







Abstract
使用从现成的神经音频编解码器模型导出的离散代码来训练neural codec language model(称为VALL-E),并将TTS视为一个条件语言建模任务,而不是像以前的工作中那样进行连续信号回归。在预训练阶段,我们将TTS训练数据扩展到60K小时的英语语音,这比现有系统大数百倍。VALL-E出现在上下文学习能力中,可以用于合成高质量的个性化语音,只需3秒记录一个看不见的扬声器作为声学提示。实验结果表明,VALL-E在语音自然度和说话者相似度方面显著优于现有的零样本TTS系统。此外,我们发现VALL-E可以在合成中保留说话人的emotion and acoustic environment of the acoustic Prompt
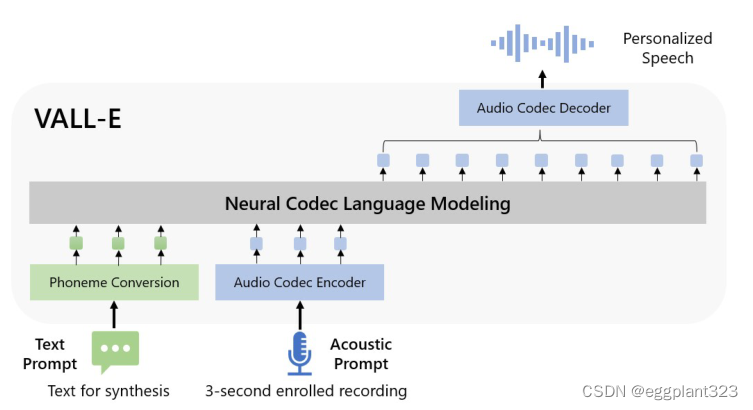
VALL-E model 框架: 与之前的管道不同(例如,音素→ mel光谱图→ 波形),VALL-E的流水线是音素→ 离散代码→ 波形。VALL-E基于音素和声学代码提示生成离散音频编解码器代码,对应于目标内容和说话者的语音。VALL-E直接支持各种语音合成应用,如零样本TTS、语音编辑和内容创建,并与其他生成人工智能模型相结合
Introduction
目前,cascaded text to speech(TTS)系统通常利用具有acoustic model的管道和使用mel声谱图作为中间表示的vocoder。虽然先进的TTS系统可以合成来自单个或多个扬声器的高质量语音,但它仍然需要来自录音室的高质量干净数据。从互联网上抓取的大规模数据不能满足要求,并且总是导致性能下降。由于训练数据相对较小,目前的TTS系统仍然存在泛化能力差的问题。在zero-shot情景中,unseen speaker的相似性和语音自然度显著下降。
为了解决zero-shot TTS问题,现有工作利用了speaker adaptation和speaker encoding方法,需要额外的finetuning、复杂的预先设计功能或重结构工程。
近年来,文本语言模型中的数据增长性能显著提高,从16GB的未压缩文本,最后达到1TB左右。将这一成功转移到语音合成领域,我们引入了VALL-E,这是第一个利用大量、多样化和多说话者语音数据的基于语言模型的TTS框架。如图1所示,为了合成个性化语音(例如,zero-shot TTS),VALL-e以3秒enrolled recording的声学令牌和phoneme prompt提示为条件,生成相应的acoustic token,分别约束speaker和content信息。
最后,使用生成的声学令牌与相应的neural codec decoder合成最终波形。从音频编解码器模型导出的离散声学标记使我们能够将TTS视为条件编解码器语言建模,并且可以将基于提示的高级大模型技术用于TTS任务。声学标记还允许我们通过在推理过程中使用不同的采样策略在TTS中生成不同的合成结果。
使用LibriLight训练VALL-E,LibriLight是一个由6000小时的英语演讲组成的语料库,有7000多名独特的演讲者。原始数据仅为音频,因此我们使用语音识别模型来生成转录。与以前的TTS训练数据集相比,我们的数据包含更嘈杂的语音和不准确的转录,但提供了不同的说话者和韵律。
我们相信所提出的方法对噪声是鲁棒的,并且通过利用大数据可以很好地推广。值得注意的是,现有的TTS系统总是用几十小时的单扬声器数据或数百小时的多扬声器数据进行训练,这比VALL-E小数百倍以上。表总结了VALLE的创新,VALLE是TTS的一种语言模型方法,使用音频编解码器代码作为中间表示,利用大量多样的数据,产生强大的上下文学习能力。

VALL-E能够在两个相同的文本和目标说话人的情况下合成不同的输出,这有利于语音识别任务的伪数据创建。
