







FS2 note
Fastspeech end-to-end
数据的preprocess
dataset: LJspeech
Prepare align 生成raw_data文件夹
Prepare preprocess 生成preprocessed_data文件夹
使用pretrain的model 得知音素和duration之间的align关系
Train
Python3 train.py
判断是CUDA还是cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
加载config 配置文件
preprocess_config, model_config, train_config = configs
首先加载数据 dataloader
# Get dataset
dataset = Dataset(
"train.txt", preprocess_config, train_config, sort=True, drop_last=True
)
batch_size = train_config["optimizer"]["batch_size"]
group_size = 4 # Set this larger than 1 to enable sorting in Dataset
assert batch_size * group_size < len(dataset)
loader = DataLoader(
dataset,
batch_size=batch_size * group_size,
shuffle=True,
collate_fn=dataset.collate_fn,
)
group_size 分组 提高效率
Get data
Dataloader torch库取数据集到loader
dataset.py
_getitem__方法根据给定的索引idx返回一个样本。它从预处理路径中加载预处理的音频和文本数据,然后返回一个包含音频特征、音频基频、音频能量、音频持续时间等的字典样本。
process_meta方法用于处理元数据文件,将文件中的每一行按照分隔符|进行分割,并返回音频文件名、说话人、文本和原始文本的列表
准备好model模块
# Prepare model
model, optimizer = get_model(args, configs, device, train=True)
model = nn.DataParallel(model)
num_param = get_param_num(model)
Loss = FastSpeech2Loss(preprocess_config, model_config).to(device)
print("Number of FastSpeech2 Parameters:", num_param)
get_model from fastspeech2.py
class FastSpeech2(nn.Module):
""" FastSpeech2 """
def __init__(self, preprocess_config, model_config):
super(FastSpeech2, self).__init__()
self.model_config = model_config
self.encoder = Encoder(model_config)
self.variance_adaptor = VarianceAdaptor(preprocess_config, model_config)
self.decoder = Decoder(model_config)
self.mel_linear = nn.Linear(
model_config["transformer"]["decoder_hidden"],
preprocess_config["preprocessing"]["mel"]["n_mel_channels"],
)
self.postnet = PostNet()
self.speaker_emb = None
if model_config["multi_speaker"]:
with open(
os.path.join(
preprocess_config["path"]["preprocessed_path"], "speakers.json"
),
"r",
) as f:
n_speaker = len(json.load(f))
self.speaker_emb = nn.Embedding(
n_speaker,
model_config["transformer"]["encoder_hidden"],
)
def forward(
self,
speakers,
texts,
src_lens,
max_src_len,
mels=None,
mel_lens=None,
max_mel_len=None,
p_targets=None,
e_targets=None,
d_targets=None,
p_control=1.0,
e_control=1.0,
d_control=1.0,
):
src_masks = get_mask_from_lengths(src_lens, max_src_len)
mel_masks = (
get_mask_from_lengths(mel_lens, max_mel_len)
if mel_lens is not None
else None
)
output = self.encoder(texts, src_masks)
if self.speaker_emb is not None:
output = output + self.speaker_emb(speakers).unsqueeze(1).expand(
-1, max_src_len, -1
)
(
output,
p_predictions,
e_predictions,
log_d_predictions,
d_rounded,
mel_lens,
mel_masks,
) = self.variance_adaptor(
output,
src_masks,
mel_masks,
max_mel_len,
p_targets,
e_targets,
d_targets,
p_control,
e_control,
d_control,
)
output, mel_masks = self.decoder(output, mel_masks)
output = self.mel_linear(output)
postnet_output = self.postnet(output) + output
return (
output,
postnet_output,
p_predictions,
e_predictions,
log_d_predictions,
d_rounded,
src_masks,
mel_masks,
src_lens,
mel_lens,
)
- 初始化模型中的各个组件,包括编码器 (encoder)、变换器适配器 (variance_adaptor)、解码器 (decoder)、线性层 (mel_linear) 和后处理网络 (postnet)。
- 如果模型配置中包含多个说话者 (multi_speaker=True),则创建一个说话者嵌入层 (speaker_emb),用于处理说话者信息。
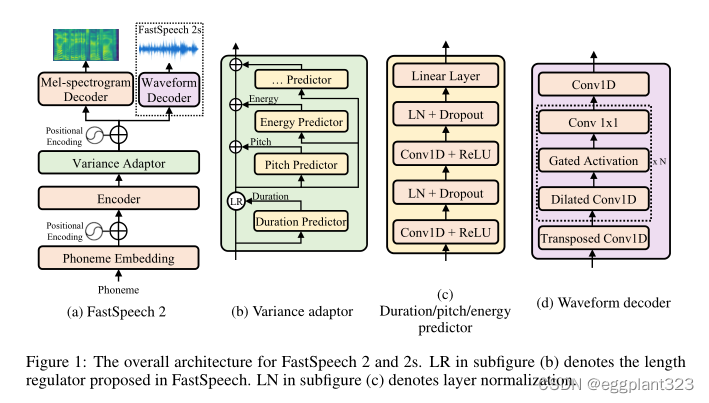
所以总结核心的部分是encoder variance_adaptor decoder
encoder:
class Encoder(nn.Module):
""" Encoder """
def __init__(self, config):
super(Encoder, self).__init__()
n_position = config["max_seq_len"] + 1
n_src_vocab = len(symbols) + 1
d_word_vec = config["transformer"]["encoder_hidden"]
n_layers = config["transformer"]["encoder_layer"]
n_head = config["transformer"]["encoder_head"]
d_k = d_v = (
config["transformer"]["encoder_hidden"]
// config["transformer"]["encoder_head"]
)
d_model = config["transformer"]["encoder_hidden"]
d_inner = config["transformer"]["conv_filter_size"]
