






前言
代码学习记录
参考书籍《利用Python进行数据分析》第14章 数据分析示例
一、数据集简介
短网址运营商Bitly与美国政府网站合作,提供从以.gov和.mil结尾的短网址的用户手机的匿名数据。
二、数据分析
1.查看/读取数据
每一行的数据其实是json形式(JavaScript Object Notation)
阅读第一行可得到:
path = 'bitly_usagov.txt'
line1 = open(path).readline()
print(line1) #第一行数据示例

通过json模块以及loads函数将数据变为字典的列表
records = [json.loads(line) for line in open(path)]
print(records[0])
2.纯Python标准库 时区计数
选取数据中的时区信息进行数据分析
time_zones=[rec['tz'] for rec in records]
print(time_zones)
得到结果为:

可以从输出结果看出,部分数据组中缺失时区,所以需要在选取时区之前筛查一下
time_zones=[rec['tz'] for rec in records if 'tz' in rec]
print(time_zones)

引用Python基本库,并构造函数进行计数。并选取个数最多的10项时区。
from collections import defaultdict
def get_counts(sequence):
counts = defaultdict(int) #初始化
for x in sequence:
counts[x]+=1
return counts
counts=get_counts(time_zones)
print(counts['America/New_York'])
print(len(time_zones))
def top_counts(count_dict,n=10): #取前n多的时区数据
value_key_pairs =[(count,tz) for tz,count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
print(top_counts(counts))

也有更加简便的方式:引用collections.Counter类
from collections import Counter #counter类
counts=Counter(time_zones)
print(counts.most_common(10))
同样可以得到个数最多的几项时区

