







DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
abstract
歌声合成(SVS)系统是为了合成高质量和富有表现力的歌声而建立的,其中声学模型在给定乐谱的情况下生成声学特征(例如,融合谱图)。先前的歌唱声学模型采用简单损失(如L1和L2)或生成对抗性网络(GAN)来重建声学特征,而它们分别存在过度平滑和不稳定的训练问题,这阻碍了合成歌唱的自然度。在这项工作中,我们提出了DiffSinger,一种基于扩散概率模型的SVS声学模型。DiffSinger是一个参数化的马尔可夫链,它迭代地将噪声转换为以乐谱为条件的mel谱图。通过隐式优化变分界,可以稳定地训练DiffSinger并生成真实的输出。为了进一步提高语音质量和加快推理速度,我们引入了一种浅层扩散机制,以更好地利用通过简单损失获得的先验知识。具体地,DiffSinger根据基本事实mel谱图的扩散轨迹与简单mel谱线解码器预测的扩散轨迹的交集,以小于扩散步骤总数的浅步长开始生成。此外,我们还提出了边界预测方法来定位交叉点并自适应地确定浅阶。在中文歌唱数据集上进行的评估表明,DiffSinger优于最先进的SVS工作。扩展实验也证明了我们的方法在文本到语音任务(DiffSpeech)上的通用性。
introduction
歌声合成(SVS)旨在从乐谱中合成自然、富有表现力的歌声(Wu and Luan 2020),越来越受到研究界和娱乐界的关注(Zhang et al 2020)。SVS的流水线通常由声学模型和声码器组成,声学模型用于生成以乐谱为条件的声学特征(例如,融合谱图),声码器用于将声学特征转换为波形(Nakamura等人)。
先前的歌唱声学模型主要利用简单损失(例如,L1或L2)来重建声学特征。然而,这种优化是基于不正确的单峰分布假设,导致输出模糊和过度平滑。尽管现有的方法试图通过生成对抗性网络(GAN)来解决这个问题(Lee等人2019;Chen等人2020),但由于鉴别器不稳定,训练有效的GAN偶尔会失败。这些问题阻碍了合成歌唱的自然性。(简单loss是基于不正确的单峰分布 会过于平滑;GAN 鉴别器不稳定,影响自然度)
最近,出现了一种高度灵活和易于处理的生成模型,即扩散概率模型(也称为扩散模型)(SohlDickstein等人2015;Ho、Jain和Abbeel 2020;Song、Meng和Ermon 2021)。扩散模型由两个过程组成:扩散过程和反向过程(也称为去噪过程)。扩散过程是一个具有固定参数的马尔可夫链(当使用(Ho,Jain,and Abbeel 2020)中的特定参数化时),它通过逐渐添加高斯噪声将复杂的数据转换为各向同性的高斯分布;而反向过程是由神经网络实现的马尔可夫链,该神经网络学习迭代地从高斯白噪声中恢复原始数据。通过隐式优化数据似然的变分下界(ELBO),可以稳定地训练扩散模型。已经证明,扩散模型可以在图像生成中产生有希望的结果(Ho,Jain,and Abbeel 2020;Song,Meng,and Ermon 2021)和神经声码器(Chen等人2021;Kong等人2021)字段。
在这项工作中,我们提出了DiffSinger,这是一种基于扩散模型的SVS声学模型,它将噪声转换为以乐谱为条件的mel声谱图。DiffSinger可以通过优化ELBO进行有效训练,而无需对抗性反馈,并生成与GT分布强匹配的真实融合谱图。
为了进一步提高语音质量和加快推理速度,我们引入了一种浅层扩散机制(shallow diffusion mechanism),以更好地利用通过简单损失获得的先验知识。具体地,我们发现GT mel谱图 M M M的扩散轨迹与由简单的mel谱线解码器 M ~ \widetilde{M} M 预测的扩散轨迹相交:当扩散步长足够大时(但未达到深度步长,在深度步长处,失真的mel谱图变为高斯白噪声),将 M M M和 M ~ \widetilde{M} M 发送到扩散过程中可能导致类似的失真mel谱线图。
因此,在推理阶段,我们
- 利用简单的融合谱图解码器来生成 M ~ \widetilde{M} M ;
- 通过扩散过程计算浅阶 k k k处的样本: M ~ k \widetilde{M}_{k} M k;
- 从 M ~ k \widetilde{M}_{k} M k而不是高斯白噪声开始反向过程,并通过k个迭代去噪步骤完成该过程(Vincent 2011;Song和Ermon 2019;Ho、Jain和Abbeel 2020)。
此外,我们训练了一个边界预测网络来定位这个交叉点,并自适应地确定 k k k。浅扩散机制提供了比高斯白噪声更好的起点,并减轻了反向处理的负担,从而提高了合成音频的质量并加速了推理。