kernel_size = config["transformer"]["conv_kernel_size"]
dropout = config["transformer"]["encoder_dropout"]
self.max_seq_len = config["max_seq_len"]
self.d_model = d_model
self.src_word_emb = nn.Embedding(
n_src_vocab, d_word_vec, padding_idx=Constants.PAD
)
self.position_enc = nn.Parameter(
get_sinusoid_encoding_table(n_position, d_word_vec).unsqueeze(0),
requires_grad=False,
)
self.layer_stack = nn.ModuleList(
[
FFTBlock(
d_model, n_head, d_k, d_v, d_inner, kernel_size, dropout=dropout
)
for _ in range(n_layers)
]
)
def forward(self, src_seq, mask, return_attns=False):
enc_slf_attn_list = []
batch_size, max_len = src_seq.shape[0], src_seq.shape[1]
# -- Prepare masks
slf_attn_mask = mask.unsqueeze(1).expand(-1, max_len, -1)
# -- Forward
if not self.training and src_seq.shape[1] > self.max_seq_len:
enc_output = self.src_word_emb(src_seq) + get_sinusoid_encoding_table(
src_seq.shape[1], self.d_model
)[: src_seq.shape[1], :].unsqueeze(0).expand(batch_size, -1, -1).to(
src_seq.device
)
else:
enc_output = self.src_word_emb(src_seq) + self.position_enc[
:, :max_len, :
].expand(batch_size, -1, -1)
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(
enc_output, mask=mask, slf_attn_mask=slf_attn_mask
)
if return_attns:
enc_slf_attn_list += [enc_slf_attn]
return enc_output
初始化
- 创建源词嵌入层 (src_word_emb),用于将输入序列中的词索引转换为词嵌入向量。
- 创建位置编码层 (position_enc),用于为输入序列的每个位置生成位置编码。
- 创建一系列的 FFTBlock 层 (layer_stack),根据配置参数的设置确定层数。
加mask的原因:
- 源文本掩码(src_masks):掩码用于将源文本的填充部分屏蔽,以便在Transformer的编码器中忽略这些填充部分。通过获取填充部分的长度信息,可以创建一个掩码张量,其中填充部分对应的位置被设置为0,而有效部分对应的位置被设置为1。
- 语音特征掩码(mel_masks):在模型的训练过程中,语音特征(如梅尔频谱)的长度会根据不同的输入文本长度而变化。为了使所有的语音特征序列具有相同的长度,需要对其进行填充,并使用掩码将填充部分屏蔽。通过获取语音特征序列的长度信息,可以创建一个掩码张量,其中填充部分对应的位置被设置为0,而有效部分对应的位置被设置为1。
- 使用掩码进行注意力操作:在Transformer的解码器中,注意力操作涉及对源文本编码输出的加权求和。通过使用源文本掩码,可以确保在计算注意力权重时,填充部分的编码输出对解码器的影响被忽略。
input:src_seq, mask,(return_attns=false)
输入序列 (src_seq)、掩码 (mask),以及是否返回注意力权重的标志 (return_attns)
这里的forward有点特殊的是
- 如果不是train的过程 是inference且长度大于max_seq_len那么采取:先嵌入转换----生成位置编码表(长度为输入序列长度,维度为编码器维度)----切片操作编码表----与词嵌入层进行相加
- 如果仍是train 或者长度没有超过:word embedding----position encoder----add together get encoder output
4层的FFT层(enc_layer)
Variance adaptor
predictor:基于encoder的output作为输入 通过卷积和线性层进行predict 输出结果通过ReLU,通过一个线性层输出
lengthregulator:调整停牌长度 input: encoder_output, duration
get_pitch_embedding、get_energy_embedding:使用了variance predictor预测----bucketize转换为离散的嵌入索引 -----embedding层获取嵌入向量
Conv class:
1D卷积
Variance predictor:
input: encoder_output,mask
encoder_output----conv_layer----linear_layer(linear)----squeeze----mask----output:out
conv_layer:conv1D–relu–layernorm–dropout–conv1D–relu–norm–dropout padding:keep same length
get_pitch_embedding get_energy_embedding:
input: x,target,mask,control
用predictor先预测,如果不是none 那么就用目标音高embedding;如果是none,就是用预测的音高乘以control的参数。
output:prediction和embedding
forward
如果存在持续时间目标(duration_target),则使用self.length_regulator函数将x的长度调整为目标长度,并将调整后的持续时间赋值为duration_rounded。否则,根据log_duration_prediction计算持续时间,并进行四舍五入和控制参数的调整。最后,再次调用self.length_regulator函数对x进行长度调整,并计算音频特征的掩码(mel_mask)。
decoder
与encoder几乎类似 FFT层数定为6
Postnet
Five 1-d convolution with 512 channels and kernel size 5
初始化结束,到具体函数部分:
output = self.encoder(texts, src_masks)
首先输入text,通过encoder得到output
(
output,
p_predictions,
e_predictions,
log_d_predictions,
d_rounded,
mel_lens,
mel_masks,
) = self.variance_adaptor(
output,
src_masks,
mel_masks,
max_mel_len,
p_targets,
e_targets,
d_targets,
p_control,
e_control,
d_control,
)
通过variance模块,得到想要的output
output, mel_masks = self.decoder(output, mel_masks)
output = self.mel_linear(output)
postnet_output = self.postnet(output) + output
decoder----linear----postnet
Inference
synthesizer模块
加载相关的model等模块到这个python文件中
Single model
- 函数preprocess_english通过去除标点符号、转换单词为音素序列,并将其转换为数字序列,对英文文本进行了预处理操作
- 然后作为input到synthesizer的地方















 8757
8757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