3.使用pandas库 时区计数
通过pandas库先转化为frame
import pandas as pd
frame=pd.DataFrame(records)
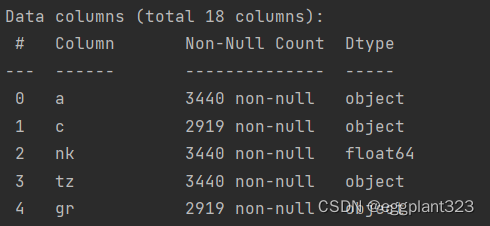
print(frame.info())
部分frame信息:
value_counts() 方法返回一个序列 Series,该序列包含每个值的数量。也就是说,对于数据框中的任何列,value-counts () 方法会返回该列每个项的计数。value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用。value_Coutn只能对应series,不能直接对整个dataframe做操作。
可以利用value_counts()进行排序
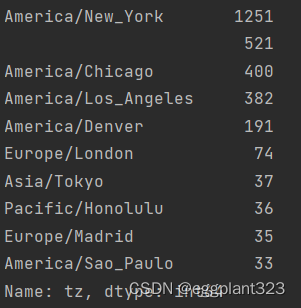
tz_counts= frame['tz'].value_counts()
print(tz_counts[:10])
填充空白数据内容,方便数据可视化流程
clean_tz=frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] ='Unknown'
tz_counts2=clean_tz.value_counts()
print(tz_counts2[:10])
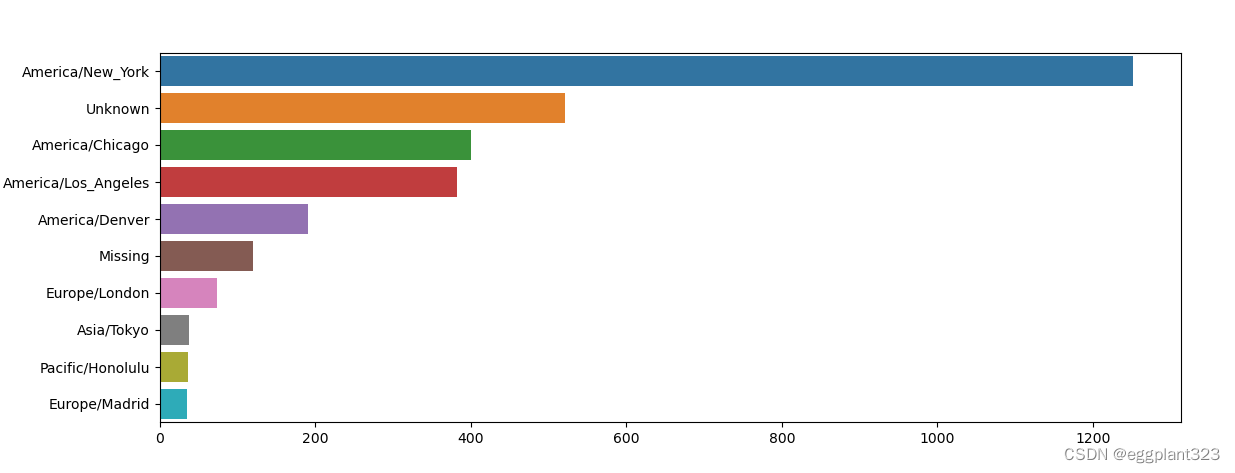
利用seaborn包进行绘图,柱状图
import seaborn as sns
import matplotlib.pyplot as plt
subset = tz_counts2[:10]
sns.barplot(y=subset.index,x=subset.values)
plt.show()
4.参考其他维度的时区分析
参考浏览器信息
利用pd.Series(结果为一维数组):pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
dropna 删除数据为nan的数据
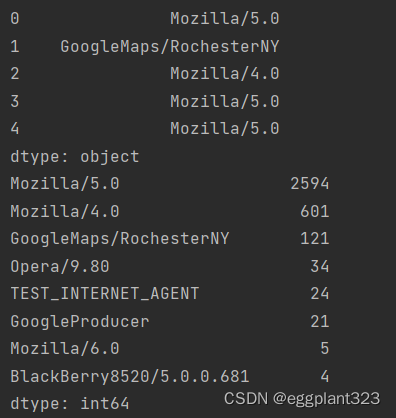
results = pd.Series([x.split()[0] for x in frame.a.dropna()])
print(results[:5])#前5行数据
print(results.value_counts()[:8])#数量上前8数据
得到相对应的结果为
通过是否为Windows用户进行另一个维度区分
cframe为‘a’列中并非为空的列表
import numpy as np
cframe =frame[frame.a.notnull()]
cframe['os']= np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
print(cframe['os'][:5])
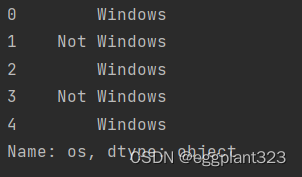
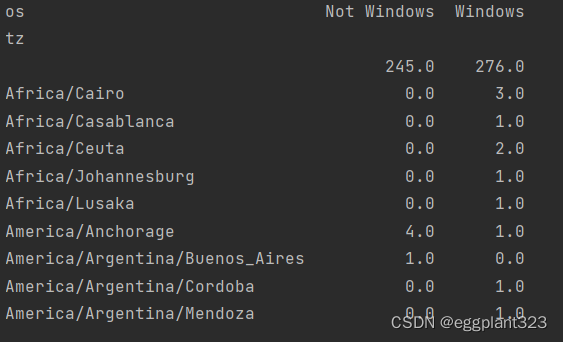
根据两个维度进行分类排序
unstack()函数 可以使得通过列名进行分类
by_tz_os = cframe.groupby(['tz','os'])
agg_counts = by_tz_os.size().unstack().fillna(0)
print(agg_counts[:10])
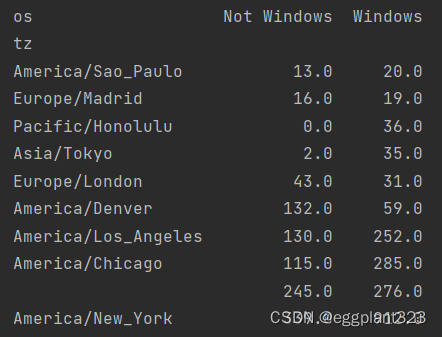
针对每一个时区进行用户排序,需要考虑是否为windows用户。可以在其中增添一个(升序排列)
indexer=agg_counts.sum(1).argsort()
count_subset=agg_counts.take(indexer[-10:])
print(count_subset)
如果采用pandas库的nlargest也可以进行统计、排序工作
print(agg_counts.sum(1).nlargest(10))
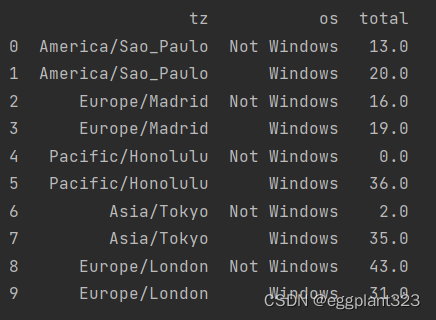
接下来可以将已得到的数据进行可视化操作
count_subset=count_subset.stack()
count_subset.name='total'
count_subset=count_subset.reset_index()
print(count_subset[:10])
sns.barplot(x='total',y='tz',hue='os',data=count_subset)
plt.show()