最后,由于SVS的流水线与TTS任务的流水线相似,我们还从DiffSinger中构建了DiffSpeech调整来进行泛化。在中国歌唱数据集上进行的评价证明了DiffSinger(0.11与SVS的现有声学模型相比的MOS增益(Wu和Luan 2020)),以及我们的新机制的有效性(0.14MOS增益,0.5 CMOS增益和45.1%的浅扩散机制加速)。DiffSpeech在TTS任务上的扩展实验证明了我们的方法(0.24/0.23分别与FastSpeech2(Ren等人2021)和Glow TTS(Kim等人2020)相比,MOS增益)。这项工作的贡献可概括如下:
- 我们提出了DiffSinger,这是第一个基于扩散概率模型的SVS声学模型。DiffSinger解决了以往工作中的过度平滑和不稳定训练问题。
- 我们提出了一种浅层扩散机制,以进一步提高语音质量,并加速推理。
- TTS任务(DiffSpeech)的扩展实验证明了我们的方法的通用性。
Diffusion Model
在本节中,我们介绍了扩散概率模型的理论(Sohl-Dickstein等人2015;Ho、Jain和Abbeel 2020)。完整的证据可以在以前的作品中找到(Ho,Jain,and Abbeel 2020;Kong等人2021;Song,Meng,and Ermon 2021)。扩散概率模型通过扩散过程将原始数据逐渐转换为高斯分布,然后学习反向过程以从高斯白噪声中恢复数据(Sohl-Dickstein等人
2015)。这些过程如图1所示。
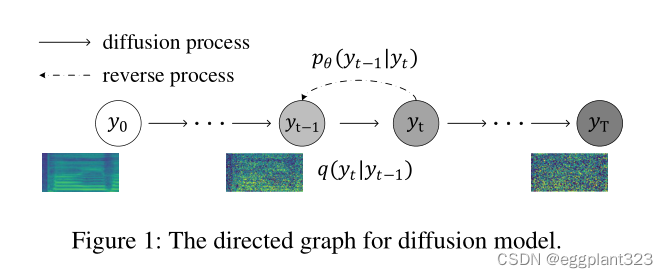
Diffusion Process
将数据分布定义为
q
(
y
0
)
q\left(\mathbf{y}_{0}\right)
q(y0),并对
y
0
∼
q
(
y
0
)
\mathbf{y}_{0} \sim q\left(\mathbf{y}_{0}\right)
y0∼q(y0)进行采样。扩散过程是一个具有固定参数的马尔可夫链(Ho、Jain和Abbeel 2020),它以
T
T
T步将
y
0
\mathbf{y}_{0}
y0转换为潜在
y
T
\mathbf{y}_{T}
yT:
q
(
y
1
:
T
∣
y
0
)
:
=
∏
t
=
1
T
q
(
y
T
∣
y
t
−
1
)
.
q\left(\mathbf{y}_{1: T} \mid \mathbf{y}_{0}\right):=\prod_{t=1}^{T} q\left(\mathbf{y}_{T} \mid \mathbf{y}_{t-1}\right) .
q(y1:T∣y0):=t=1∏Tq(yT∣yt−1).
在每个扩散步骤
t
∈
[
1
,
T
]
t \in[1, T]
t∈[1,T],根据方差表
β
=
{
β
1
,
…
,
β
T
}
\beta=\left\{\beta_{1}, \ldots, \beta_{T}\right\}
β={β1,…,βT},将微小的高斯噪声添加到
y
t
−
1
\mathbf{y}_{t-1}
yt−1以获得
y
t
\mathbf{y}_{t}
yt:
q
(
y
t
∣
y
t
−
1
)
:
=
N
(
y
t
;
1
−
β
t
y
t
−
1
,
β
t
I
)
.
q\left(\mathbf{y}_{t} \mid \mathbf{y}_{t-1}\right):=\mathcal{N}\left(\mathbf{y}_{t} ; \sqrt{1-\beta_{t}} \mathbf{y}_{t-1}, \beta_{t} \mathbf{I}\right) .
q(yt∣yt−1):=N(yt;1−βtyt−1,βtI).
如果
β
\beta
β设计得很好,并且
T
T
T足够大,那么
q
(
y
T
)
q\left(y_{T}\right)
q(yT)几乎是各向同性的高斯分布(Ho,Jain和Abbeel 2020;Nichol和Dhariwal 2021)。此外,扩散过程还有一个特殊性质,即
q
(
y
t
∣
y
0
)
q\left(\mathbf{y}_{t} \mid \mathbf{y}_{0}\right)
q(yt∣y0)可以在
O
(
1
)
O(1)
O(1)时间内以闭合形式计算(Ho,Jain,and Abbeel 2020):
q
(
y
t
∣
y
0
)
=
N
(
y
t
;
α
ˉ
t
y
0
,
(
1
−
α
ˉ
t
)
I
)
,
q\left(\mathbf{y}_{t} \mid \mathbf{y}_{0}\right)=\mathcal{N}\left(\mathbf{y}_{t} ; \sqrt{\bar{\alpha}_{t}} \mathbf{y}_{0},\left(1-\bar{\alpha}_{t}\right) \mathbf{I}\right),
q(yt∣y0)=N(yt;αˉty0,(1−αˉt)I),
其中
α
ˉ
t
:
=
∏
s
=
1
t
α
s
,
α
t
:
=
1
−
β
t
\bar{\alpha}_{t}:=\prod_{s=1}^{t} \alpha_{s}, \alpha_{t}:=1-\beta_{t}
αˉt:=∏s=1tαs,αt:=1−βt.