我们还发现,VALL-E可以保持声学提示的声学环境(如混响)和情绪(如愤怒)。
Contribution
- 它具有上下文学习能力,并支持基于提示的零样本TTS方法,这不需要像以前的工作那样进行额外的结构工程、预先设计的声学特征和微调。
- 利用大量的半监督数据,在说话人维度上构建了一个通用的TTS系统,这表明TTS低估了简单的半监督扩展数据。
- VALL-E能够在相同的输入文本下提供不同的输出,并保持声学提示的声学环境和说话者的情绪。
- Zero-shot 效果更佳
Related work
VALL-E是第一个使用音频编解码器代码作为中间表示,并在零样本TTS中出现上下文学习功能。
Background: speech quantization
由于音频通常存储为16位整数值的序列,因此需要生成模型在每个时间步长输出2^16=65536个概率来合成原始音频。此外,超过一万的音频采样率会导致超长的序列长度,这使得原始音频合成更加困难。为此,需要语音量化来压缩整数值和序列长度。µ-law变换可以将每个时间步长量化为256个值,并重建高质量的原始音频。
它被广泛用于语音生成模型,如WaveNet,但由于序列长度没有减少,推理速度仍然很慢。最近,矢量量化被广泛应用于自监督语音模型中进行特征提取,如vq-wav2vec和HuBERT。以下工作表明,来自自监督模型的代码也可以重构内容,并且推理速度比WaveNet更快。然而,说话人身份已被丢弃,重建质量较低。AudioLM在自监督模型的k-means标记和neural codec model模型的声学标记上训练语音到语音语言模型,从而产生高质量的语音到语音生成。
在本文中,我们遵循AudioLM,利用neural codec models来表示discrete tokens的语音。为了压缩音频以进行网络传输,编解码器模型能够将波形编码为离散的声学代码,并重建高质量的波形,即使speaker在训练中unseen。与传统的音频编解码器方法相比,基于神经的编解码器在低比特率下明显更好,并且我们相信量化的令牌包含关于扬声器和录音条件的足够信息。
与其他量化方法相比,audio codec显示出以下优势:
- 它包含丰富的说话人信息和声学信息,与HuBERT码相比,可以在重构中保持说话人身份
- 有一种现成的编解码器可以将离散令牌转换为波形,而无需像在频谱上操作的基于VQ的方法那样在声码器训练上付出额外的努力
- 它可以缩短时间步长以提高效率,从而解决µ-law转换中的问题(inference速度慢)
我们采用预先训练的神经音频编解码器模型EnCodec作为我们的tokenizer。
VALL-E
Problem Formulation: Regarding TTS as Conditional Codec Language Modeling
给定数据集D={xi,yi},其中y是音频样本,x={x0,x1,…,xL}是其对应的音素转录,我们使用预先训练的神经编解码器模型将每个音频样本编码为离散的声学代码,表示为Encodec(y)。
零样本TTS要求模型为看不见的说话者合成高质量的语音。在这项工作中,我们将零样本TTS作为一个条件编解码器语言建模任务。
我们期望神经语言模型分别从音素序列和声学提示中提取内容和说话者信息。在推理过程中,给定音素序列和看不见的说话者的3秒注册记录,首先通过训练的语言模型来估计具有相应内容和说话者声音的声学代码矩阵。然后neural codec decoder合成高质量的语音。
Training: Conditional Codec Language Modeling
神经语音编解码器模型允许我们对离散音频表示进行操作。由于神经编解码器模型中的残差量化,令牌具有分层结构:来自先前量化器的令牌恢复扬声器身份等声学特性,而连续量化器学习精细的声学细节。训练每个量化器以对来自先前量化器的残差进行建模。