可以看出这个柱状图最大的问题在于每一个时区数据相差过多,导致图像最后呈现的效果不好
可以对数据进行百分比的划分
def norm_total(group):
group['normed_total']=group.total/group.total.sum()
return group
results=count_subset.groupby('tz').apply(norm_total)
sns.barplot(x='normed_total',y='tz',hue='os',data=results)
plt.show()
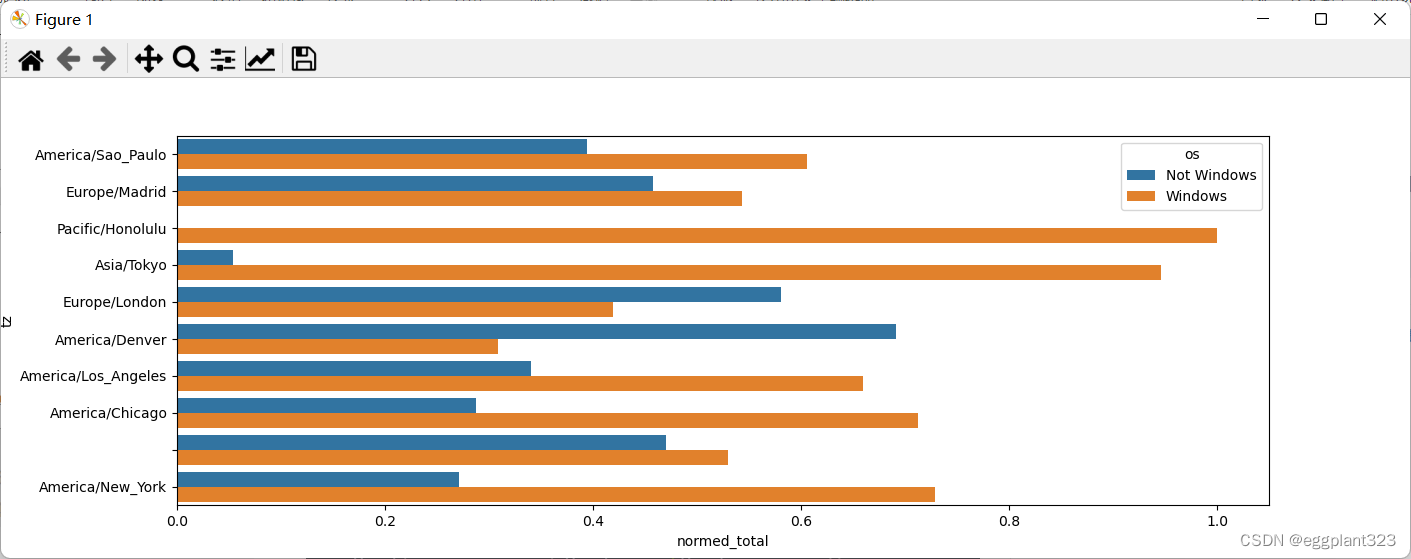
可以得到一个效果更好的可视化图表















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