Reverse Process
反向过程是一个马尔可夫链,具有从
y
T
\mathbf{y}_{T}
yT 到
y
0
\mathbf{y}_{0}
y0的可学习参数
θ
\theta
θ 。由于精确的反向跃迁分布
q
(
y
t
−
1
∣
y
t
)
q\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}\right)
q(yt−1∣yt)是难以处理的,我们通过参数为
θ
\theta
θ的神经网络对其进行近似(
θ
\theta
θ在每
t
t
t步共享):
p θ ( y t − 1 ∣ y t ) : = N ( y t − 1 ; μ θ ( y t , t ) , σ t 2 I ) . p_{\theta}\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}\right):=\mathcal{N}\left(\mathbf{y}_{t-1} ; \boldsymbol{\mu}_{\theta}\left(\mathbf{y}_{t}, t\right), \sigma_{t}^{2} \mathbf{I}\right) . pθ(yt−1∣yt):=N(yt−1;μθ(yt,t),σt2I).
因此,整个反向过程可以定义为:
p
θ
(
y
0
:
T
)
:
=
p
(
y
T
)
∏
t
=
1
T
p
θ
(
y
t
−
1
∣
y
t
)
.
p_{\theta}\left(\mathbf{y}_{0: T}\right):=p\left(\mathbf{y}_{T}\right) \prod_{t=1}^{T} p_{\theta}\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}\right) .
pθ(y0:T):=p(yT)t=1∏Tpθ(yt−1∣yt).
training
为了学习参数θ,我们最小化负对数似然的变分界:
E
q
(
y
0
)
[
−
log
p
θ
(
y
0
)
]
≥
E
q
(
y
0
,
y
1
,
…
,
y
T
)
[
log
q
(
y
1
:
T
∣
y
0
)
−
log
p
θ
(
y
0
:
T
)
]
=
:
L
.
\begin{aligned} & \mathbb{E}_{q\left(\mathbf{y}_{0}\right)}\left[-\log p_{\theta}\left(\mathbf{y}_{0}\right)\right] \geq \\ & \mathbb{E}_{q\left(\mathbf{y}_{0}, \mathbf{y}_{1}, \ldots, \mathbf{y}_{T}\right)}\left[\log q\left(\mathbf{y}_{1: T} \mid \mathbf{y}_{0}\right)-\log p_{\theta}\left(\mathbf{y}_{0: T}\right)\right]=: \mathbb{L} . \end{aligned}
Eq(y0)[−logpθ(y0)]≥Eq(y0,y1,…,yT)[logq(y1:T∣y0)−logpθ(y0:T)]=:L.
有效训练是通过随机梯度下降优化
L
\mathbb{L}
L 的随机项(Ho,Jain,and Abbeel 2020)
L
t
−
1
=
D
K
L
(
q
(
y
t
−
1
∣
y
t
,
y
0
)
∥
p
θ
(
y
t
−
1
∣
y
t
)
)
,
\mathbb{L}_{t-1}=D_{\mathrm{KL}}\left(q\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}, \mathbf{y}_{0}\right) \| p_{\theta}\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}\right)\right),
Lt−1=DKL(q(yt−1∣yt,y0)∥pθ(yt−1∣yt)),
其中
q
(
y
t
−
1
∣
y
t
,
y
0
)
=
N
(
y
t
−
1
;
μ
~
t
(
y
t
,
y
0
)
,
β
~
t
I
)
μ
~
t
(
y
t
,
y
0
)
:
=
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
y
0
+
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
y
t
,
\begin{aligned} & q\left(\mathbf{y}_{t-1} \mid \mathbf{y}_{t}, \mathbf{y}_{0}\right)=\mathcal{N}\left(\mathbf{y}_{t-1} ; \tilde{\boldsymbol{\mu}}_{t}\left(\mathbf{y}_{t}, \mathbf{y}_{0}\right), \tilde{\beta}_{t} \mathbf{I}\right) \\ & \tilde{\boldsymbol{\mu}}_{t}\left(\mathbf{y}_{t}, \mathbf{y}_{0}\right):=\frac{\sqrt{\bar{\alpha}_{t-1}} \beta_{t}}{1-\bar{\alpha}_{t}} \mathbf{y}_{0}+\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_{t}} \mathbf{y}_{t}, \end{aligned}
q(yt−1∣yt,y0)=N(yt−1;μ~t(yt,y0),β~tI)μ~t(yt,y0):=1−αˉtαˉt−1βty0+1−αˉtαt(1−αˉt−1)yt,
其中
β
~
t
:
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
\tilde{\beta}_{t}:=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t}
β~t:=1−αˉt1−αˉt−1βt等价于
L
t
−
1
−
C
=
E
q
[
1
2
σ
t
2
∥
μ
~
t
(
y
t
,
y
0
)
−
μ
θ
(
y
t
,
t
)
∥
2
]
,
\mathbb{L}_{t-1}-\mathcal{C}=\mathbb{E}_{q}\left[\frac{1}{2 \sigma_{t}^{2}}\left\|\tilde{\boldsymbol{\mu}}_{t}\left(\mathbf{y}_{t}, \mathbf{y}_{0}\right)-\boldsymbol{\mu}_{\theta}\left(\mathbf{y}_{t}, t\right)\right\|^{2}\right],
Lt−1−C=Eq[2σt21∥μ~t(yt,y0)−μθ(yt,t)∥2],
C
\mathcal{C}
C是常数,通过重新参数化方程
y
t
(
y
0
,
ϵ
)
=
α
ˉ
t
y
0
+
1
−
α
ˉ
t
ϵ
\mathbf{y}_{t}\left(\mathbf{y}_{0}, \boldsymbol{\epsilon}\right)=\sqrt{\bar{\alpha}_{t}} \mathbf{y}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}
yt(y0,ϵ)=αˉty0+1−αˉtϵ,并选择参数化:
μ
θ
(
y
t
,
t
)
=
1
α
t
(
y
t
−
β
t
1
−
α
ˉ
t
ϵ
θ
(
y
t
,
t
)
)
\boldsymbol{\mu}_{\theta}\left(\mathbf{y}_{t}, t\right)=\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{y}_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon}_{\theta}\left(\mathbf{y}_{t}, t\right)\right)
μθ(yt,t)=αt1(yt−1−αˉtβtϵθ(yt,t))
上述公式可以化简为:
E
y
0
,
ϵ
[
β
t
2
2
σ
t
2
α
t
(
1
−
α
ˉ
t
)
∥
ϵ
−
ϵ
θ
(
α
ˉ
t
y
0
+
1
−
α
ˉ
t
ϵ
,
t
)
∥
2
]
.
