







overview
A deep learning approaches in text-to-speech system: a systematic review and recent research perspective
introduction
TTS(文本到语音)合成是一种将书面文本转换为语音的机制。文本到语音合成可以遵循两个主要步骤,即文本分析和语音波形生成。
文本到语音系统的主要组件可能包括:自然语言处理模块,该模块在某些情况下(语调、持续时间、强度或功率)生成输入文本的语音转录和韵律。从NLP(自然语言处理)模块输出的数据由DSP(数字信号处理)模块转换为语音。
评判文本到语音系统的质量是基于不同的阶段,如合成语音的偏好、可懂度、自然度和人类观察因素,如可理解性。
无回归文本到语音试图通过使用现象序列作为输入来建立快速、高质量的语音合成系统。图显示了文本到语音系统包含一组输入语言,包括辅音、元音和音节。
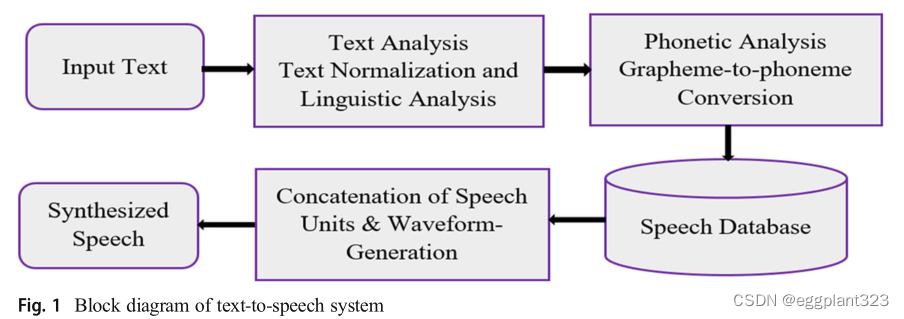
TTS转换有两种技术,即参数TTS和TTS。匹配和深度学习的兴起发现了关于语音合成问题的新观点,其中重点转移到完全匹配人类生成的语音特征的已获得约束。
这种影响是通过练习五个RQ(研究问题)来实现的:RQ1。有哪些不同的自动文本扫描系统?RQ2.语音合成的各种深度学习模型是什么?RQ3,在这一研究领域,文献发展的挑战和局限性是什么?RQ4.从文本到语音的未来前景如何?RQ5.设计不同语言的文本到语音系统面临哪些挑战?
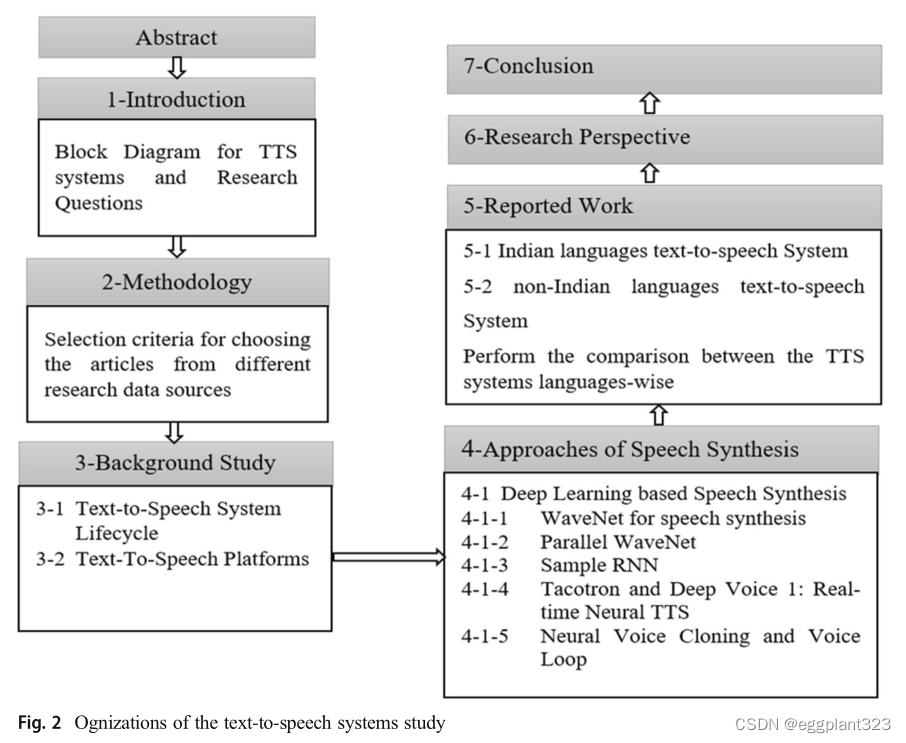
Methodology
PRISMA(系统评价和荟萃分析的首选报告项目)指南已用于进行本次评价。它描述了以下四个步骤的研究程序,即鉴定、筛选、资格和纳入。
据报道,研究的调查文章旨在了解深度学习在不同语言(包括印度语和非印度语)的文本到语音系统以及自动TTS中的研究地位。本研究提出了文本到语音系统以及不同语言中文本到语音的各个维度的进步。
Background study
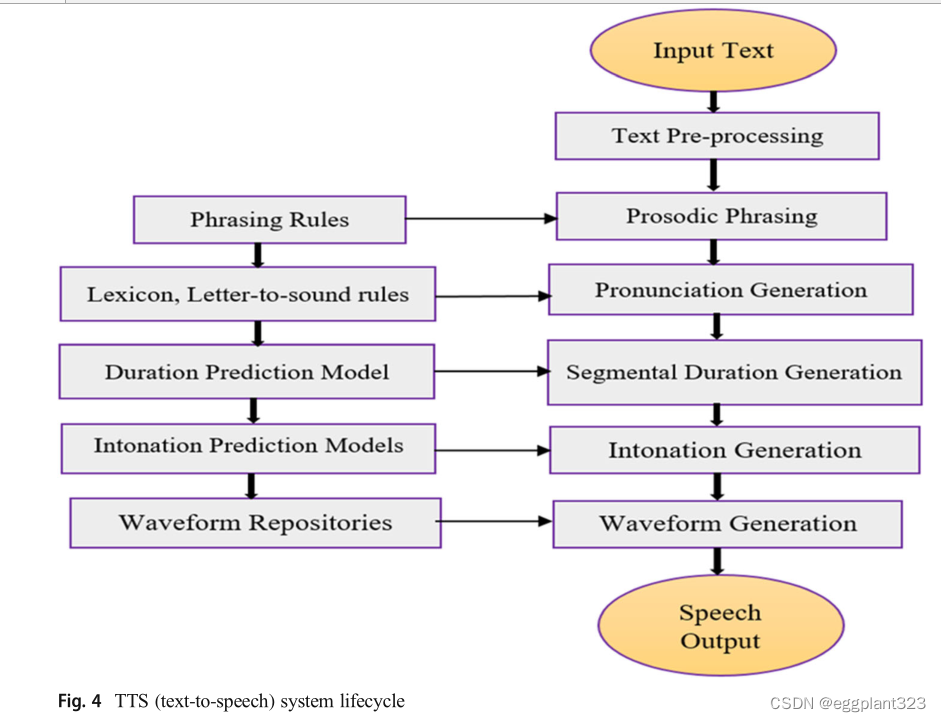
Text-to-speech system life cycle
任何TTS系统都需要讨论的主要挑战是如何从作为输入的纯文本中获得听起来自然的语音。只保留一种语言的所有单词的记录,然后将给定文本中的单词合并以获得合适的语音,是不可能解决这个问题的。TTS系统将输入文本翻译成语音插图,然后帮助获得与这些表示匹配的声音。因为输入是纯文本,所以必须用合成语音中的语调和节奏信息来增强已经生成的语音表示
