







AC paper : Accent Conversion using Pre-trained Model and Synthesized Data from Voice Conversion
Abstract
口音转换(AC)旨在通过改变源说话者(在源音频中)的发音模式和韵律来生成合成音频,同时保持语音质量和语言内容。目前还没有一个平行的语料库包含具有相同内容但来自不同口音的同一说话者的成对音频,因此作者致力于解决方案,将其中一个合成为训练输入。train流程分两步进行。首先,构造了一个语音转换(VC)模型来合成训练数据集,该训练数据集包含相同语音但两种不同口音的成对音频。其次,用合成数据训练AC模型,以将源口音语音转换为目标口音语音。
鉴于自监督学习语音表示(wav2vec 2.0)在某些语音问题(如VC、语音识别、语音翻译和语音到语音翻译)上取得了公认的成功,我们在第二步中采用了这种经过定制的架构来训练AC模型。仅使用9小时的合成训练数据,由预训练的wav2vec 2.0模型的权重初始化的编码器就优于基于LSTM的编码器。
1. Introduction
AC中的主要挑战是无法获得所需输出的ground-truth数据。先前的解决方案通过在推理时引入目标accent说话人的参考话语来解决这个问题。然而,并不总是能够从这些目标对象获得引用,这限制了该方法的适用性。作为一种替代解决方案,我们提出了一种端到端的AC方法,该方法能够在推理阶段从源重音话语转换重音,而不使用任何目标参考。
所提出的方法包括两个主要步骤:(1)通过VC模型生成合成数据;以及(2)用这些合成数据训练seq2seq AC模型。在第一步中,我们使用了一个VC模型,该模型可以保留源音频的发音模式和韵律,并且只将源speaker的身份(即音色和音高)转换为目标speaker。由于韵律和发音模式是口音最重要的组成部分,如果我们能在音频中保留它们,口音将保持不变。因此,我们可以合成一对具有相同声音、相同上下文但不同口音的话语。第3.1节介绍了生成合成数据的过程。在第二步中,我们用第一阶段创建的音频数据训练seq2seq AC模型。
我们的方法受到许多主流speech方法的启发。首先, speech recognition和accent转换模型有共同的input type,即audio data。这就是为什么我们可以研究应用于AC模型的语音识别编码器的架构。此外,使用预先训练的音频编码器被证明可以在不需要太多标记数据的情况下提高语音识别模型的性能。其次,AC模型和语音合成系统共享相同的output modality,因此我们可以将语音合成解码器的架构用于AC模型。最后,我们的实验seq2seq AC模型由预先训练的音频编码器和语音合成解码器组成。简言之,我们使用VC来解决AC问题中的ground-truth data挑战,然后证明了使用预训练的音频编码器在训练AC模型时不依赖于大量标记的音频数据的优势。
2. Related work
任何语音转换系统的目标都是将源扬声器的语音转换为另一个目标扬声器的语音。
基于高斯混合模型的传统技术表现良好,但基于人工神经网络的技术甚至优于它们。一些体系结构已被用于解决VC问题,如GAN、VAE和seq2seq。也存在许多类型的VC系统:一对一、一对多、多对多、任意对任意等等。任意对任意VC系统是最具挑战性的系统,它可以将任何源说话者转换为任何目标说话者,即使在训练数据中没有发现说话者,它也已在VQMIVC、AutoVC、Adain、FragmentVC等几个实验中得到了解决。
我们采用了两种最新的架构VQMIVC和FragmentVC,来训练VC系统并生成合成数据,然后找出哪种是更好的数据合成方法。