\mathbb{E}_{\mathbf{y}_{0}, \boldsymbol{\epsilon}}\left[\frac{\beta_{t}^{2}}{2 \sigma_{t}^{2} \alpha_{t}\left(1-\bar{\alpha}_{t}\right)}\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_{\theta}\left(\sqrt{\bar{\alpha}_{t}} \mathbf{y}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}, t\right)\right\|^{2}\right] .
Ey0,ϵ[2σt2αt(1−αˉt)βt2
ϵ−ϵθ(αˉty0+1−αˉtϵ,t)
2].
最后,我们将
σ
t
2
\sigma_{t}^{2}
σt2设置为
β
~
t
\tilde{\beta}_{t}
β~t,样本
ϵ
∼
N
(
0
,
I
)
\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})
ϵ∼N(0,I)和
ϵ
θ
(
⋅
)
\boldsymbol{\epsilon}_{\theta}(\cdot)
ϵθ(⋅)是神经网络的输出。
sampling
从
p
(
y
T
)
∼
N
(
0
,
I
)
p\left(\mathbf{y}_{T}\right) \sim \mathcal{N}(\mathbf{0}, \mathbf{I})
p(yT)∼N(0,I) 中采样样本
y
T
\mathbf{y}_{T}
yT,并运行相反的过程以获得数据样本。
DiffSinger
如图2所示,DiffSinger是建立在扩散模型上的。由于SVS任务对条件分布
p
θ
(
M
0
∣
x
)
p_{\theta}\left(M_{0} \mid x\right)
pθ(M0∣x)进行建模,其中
M
M
M是mel声谱图,
x
x
x是与
M
M
M对应的乐谱,因此我们在反向过程中将
x
x
x添加到扩散去噪器中作为条件。在本节中,我们首先描述DiffSinger的初始版本(第3.1节);然后,我们引入了一种新的浅扩散机制来提高模型的性能和效率(第3.2节);最后,我们描述了边界预测网络,它可以自适应地找到浅层扩散机制所需的相交边界(第3.3节)。
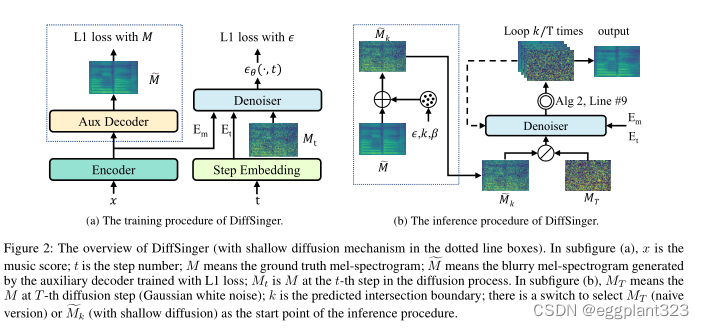
Naive Version of DiffSinger
在DiffSinger的原始版本中(图2中没有虚线框):在训练过程中(如图2a所示),DiffSinger在扩散过程中的第 t t t步 M t M_{t} Mt获取mel谱图,并预测随机噪声 ϵ θ ( ⋅ ) \epsilon_{\theta}(\cdot) ϵθ(⋅) 方程中,以 t t t和乐谱 x x x为条件。推理过程(如图2b所示)从从 N ( 0 , I ) \mathcal{N}(\mathbf{0}, \mathbf{I}) N(0,I)采样的高斯白噪声开始,就像以前的扩散模型一样(Ho,Jain,and Abbeel 2020;Kong等人2021)。然后,该过程迭代 T T T次,以通过两个步骤重复对中间样本进行去噪:
- 通过denoiser预测 ϵ θ ( ⋅ ) \epsilon_{\theta}(\cdot) ϵθ(⋅);
- 使用预测的
ϵ
θ
(
⋅
)
\epsilon_{\theta}(\cdot)
ϵθ(⋅),根据公式从
M
t
M_{t}
Mt得到
M
t
−
1
M_{t-1}
Mt−1
M t − 1 = 1 α t ( M t − 1 − α t 1 − α ˉ t ϵ θ ( M t , x , t ) ) + σ t z , M_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(M_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \epsilon_{\theta}\left(M_{t}, x, t\right)\right)+\sigma_{t} \mathbf{z}, Mt−1=αt1(Mt−1−αˉt1−αtϵθ(Mt,x,t))+σtz,
其中,当 t > 1 t>1 t>1时 z ∼ N ( 0 , I ) z \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) z∼N(0,I),当 t = 1 t=1 t=1时 z = 1 z=1 z=1。
最后,可以生成对应于 x x x的mel谱图 M M M。
Shallow Diffusion Mechanism
尽管以前通过简单损失训练的声学模型具有难以解决的缺点,但它仍然生成与GT数据分布显示出强连接的样本,这可以为DiffSinger提供大量的先验知识。为了探索这种联系并找到更好地利用先验知识的方法,我们利用扩散过程进行了实证观察(如图3所示):

