1 = torch.tensor([3.], requires_grad=True)
print("w2=", w2)
print("b2=", b2)
print("w1=", w1)
print("b1=", b1)
定义样本数据 定义参数tensor w2= tensor([4.], requires_grad=True) b2= tensor([5.], requires_grad=True) w1= tensor([2.], requires_grad=True) b1= tensor([3.], requires_grad=True)
备注,在最新的pytorch中,Varialbe对象以及与tensor对象进行完美的整合与统一。
因此使用tensor对象来替代Varialbe对象。
4.4 定义复合函数
print("\n定义一级函数")
y1 = w1 * x + b1
print("y1=", y1)
print("\n定义二级函数")
y2 = w2 * y1 + b2
print("y2=", y2)
定义一级函数 y1= tensor([5.], grad_fn=<AddBackward0>) 定义二级函数 y2= tensor([25.], grad_fn=<AddBackward0>)
4.5 全自动求导(求梯度)
print("\n(1)全过程自动链式求导")
y2.backward(retain_graph=True)
print("w1.grad=", w1.grad)
print("b1.grad=", b1.grad)
print("w2.grad=", w2.grad)
print("b2.grad=", b2.grad)
(1)全过程自动链式求导 w1.grad= tensor([4.]) b1.grad= tensor([4.]) w2.grad= tensor([5.]) b2.grad= tensor([1.])
4.6 指定函数链自动求导
print("\n(2)指定链自动链式求导")
dy2_dw1 = torch.autograd.grad(y2, [w1], retain_graph=True)[0]
dy2_db1 = torch.autograd.grad(y2, [b1], retain_graph=True)[0]
dy2_dw2 = torch.autograd.grad(y2, [w2], retain_graph=True)[0]
dy2_db2 = torch.autograd.grad(y2, [b2], retain_graph=True)[0]
print("dy2_dw1=", dy2_dw1)
print("dy2_db1=", dy2_db1)
print("dy2_dw2=", dy2_dw2)
print("dy2_db2=", dy2_db2)
(2)指定链自动链式求导 dy2_dw1= tensor([4.]) dy2_db1= tensor([4.]) dy2_dw2= tensor([5.]) dy2_db2= tensor([1.])
4.7 用半自动求导分解全自动求导过程
print("\n(3)分步式自动链式求导")
dy2_dw2 = torch.autograd.grad(y2, [w2], retain_graph=True)[0]
dy2_db2 = torch.autograd.grad(y2, [b2], retain_graph=True)[0]
print("dy2_dw2=", dy2_dw2)
print("dy2_db2=", dy2_db2)
print("")
dy2_dy1 = torch.autograd.grad(y2, [y1], retain_graph=True)[0]
print("dy2_dy1=", dy2_dy1)
dy1_dw1 = torch.autograd.grad(y1, [w1], retain_graph=True)[0]
dy1_db1 = torch.autograd.grad(y1, [b1], retain_graph=True)[0]
print("dy1_dw1=", dy1_dw1)
print("dy1_db1=", dy1_db1)
print("")
print("dy2_dw1=", dy2_dy1 * dy1_dw1)
print("dy2_db1=", dy2_dy1 * dy1_db1)(3)分步式自动链式求导 dy2_dw2= tensor([5.]) dy2_db2= tensor([1.]) dy2_dy1= tensor([4.]) dy1_dw1= tensor([1.]) dy1_db1= tensor([1.]) dy2_dw1= tensor([4.]) dy2_db1= tensor([4.])
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[Pytorch系列-21]:Pytorch基础 - 全自动链式求导backward_文火冰糖(王文兵)的博客-CSDN博客
















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