受此启发,以分层的方式设计了两个条件语言模型。对于来自第一量化器c:,1的离散令牌,我们训练仅自回归(AR)解码器的语言模型。它以音素序列x和声学提示~C:,1为条件,公式为
![[图片]](https://img-blog.csdnimg.cn/d46ef950efc040d9a2de90caa4cae2e7.png)
对于从第二个量化器到最后一个量化器的离散标记c:,j∈[2,8],我们训练了一个非自回归(NAR)语言模型。由于令牌不能以NAR方式相互访问,为了约束说话者身份,使用声学提示矩阵~C作为声学提示。
![[图片]](https://img-blog.csdnimg.cn/137525e030b444a9960e92189d414999.png)
![[图片]](https://img-blog.csdnimg.cn/ad884b720725487ea64755cd15420f12.png)
Autoregressive Codec Language Modeling
自回归语言模型从第一量化器生成令牌。它包括音素嵌入Wx、声学嵌入Wa、变换解码器和预测层。
为了生成具有特定内容的语音,使用音素序列作为语言模型的音素提示。
Non-Autoregressive Codec Language Modeling
当我们通过AR模型获得第一个量化器代码时,我们使用非自回归(NAR)模型来生成其他七个量化器的代码。NAR模型具有与AR模型类似的架构,只是它包含八个独立的声学嵌入层。在每个训练步骤中,我们随机抽取一个训练阶段i∈[2,8]。训练该模型以最大化来自第i个量化器码本的声学标记。
与AR不同,NAR模型允许每个令牌关注自关注层中的所有输入令牌。我们还共享声学嵌入层和输出预测层的参数,这意味着第j个预测层的权重与第(j+1)个声学嵌入层的权重相同。
Inference: In-Context Learning via Prompting
上下文学习是基于文本的语言模型的一种令人惊讶的能力,它能够在没有额外参数更新的情况下预测看不见的输入的标签。对于TTS,如果该模型能够在不进行微调的情况下为看不见的说话者合成高质量的语音,则该模型被认为具有上下文学习能力。然而,现有TTS系统的上下文学习能力并不强,因为它们要么需要额外的微调,要么对看不见的说话者显著降低。对于语言模型,提示对于在零样本场景中实现上下文学习是必要的。
首先将文本转换为音素序列,并将登记的录音编码为声学矩阵,形成音素提示和声学提示。这两种提示都用于AR和NAR模型。对于AR模型,我们使用基于提示的采样解码,因为我们观察到波束搜索可能会导致LM进入无限循环。此外,基于采样的方法可以显著增加输出的多样性。对于NAR模型,我们使用贪婪解码来选择概率最高的令牌。最后,我们使用神经编解码器来生成以八个代码序列为条件的波形。声学提示可能在语义上与要合成的语音相关,也可能不与之相关,从而导致两种情况:
- VALL-E:我们的主要兴趣是为看不见的演讲者生成给定的内容。该模型给出了一个文本句子、一段收录的语音及其相应的转录。我们将注册语音的转录音素预先添加到给定句子的音素序列中作为音素提示,并使用注册语音的第一层声学标记~c:,1作为声学前缀。通过音素提示和声学前缀,VALL-E为给定文本生成声学标记,克隆该说话者的声音。
- VALL-E-continual: 在这种设置中,我们使用整个转写和话语的前3秒分别作为音素和声学提示,并要求模型生成延续。推理过程与设置VALL-E相同,只是注册的语音和生成的语音在语义上是连续的。















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