- 当 t = 0 t=0 t=0时, M M M在相邻谐波之间具有丰富的细节,这会影响合成歌声的自然度,但正如我们在第1节中介绍的, M ~ \widetilde{M} M 是过平滑的;
- 随着 t t t的增加,样本的两个过程变得无法区分。我们在图4中说明了这一观察结果:当扩散步长足够大时,从 M ~ \widetilde{M} M 流形到高斯噪声流形的轨迹和从 M M M到高斯噪声歧管的轨迹相交。
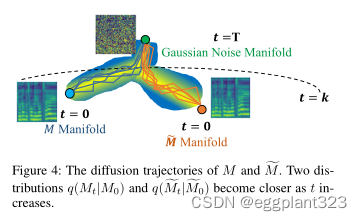
受这一观察结果的启发,我们提出了浅层扩散机制:相反的过程从图4所示的两个轨迹的交叉点开始,而不是从高斯白噪声开始。因此,反向过程的负担可以明显减轻。具体而言,在推理阶段,我们
- 利用辅助解码器来生成 M ~ \widetilde{M} M ,该解码器用L1进行训练以乐谱编码器输出为条件,如图2a中的虚线框所示;
- 通过扩散过程在浅阶
k
k
k处生成中间样品,如图2b中的虚线框所示。
M ~ k ( M ~ , ϵ ) = α ˉ k M ~ + 1 − α ˉ k ϵ , \widetilde{M}_{k}(\widetilde{M}, \boldsymbol{\epsilon})=\sqrt{\bar{\alpha}_{k}} \widetilde{M}+\sqrt{1-\bar{\alpha}_{k}} \boldsymbol{\epsilon}, M k(M ,ϵ)=αˉkM +1−αˉkϵ,
其中 ϵ ∼ N ( 0 , I ) , α ˉ k : = ∏ s = 1 k α s , α k : = 1 − β k \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), \bar{\alpha}_{k}:=\prod_{s=1}^{k} \alpha_{s}, \alpha_{k}:=1-\beta_{k} ϵ∼N(0,I),αˉk:=∏s=1kαs,αk:=1−βk如果相交边界 k k k选择得当,则可以认为 M ~ k \widetilde{M}_{k} M k 和 M k M_{k} Mk来自相同的分布; - 其中 ϵ ∼ N ( 0 , I ) , α ˉ k : = ∏ s = 1 k α s , α k : = 1 − β k \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), \bar{\alpha}_{k}:=\prod_{s=1}^{k} \alpha_{s}, \alpha_{k}:=1-\beta_{k} ϵ∼N(0,I),αˉk:=∏s=1kαs,αk:=1−βk如果相交边界 k k k选择得当,则可以认为 M ~ k \widetilde{M}_{k} M k 和 M k M_{k} Mk来自相同的分布;
Boundary Prediction
我们提出了一个边界预测器(BP)来定位图4中的交叉点,并自适应地确定
k
k
k。具体而言,BP由分类器和用于根据等式向mel频谱图添加噪声的模块组成。给定阶数
t
∈
[
0
,
T
]
t \in[0, T]
t∈[0,T],我们将
M
t
M_{t}
Mt标记为1,
M
~
t
\widetilde{M}_{t}
M
t标记为由0,并使用交叉熵损失来训练边界预测器,以判断扩散过程中t阶的输入mel谱图是来自
M
M
M还是来自
M
~
\widetilde{M}
M
。
训练损失
L
B
P
\mathbb{L}_{B P}
LBP可以被记为:
L
B
P
=
−
E
M
∈
Y
,
t
∈
[
0
,
T
]
[
log
B
P
(
M
t
,
t
)
+
log
(
1
−
B
P
(
M
~
t
,
t
)
)
]
,
\begin{array}{r} \mathbb{L}_{B P}=-\mathbb{E}_{M \in \mathcal{Y}, t \in[0, T]}\left[\log B P\left(M_{t}, t\right)+\right. \\ \left.\log \left(1-B P\left(\widetilde{M}_{t}, t\right)\right)\right], \end{array}
LBP=−EM∈Y,t∈[0,T][logBP(Mt,t)+log(1−BP(M
t,t))],
其中
Y
Y
Y是mel声谱图的训练集。当BP已经被训练时,我们使用BP的预测值来确定
k
k
k,该预测值指示样本被分类为1的概率。对于所有
M
∈
Y
M \in \mathcal{Y}
M∈Y,我们找到最早的步骤
k
′
k^{\prime}
k′,其中
[
k
′
,
T
]
\left[k^{\prime}, T\right]
[k′,T] 中95%的步骤t满足:
BP
(
M
t
\operatorname{BP}\left(M_{t}\right.