accent转换通常与类似的问题有关:语音转换(VC)。VC主要关注改变音频中的说话人身份,而AC只改变或纠正发音模式,同时试图保持说话人身份。AC是一个更具挑战性的问题,因为通常没有具有相同语音和不同口音的ground-truth数据。语音后验图(PPG)已成功用于VC任务,尽管系统存在各种限制,但也可用于AC。
例如,为了将非母语口音转换为母语口音,这些系统在转换阶段需要参考母语口音,这最终限制了它们在现实生活中的实际应用。没有引用话语的交流被称为无引用过程。我们的文献研究只能强调先前关于无参考AC的两项工作。第二项研究通过消除一些复杂的组件,如TTS、ASR,解决了第一项研究的一些局限性,并且与我们提出的方法更相关。他们使用带有语音嵌入的语音合成器作为输入来进行合成数据,并从stratch中训练了基于LSTM的seq2seq AC模型。虽然他们的语音合成器需要专门针对训练集中的每个说话者进行训练,但我们的方法使用单个VC模型来合成所有说话者的训练数据,这是一种更方便的方法。因此,我们可以将他们的AC模型作为比较我们的模型的基线方法。
以前的大多数研究主要集中在将非母语语音转换为母语语音上。反向转换可能更具挑战性,因为非本地语音数据不如本地语音可用。在这项研究中,除了纠正非母语人士的发音外,我们还专注于实验从母语到非母语的AC。这种转换可以帮助母语人士生成更多的非母语口音语音,从而丰富非母语数据资源。
最近,预训练的模型已成功应用于语音翻译、语音到语音翻译、语音识别和语音转换。这些模型有可能提供另一种方法来克服标记数据的不足。受wav2vec 2.0成功的启发,我们的研究提出了一种经过wav2vec2.0预训练的AC模型,该模型可以在低资源条件下有效运行。
3. Method
3.1. Generating synthetic data
3.1.1. General idea of generating synthetic data
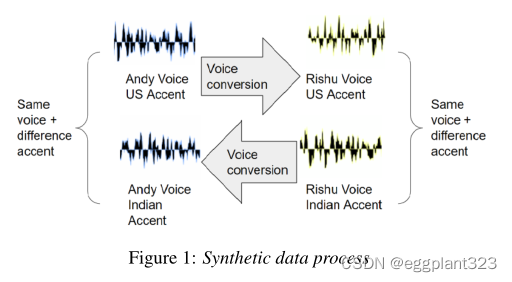
生成合成数据的目的是创建可用于训练seq2seq AC模型的音频对。例如,有两个相同内容的音频由两个不同的演讲者录制:带有美国口音的Andy和带有印度口音的Rishu。当我们对Andy的原始音频进行语音转换时,预期的结果是一个具有Rishu声音但仍保留美国口音的音频。
这与VC系统是一致的,VC系统只改变说话者的身份,同时保留原始口音。在这个过程的最后,我们有一对有声读物,Rishu的声音有两种不同的口音——(原始的)印度口音和(转换的)美国口音。如果我们对Rishu的音频进行另一种方式的语音转换,我们希望有一对安迪的音频,但有两种不同的口音——(原始的)美国口音和(转换的)印度口音。这些音频对可以用作训练seq2seq AC系统的源和目标。语音转换过程如图1所示。
3.1.2. Voice conversion
我们想要的架构应该能够改变说话者的身份,并保留独特的口音特征(发音模式和韵律)。我们研究了两种有前途的VC架构,它们是基于seq2seq架构的Fragment VC和基于变分自动编码器架构的VQMIVC。在通过我们的数据和与原始论文中相同的超参数对模型进行彻底微调后,我们使用此VC模型生成合成数据。
FragmentVC
FragmentVC是一个seq2seq架构,由源编码器、目标编码器和解码器组成。解码器从源编码器(Q)获得一个输出特征,从目标编码器(K,V)获得两个输出特征。目标编码器(K)的输出特征序列随后由源编码器的输出(Q)参与。解码器中的交叉注意模块学习将源特征与该架构中具有类似语音内容的目标特征对齐。然后解码器将注意力强化的特征转换为梅尔谱图。在训练阶段,相同的话语被馈送到源、目标编码器和解码器的重建目标。编码器自动学习在没有任何明确约束的情况下解耦内容和说话者信息。由于转换后的语音与源语音共享相同的内容(语音),语音和韵律(或重音)将被保留。