TTS platforms
TTS(文本到语音)平台也称为语音合成和语音生成,用户可以通过API将合成语音添加到其网站或应用程序中。
Approaches of speech synthesis
如图5所示,经典语音合成方法大致分为两类,如规则驱动方法和数据驱动方法。规则驱动技术重现与人类语音系统产生的声音相似的声音,并进一步分类为格式语音合成和发音参数语音合成[25103]。另一方面,数据驱动的方法通过以定义良好的方式组合它们来产生语音,并被进一步分类为级联语音合成和统计参数语音合成,这两种方法再次被分类为两种,即单元选择语音合成和基于HMM的语音合成,有助于具有大量频谱、情景、,以及韵律特征,在广泛的数据库的支持下,这些特征非常有用,看起来更接近人类语音
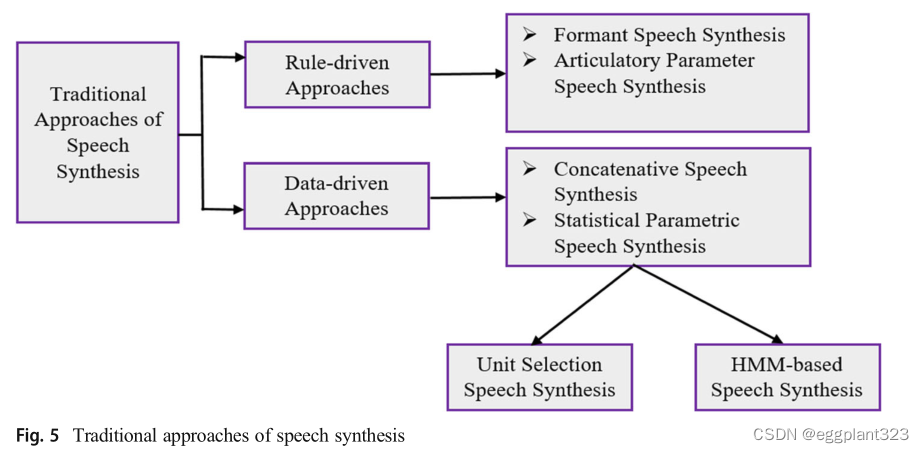
语音合成的主要技术之一是Formant语音合成。如前所述,该模型建立在规则驱动的语音合成技术上,该技术允许语音通道充当繁荣的裂缝和共振峰谐振器。它提供共振峰的振幅和共振峰的频率,并有助于生成语音。此外,它的计算可以很容易地在移动计算和各种嵌入式设备中使用,并且占用更少的内存。
但另一方面,它也存在一些缺点,如语音质量取决于各种参数的选择和设置,由于自然语言的复杂性,真实语音的差异性较差
Deep learning based speech synthesis
深度学习建模已被证明是数据最有效的学习特征之一。
这些使该模型高效的功能对人类来说可读性较差,但更容易阅读[50]。在深度学习模型中,数据的表示要好得多。以另一种方式,它可以将深度学习模型作为在输入X和输出Y之间映射的函数来关联
WaveNet for speech synthesis
WaveNet在存储各种图像、手写、视频、文本、音乐和人类语音方面取得了许多胜利。WaveNet有助于对原始音频信号进行建模,可以将其归类为极限形式的自回归,范围高达每秒24000个样本。在WaveNet的工作中,TTS系统将输入X保持为与文本相关的字符串,音频波形可以算作输出Y。该模型的主要特点是通过将音频波形数字化来获得语音信号。如图6所示,音频样本的时间序列对于直接生成语音样本至关重要。WaveNet的原始工作由DeepMind完成。WaveNet生成音频样本,并且每个样本都要检查音频中生成的先前样本。 先前的样本然后使用该样本来生成下一个样本,如等式1所示。这个过程被称为自回归生成。