BP(Mt,
t
)
t)
t) 和
BP
(
M
~
t
,
t
)
\operatorname{BP}\left(\widetilde{M}_{t}, t\right)
BP(M
t,t) 之间的裕度低于阈值。然后我们选择
k
′
k^{\prime}
k′的平均值作为相交边界
k
k
k。

我们还通过比较KL散度,在补充中提出了一个更容易的边界预测技巧。注意,边界预测可以被认为是数据集预处理的一个步骤,以选择整个数据集的超参数
k
k
k。
k
k
k实际上可以通过强制在验证集上搜索手动选择。
Model Structures
encoder
编码器将乐谱编码为条件序列,该条件序列由
- 将音素ID映射到嵌入序列的歌词编码器,以及将该序列转换为语言隐藏序列的一系列Transformer块(V aswani et al 2017)组成;
- 长度调节器,用于根据所述持续时间信息将所述语言隐藏序列扩展到mel声谱图的长度
- 音高编码器,用于将音高ID映射到音高嵌入序列中。最后,编码器将语言序列和音高序列相加,作为音乐条件序列
E
m
E_{m}
Em (Ren等人,2020)。

Step Embedding
扩散步骤 t t t是denoiser的另一个条件输入 ϵ θ \epsilon_{\theta} ϵθ、 如等式(6)所示。为了将离散步长 t t t转换为连续隐藏,我们使用正弦位置嵌入(V aswani et al 2017),然后是两个线性层,以获得具有 C C C通道的步长嵌入 E t E_{t} Et 。
Auxiliary Decoder
我们介绍了一种称为辅助解码器的简单melspectrogram解码器,它由堆叠的前馈变换器(FFT)块组成,并生成
M
~
\widetilde{M}
M
作为最终输出,与FastSpeech 2中的melspectrograms解码器相同(Ren等人,2021)。
Denoiser
去噪器
ϵ
θ
\epsilon_{\theta}
ϵθ以
M
t
M_{t}
Mt为输入进行预测
ϵ
\boldsymbol{\epsilon}
ϵ在以步长嵌入
E
t
E_{t}
Et和音乐条件序列
E
m
E_{m}
Em为条件的扩散过程中添加。由于扩散模型没有施加架构约束(Sohl-Dickstein等人2015;Kong等人2021),去噪器的设计有多种选择。我们采用了由(Rethage,Pons,and Serra 2018;Kong等人2021)提出的非因果WaveNet(Oord等人,2016)架构作为我们的去噪器。去噪器由1×1卷积层组成,用于将具有
H
m
H_{m}
Hm个通道的
M
t
M_{t}
Mt投影到具有
C
C
C个通道的输入隐藏序列
H
H
H和具有残差连接的
N
N
N个卷积块。每个卷积块由
- 将 E t E_{t} Et加到 H H H的逐元素加法运算组成;
- 将 H H H从 C C C信道转换为 2 C 2C 2C信道的非因果卷积网络;
- 1×1卷积层,其将 E m E_{m} Em 转换为 2 C 2C 2C通道;
- 门单元,用于合并输入和条件的信息;
- 残差块,用于将合并后的隐藏划分为具有 C C C个信道的两个分支(残差为下面的 H H H,“跳过隐藏”将被收集为最终结果),这使得去噪器能够合并多个层次级别的特征用于最终预测。
Boundary Predictor
边界预测器中的分类器由
1)提供
E
t
E_{t}
Et 的步骤嵌入;
2)具有堆叠卷积层和线性层的ResNet(He等人,2016),其在第
t
t
t 步和
E
t
E_{t}
Et 处获取mel谱图以对
M
t
M_{t}
Mt和
M
~
t
\widetilde{M}_{t}
M
t进行分类。
Experiments
在本节中,我们首先描述了实验装置,然后提供了SVS的主要结果并进行了分析。最后,我们对TTS进行了扩展实验。
Experimental Setup
dataset
由于没有公开的高质量无伴奏演唱数据集,我们收集并注释了一个中国普通话流行歌曲数据集:PopCS,以评估我们的方法。PopCS收录了117首来自合格女歌手的中文流行歌曲(总时长~5.89小时,歌词)。所有的音频文件都在录音棚中录制。每首歌曲都以24kHz采样,并采用16位量化。为了获得与歌曲相对应的更准确的乐谱(Lee等人,2019),我们
- 根据DeepSinger(Ren et al 2020)将每首整首歌分割成句子片段,并在这些句子级别对上训练蒙特利尔强制对齐器工具(MFA)(McAuliffe et al 2017)模型,以获得歌曲片段与其对应歌词之间的音素级别对齐;
- 使用Parselmouth从原始波形中提取F0(基频)作为音高信息,如下(Wu和Luan 2020;Blaauw和Bonada 2020;Ren等人2020)。