VQMIVC
VQMIVC(矢量量化互信息语音转换)使用直接的自动编码器架构来解决VC过程。该框架由四个模块组成:从语音中生成内容嵌入的content encoder、从语音中产生说话者嵌入(D向量)的speaker encoder、从speech中生成韵律嵌入的pitch encoder,以及从内容、韵律和说话者嵌入中重构语音的decoder。语音和韵律通过内容和韵律嵌入来表示。内容嵌入由矢量量化模块离散化,并用作对比预测编码损失的目标。
互信息(MI)损失测量所有表示之间的依赖性,并且可以有效地集成到训练过程中,以实现语音表示的解纠缠。在转换阶段,源语音被放入内容编码器和音高编码器,以提取内容嵌入和韵律嵌入。为了提取目标说话人嵌入,将目标语音发送到说话人编码器。最后,解码器使用源语音的内容和韵律嵌入以及目标语音的说话人嵌入来重构转换后的语音。与FragmentVC架构中一样,转换后的语音将与源语音共享相同的内容和韵律,因此期望模型保留accent。
3.2. Accent conversion
3.2.1. Baseline approach
基线系统基于编码器-解码器范式(图2),具有注意力机制。编码器有两个金字塔双LSTM层,类似于。每层有768个单元,下采样因子为2。基线编码器的输入是80 mel-filterbanks feature。在编码器之上,我们添加了一个音素分类器层,并计算了connectionist
temporal classification (CTC)损失。
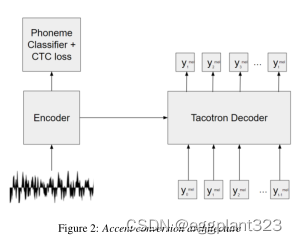
基线解码器具有与Tacotron语音合成器解码器类似的神经网络结构,并具有注意力机制。注意力机制包括三个部分:查询层、键值层和对齐层。前两层产生具有相同维度的查询向量和键值向量序列。换句话说,查询、键和值被处理为在同一向量空间中。之后,对齐层通过部署在该向量空间中的方法来学习注意力权重。
解码过程的第一步组成对注意力机制的查询,定义为等式2(RNN Att),其中
s
i
s_{i}
si是注意力RNN层的隐藏状态,
s
i
−
1
s_{i-1}
si−1 和
c
i
−
1
c_{i-1}
ci−1 分别是前隐藏-state和上下文向量。然后,我们的注意力机制的对齐层被定义为等式3,其中
α
i
\alpha_{i}
αi 是解码步骤
i
i
i处的注意力权重,查询层、存储层和位置层是对齐块的模块。注意力机制考虑三个项来计算注意力权重。
除了基本查询和键值之外,注意力权重
α
i
−
1
\alpha_{i-1}
αi−1 的先前预测也被输入到对齐块中。因此,Tacontron解码器中的注意力机制不仅是content-based的,而且是location-sensitive的。此时,当前注意力权重可用,因此我们计算键值序列的加权和,如等式4所示。这个加权和表示上下文信息,因此被称为上下文向量。之后,解码器RNN层被定义为等式5,其中
s
i
−
1
s_{i-1}
si−1 和
c
i
−
1
c_{i-1}
ci−1被级联以被馈送到该RNN层中;
d
i
d_{i}
di是RNN隐藏状态。最后,RNN隐藏状态被馈送到最终预测层,并且我们在等式6中的解码步骤i得到
y
i
m
e
l
y_{i}^{m e l}
yimel作为mel谱图预测。为了提高谱图质量,将mel谱图预测通过卷积PostNet模块,如等式7所示。tacotron解码器的输出是80 mel滤波器组功能。我们将Tacotron解码器的超功率计设置为类似于此实现。