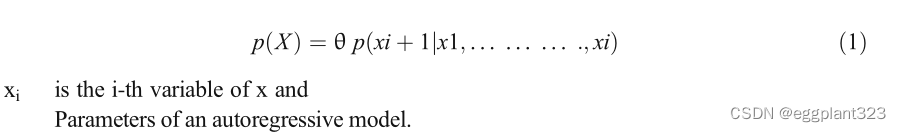 WaveNet是用卷积层创建的,如图7所示。WaveNet从数字化的原始音频波形中获取输入,这些波形流经这些卷积层并输出波形样本
WaveNet是用卷积层创建的,如图7所示。WaveNet从数字化的原始音频波形中获取输入,这些波形流经这些卷积层并输出波形样本
该模型不受条件限制,这表明该模型不提供与语音结构相关的信息。因此,不会生成有意义的音频。如果使用人类的语音音频进行训练,产生的声音似乎与人类说话相似,但实际上,单词会抖动或暂停。WaveNet团队通过将来自预先存在的TTS系统的声码器约束作为不同的输入和原始音频输入来帮助对该模型进行建模[97100]。在所产生的文本到语音系统的帮助下,为用户获得了高质量的语音。然而,这种模式成本高昂。一个有资格成为最好的语音必须至少有40个卷积层。为了产生1秒的16kHz音频,它需要16000个样本处理。通常需要4分钟才能产生1秒的音频,这在当今的技术中是不可接受的。为了避免这样的问题,百度深度语音准备的WaveNet比以前快了400倍。
Parallel WaveNet
WaveNet的卷积性质需要更快的并行训练。样本生成既简单又耗时。因此,需要一种替代体系结构来帮助提供更快的结果。概率密度蒸馏是一种替代架构,有助于为并行前馈网络提供训练,以获得更快的结果。该方法基本上是WaveNet和逆自回归流模型的结合。这有助于提供WaveNet的有效训练。逆自回归流(IAF)模型是一种随机生成模型,它可以同时产生高维识别样本
RNN
递归神经网络是人工神经网络的一个子类,其中节点沿着时间序列连接在有向图中。样本RNN也是用于生成音频样本的方法之一。为了处理这些音频样本,使用了包含不同时钟速率的递归层序列
在一个序列中相互链接的各种RNN。最顶层由大量输入组成,并在流程完成后将其进一步移动到较低级别。这些过程继续到序列中的较低级别,并创建一个特定的样本。经过计算,发现样本RNN的速度需要比Wave Net快500倍。与前馈神经网络不同,递归神经网络处理序列
Tacotron and deep voice 1: real-time neural TTS
文本到语音合成系统包含不同的阶段,包括声学模型、文本分析前端和音频合成模块。构建这些组件需要广泛的领域专业知识。Tacotron(图9)是一个生成的文本到速度模型,本质上是端到端的。它有助于从音频对和文本中生成语音。与样本级自回归方法相比,Tacotron模型由于帧级语音生成而更快。