我们随机选择2首歌曲进行验证和测试。为了发布高质量的数据集,在论文被接受后,我们对这些歌曲进行了清理和重新分割,产生了1651首歌曲,大部分持续10~13秒。在这个存储库中,我们还添加了额外的代码,用于MIDI-to-Mel,包括没有F0预测/条件的MIDI-to-Mel。
Implementation Details
我们通过拼音跟随将中文歌词转换为音素(Ren et al 2020);并从原始波形中提取mel谱图(Shen等人,2018);并且关于采样率24kHz将跳变大小和帧大小设置为128和512。音素词汇的大小是61。mel仓Hm的数量为80。mel谱图被线性缩放到范围[1,1],并且F0被归一化为具有零均值和单位方差。在歌词编码器中,音素嵌入的维度是256,并且Transformer块具有与FastSpeech 2中的设置相同的设置(Ren等人2021)。在音调编码器中,查找表的大小和编码的音调嵌入被设置为300和256。前面提到的信道大小
C
C
C被设置为256。前面提到的信道大小C被设置为256。在去噪器中,卷积层的数量N为20,核大小为3,并且我们在每个层6处将膨胀设置为1(没有膨胀)。我们将T设为100,将β设为常数,从
β
1
=
1
0
−
4
\beta_{1}=10^{-4}
β1=10−4线性增加到
β
T
=
0.06
\beta_{T}=0.06
βT=0.06。辅助解码器具有与FastSpeech 2中的mel声谱图解码器相同的设置。在边界预测器中,卷积层的数量是5,并且根据经验将阈值设置为0.4。
Training and Inference
训练分为两个阶段:
1)热身阶段:用乐谱编码器分别训练辅助解码器160k步,然后利用辅助解码器训练边界预测器30k步,得到
k
k
k;
2)主要阶段:按照算法1所描述的训练DiffSinger 160k步,直到收敛。在推理阶段,对于所有SVS实验,我们统一使用预训练的并行WaveGAN(PWG)(Y amamoto,Song,and Kim 2020)作为声码器,将生成的融合谱图转换为波形(音频样本)。
Main Results and Analysis
Audio Performance
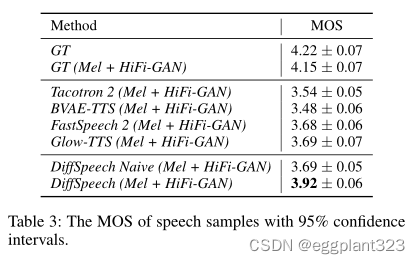
为了评估感知音频质量,我们对测试集进行MOS(平均意见得分)评估。18名合格的听众被要求对合成的歌曲样本做出判断。
我们将DiffSinger生成的歌曲样本的MOS与以下系统进行了比较:
1)GT,地面实况歌唱音频;
2)GT(Mel+PWG),其中我们首先将地面实况歌唱音频转换为地面实况Mel频谱图,然后使用第4.1节中描述的PWG声码器将这些Mel频谱转换回音频;
3) FFT-NPSS(Blaauw和Bonada 2020)(WORLD),SVS系统,通过前馈变换器(FFT)生成WORLD声码器特征(Morise,Y okomori和Ozawa 2016),并使用WORLD声编码器合成音频;
4) FFT Singer(Mel+PWG)SVS系统,通过FFT网络生成Mel频谱图,并使用PWG声码器合成音频;
5) GANSinger(Wu和Luan 2020)(Mel+PWG),使用多个随机窗口鉴别器进行对抗性训练的SVS系统。
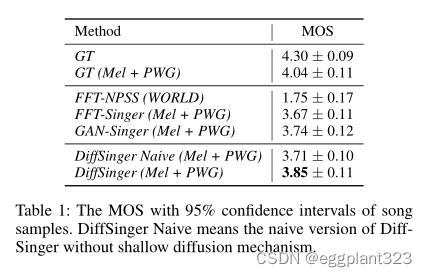
结果如表1所示。GT(MEL+PWG)的质量(4.04±0.11)是SVS声学模型的上限。DiffSinger在很大程度上优于具有简单训练损失的基线系统(FFT Singer),并与最先进的基于GAN的方法(GAN Singer(Wu and Luan 2020))相比显示出优势,这证明了我们方法的有效性。
如图5所示,我们比较了具有相同乐谱的Diffsinger、GAN singer和FFT singer生成的mel声谱图的基本事实。可以看出,与图5d相比,图5c和图5b在谐波之间包含了更精细的细节。此外,Diffsinger在中低频区域的性能比GAN singer更具竞争力,同时保持了高频区域的相似质量。
同时,浅扩散机制使朴素扩散模型的推理速度加快了45.1%(RTF 0.191 vs.0。RTF是实时因素,即生成一秒钟音频所需的秒数)。

Ablation Studies
我们进行消融研究以证明我们提出的方法的有效性,并进行一些超参数研究以寻求最佳模型配置。我们对这些实验进行CMOS评估。
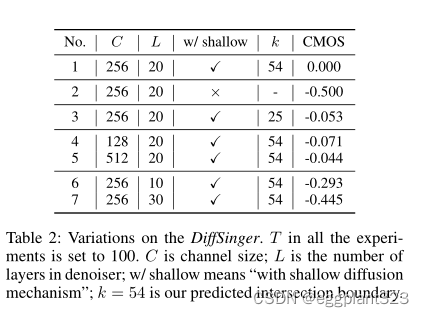
DiffSinger的变化结果列于表2中。
可以看出:
1)去除浅扩散机制导致质量下降(-0。CMOS),这与MOS测试结果一致,并验证了我们的浅扩散机制的有效性(第1行对第2行);