3.2.2. Proposed approach
我们提出的模型利用了wav2vec 2.0中的预训练编码器和语音合成解码器作为基线解码器。
Wav2vec 2.0是一个不错的框架,可以从未标记的音频数据中学习高质量的语音表示。它由两个组件组成:特征编码器和上下文编码器。特征编码器包含temporal 卷积层,以原始波形为输入,进行语音表示。在下一步中,它们被馈送到基于transformer的上下文编码器,以生成具有序列级信息的上下文表示。在预训练阶段,使用contrastive损失对模型进行优化,以区分真正的目标和干扰物。
上下文编码器的输入被部分屏蔽(mask)。语音表示由矢量量化(vector quantization)模块离散化,并用作对比损失的目标。本研究使用了在LibriSpeech上训练的Wav2Vec 2.0 Base的预训练模型,该模型提取768维语音表示。与基线编码器不同,wav2vec编码器的输入是原始音频波形。我们使用Fairseq2中Wav2vec的实现。在wav2vec编码器之上,我们添加了一个音素分类器层,并再次计算CTC损失。在训练阶段,我们冻结特征编码器,并微调Wav2vec上下文编码器和Tacotron解码器的整个参数。
在训练阶段,基线系统和拟议系统的最终损失函数为Eq 8。我们在损失函数中不包括止损标记,因为我们假设在推理阶段输出音频的长度与输入音频的长度相同。
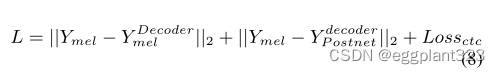
在本文中,WaveGlow网络被用作神经声码器vocoder。我们还使用开源Pytorch实现。由于mel声谱图捕获了高质量语音合成所需的所有相关细节,我们只需使用地面实况80 mel滤波器组声谱图来训练WaveGlow。
4. Experiments
4.1. Dataset and training description
为了训练VC模型,我们使用了来自CMUARCTIC语料库和L2-ARCTIC印地语重音语料库的音频数据。这些公司共有8名发言人(4名以英语为母语,4名以印度口音为母语),每个发言人都有1152句相同句子的音频。为了在所有扬声器上获得更好的VC输出,我们在中预先训练的VC模型的基础上,通过在这些数据主体上对其进行微调,而不必从头开始训练VC模型。
为了合成并行数据来训练我们的AC模型,我们首先将1152个句子划分为一个训练集(1052个句子)、一个验证集(50个句子)和一个测试集(50句句子)。每句话由8名讲者讲(4名母语者和4名印度口音者)。在应用3.1中描述的数据合成过程后,我们为每个句子获得8个音频对。我们总共有大约9000对音频,长度约为9小时。所有这些都是在16khz下采样的。
基线和提出的AC模型都是在单个GPU上通过以批大小64分组来训练的,并且使用Adam优化器每8个小批更新梯度,使用与Transformer模型相同的学习速率调度,使用0.5和4000个预热步骤的基本学习速率。这两种模型最多可训练20000步
4.2. Evaluation metrics
我们使用两种指标对所有模型进行评估:客观和主观,这两种指标将在下一节中进行描述。我们在测试集中使用50个句子(200个美国口音的音频文件和200个印度口音的音频文档)进行评估。样本评估音频可以在这里找到。
4.2.1. Subjective tests
**Accentedness test and speaker similarity test **
由10名印度参与者进行两项测试,他们听所提供的音频,并以5分制评估他们的口音特征:1分、2分、3分、一般、4分、良好。为了生成带有印度口音的转换音频,我们将我们的AC模型应用于200个美国口音的音频文件。在重音测试中,参与者对转换后的音频听起来像印度口音演讲的程度给予5分。对于说话者相似性测试,他们对输入音频的语音身份和转换后的音频之间的相似性进行评分,然后如上所述给出5分。