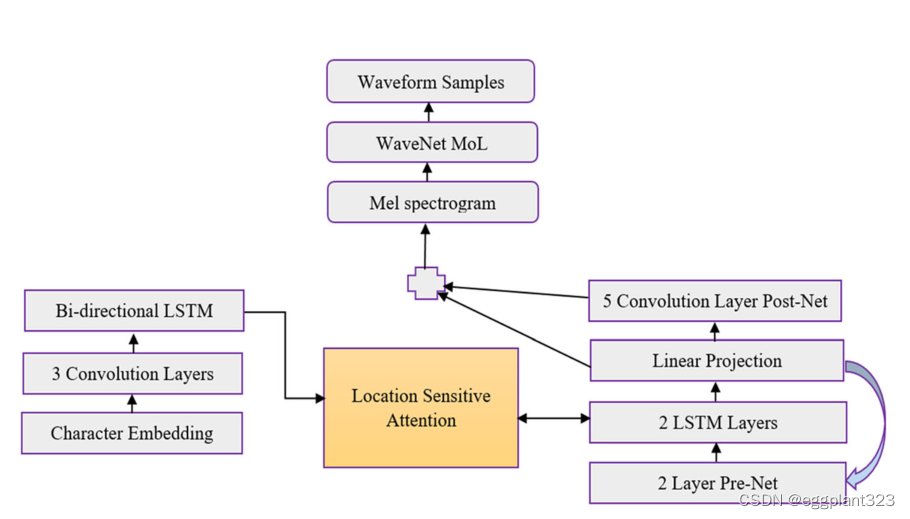
而不需要额外的韵律信息。使用编码器-解码器架构,Tacotron 2模型从输入文本生成声谱图。Wave Glow是一个基于流的模型,通过使用声谱图来生成语音。同时,通过深度神经网络实现了深度语音文本到语音系统。传统的文本到语音管道用于鼓励深度语音,并使用相同的结构用神经网络替换组件。首先,将文本更改为音素,然后使用音频合成模型将语言特征转换为语音。在深层语音文本到语音系统中,使用字形到音素模型将英语字符转换为音素。
Neural voice cloning and voice loop
定制语音接口最流行的方面之一是语音克隆。神经语音克隆系统有助于从几个音频样本中合成一个人的声音。该系统将使用两种主要方法,即说话人自适应和说话人编码[108]。说话人自适应依赖于对多说话人生成模型的微调,而说话人编码依赖于训练单个模型用于直接推断,将新的说话人植入应用于多说话人生成模式。
整个模型在扬声器自适应方面具有更大的灵活性,但针对少量克隆数据对其进行优化要困难得多。初次中止的目的是避免过度拟合。语音循环是通过一种称为语音循环的记忆模型来鼓励的,这种记忆模型有助于在更短的时间内保持语言信息。它包含一个可以不断替换的语音库,以及一个有助于维持语音库中长期表征的试验过程
Discussion
除了TTS技术的潜在进步外,将该技术与其他技术集成可能会取得许多进步。通过在TTS系统的前端添加OCR引擎,用户可以使用可用的神话文档的扫描版本来收听各种印度语言。例如,将语音识别和机器翻译系统结合起来,可能是一项未来的发展,可以让用户用自己的母语说出一个单词。可以生成相同含义的对应发音。
conclusion
我们回顾了最近的调查论文,这些论文使用了各种方法来创建印度语和非印度语的可靠文本到语音系统。长排序术语记忆和其他技术,如级联技术、基于模板的匹配、滋养转发,以及基于机器和深度学习的模型,如线性回归、支持向量机和神经网络(人工神经网络、多层感知器和递归神经网络),对文献做出了重大贡献。然而,基于深度学习的模型在增强所开发的TTS在文本到语音识别率、预测准确性、回忆、准确性和单词错误率方面的功能方面产生了重大影响,这些都是基于双语的方法。















 1532
1532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