2) 采用其他k(第1行对第3行)而不是我们的边界预测器预测的k会导致质量下降,这验证了我们的边界预测网络可以为浅扩散机制预测合适的k;
3)配置为C=256和L=20的模型产生最佳结果(第1行与第4、5、6、7行),表明我们的模型容量足够。
Extensional Experiments on TTS
为了验证我们的方法在TTS任务上的通用性,我们在LJSpeech数据集(Ito和Johnson 2017)上进行了扩展实验,该数据集包含13100个英语音频片段(总计~24小时)和相应的转录本。我们遵循FastSpeech 2中的train-val测试数据集分割、mel声谱图的预处理和grapheme tophoneme工具。为了构建DiffSpeech,我们
- 将音调预测器和持续时间预测器添加到DiffSinger,如FastSpeech 2中的那些;
2) 浅扩散机理采用k=70。
我们使用Amazon Mechanical Turk(10名测试人员)进行主观评估,结果如表3所示。所有系统都采用HiFi GAN(Kong,Kim,and Bae 2020)作为声码器。DiffSpeech的性能优于FastSpeech 2和Glow TTS,证明了其泛化能力。此外,表3中的最后两行也显示了浅扩散机制的有效性(加速率为29.2%,RTF 0.121对0.171)。
Related Work
Singing Voice Synthesis
歌唱声音合成的最初作品使用级联(Macon等人,1997;Kenmochi和Ohshita 2007)或基于HMM的参数(Saino等人,2006;Oura等人,2010)方法生成声音,这些方法有点繁琐,缺乏灵活性和和谐性。由于深度学习的快速发展,在过去几年中,已经提出了几种基于深度神经网络的SVS系统。
Nishimura等人(2016);Blaauw和Bonada(2017);Kim等人(2018);Nakamura等人(2019);Gu等人(2020)利用神经网络将上下文特征映射到声学特征。Ren等人(2020)使用从音乐网站挖掘的歌唱数据从头开始构建SVS系统。Blaauw和Bonada(2020)提出了一种前馈Trans-former SVS模型,用于快速推理和避免自回归模型引起的暴露偏差问题。此外,在对抗性训练的帮助下,Lee等人(2019)提出了一种直接生成线性谱图的端到端框架。Wu和Luan(2020)提出了一种具有有限可用录音的多歌手SVS系统,并通过添加多个随机窗口鉴别器来提高语音质量。Chen等人(2020)引入了多尺度对抗性训练,以高采样率(48kHz)合成歌唱。近年来,SVS系统的语音自然度和多样性不断提高。
Denoising Diffusion Probabilistic Models
扩散概率模型是通过优化变分下界来训练的参数化马尔可夫链,它以恒定的步长生成与数据分布匹配的样本(Ho,Jain,and Abbeel 2020)。Sohl-Dickstein等人(2015)首次提出了扩散模型。Ho、Jain和Abbeel(2020)在扩散模型方面取得了进展,使用一定的参数化生成高质量图像,并揭示了扩散模型和去噪分数匹配之间的等价性(Song和Ermon 2019;Song等人2021)。最近,Kong等人(2021)和Chen等人(2021。Chen等人(2021)还提出了一种连续噪声调度,以减少推理迭代,同时保持合成质量。Song、Meng和Ermon(2021)通过提供更快的采样机制和在样本之间进行有意义插值的方法来扩展扩散模型。扩散模型是一种新兴的技术,已被应用于无条件图像生成、条件谱图到波形生成(神经声码器)等领域。在我们的工作中,我们为声学模型提出了一个扩散模型,该模型在给定乐谱(或文本)的情况下生成融合谱图。在我们的预印本提交时,有一项并行工作(Jeong等人,2021)采用扩散模型作为TTS任务的声学模型。
Conclusion
在这项工作中,我们提出了DiffSinger,一种基于扩散概率模型的SVS声学模型。为了提高语音质量和加快推理速度,我们提出了一种浅层扩散机制。具体来说,我们发现当扩散步长足够大时,M和fM的扩散轨迹收敛在一起。受此启发,我们在两条轨迹的交点(步骤k)开始了反向过程,**而不是在非常深的扩散步骤T。**因此,可以明显减轻反向处理的负担,从而提高合成音频的质量并加速推理。在PopCS上进行的实验证明了DiffSinger与以前的工作相比的优越性,以及我们新的浅层扩散机制的有效性。在LJSpeech数据集上进行的扩展实验证明了DiffSpeech在TTS任务中的有效性。无声码器的直接合成将是未来的工作。

















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