4.2.2. Objective tests
Word error rates (WER) and Accent classifier accuracy (ACC) :
我们通过竞争性ASR系统计算原始印度口音音频和转换后的印度口音音频的WER。如果两个WER之间的间隙较低,则意味着转换后的音频的质量更好。此外,我们设计了一个accent分类器,它将音频作为输入,并预测该输入的accent。accent分类器是一个具有512个隐藏单元的4-LSTM层网络,其顶部有一个accent分类器层,并在我们的训练数据集上进行训练。我们根据转换后的音频和原始音频计算ACC。更好的转换模型预计两个ACC之间的差距较小。
4.3. Results
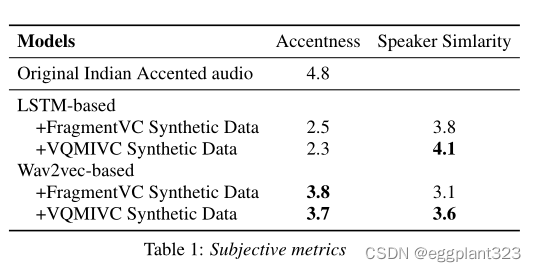
这项由印度母语人士参与的调查产生了几个主观指标,如表1所示。对于accent测试,基于Wav2vec的模型在所有合成数据条件下都优于基于LSTM的模型(3.8 vs 2.5和3.6 vs 2.3)。另一方面,基于LSTM模型在说话人相似性测试中似乎有更好的结果。这样的观察表明,与基于LSTM的模型相比,Wav2vec模型可能在更大程度上改变了音频,这实际上产生了更好的重音输出,但使参与者发现说话者身份发生了更多变化。
FragmentVC和VQMIVC在重音测试中获得了相当相似的评估(2.5对2.3和3.8对3.7)。然而,在说话人相似性测试中,FragmentVC方法的性能不如VQMIVC。这意味着VQMIVC模型在VC中比FragmentVC更有效;因此它可以生成具有与源音频相似的语音的目标地面实况音频。
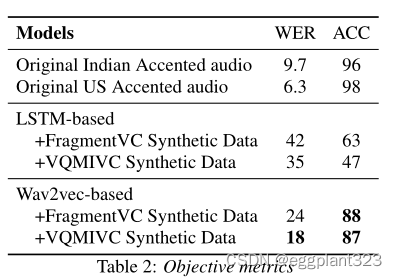
为了确定语音识别和口音分类器的性能,我们将它们应用于原始的印度和美国口音音频。在印度口音的测试集上,语音识别模型的WER为9.7%,而在美国口音的测试集中,WER仅为6.3%。口音分类器也非常准确,在印度口音和美国口音的测试集中分别检测到96%和98%。我们将这些模型应用于AC的音频结果,以比较不同的合成数据和AC模型。
为了比较合成数据模型,我们使用相同AC模型提供的输出。使用VQMIVC合成数据进行训练总是会导致基于LSTM和基于Wav2vec的模型的WER得到改进。这一观察结果意味着VQMIVC比FragmentVC生成更高质量的训练数据。就ACC而言,基于Wav2vec的模型对两个合成模型产生了可比较的结果(片段VC和VQMIVC分别为88%和87%)。
然而,基于LSTM的模型的结果有些不同(分别为63%和47%)。然而,这并不意味着Fragment VC比VQMIVC更好地保留了accent,因为基于LSTM的模型不足以生成高质量的输出。在比较AC模型时,基于Wav2vec的模型再次比基于所有数据合成条件的LSTM具有更好的主观结果。
5. Conclusions
在本文中,我们已经表明,一个像样的VC模型可以提供一种方便的方法来解决AC中的ground truth数据问题。此外,还描述了Wav2vec预训练编码器如何有助于在低资源条件下训练AC模型。在整个实验中,我们只关注单向(一对一)交流模型。鉴于预先训练的音频编码器的优势,我们未来的目标是将这种方法应用于训练具有更多重音数据的多向(许多种)AC。

















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









