







Can Speaker Augmentation Improve Multi-Speaker End-to-End TTS?
abstract
先前关于端到端语音合成的说话人自适应的工作在说话人相似性方面仍然不足。我们通过创建人工扬声器和利用低质量数据,研究了当前扬声器自适应范式的正交方法,即扬声器增强。对Tacotron2基本模型进行了修改,以考虑这些语料库中固有的渠道和方言因素。此外,我们还介绍了Tacotron2训练中采用的热身训练策略。进行了大规模的听力测试,并采用距离度量来评估方言的综合性。然后分析了合成质量、说话人和方言的相似性,并对我们的说话人扩充方法的有效性进行了评价。
introduction
端到端文本到语音(TTS)合成的最新进展使得能够产生高质量和良好的说话者相似性的合成语音。尽管语音质量接近人类的自然度,但挑战仍然存在:首先,使用一个通用模型同时对许多说话者进行建模(称为“多说话者TTS”),其次,适应任意新说话者的声音,同时最大限度地减少要收集的数据量,并且几乎不需要或根本不需要额外的模型训练(也称为“说话者自适应”)。
以往关于说话人适应的工作可以分为两种一般方法之一。第一种方法是简单的微调:TTS模型使用目标说话者数据接收少量额外的训练,这些数据必须转录。第二种方法是使用外部说话者嵌入,这些嵌入是从单独训练的自动说话者验证(ASV)模型中提取的,并且嵌入作为说话者信息输入到TTS模型中。这种方法不需要转录,并且可以仅从少数话语中计算说话人嵌入。然而,据报道,看不见的说话者的说话者相似性相对较低。
另一方面,有一些尝试使用低质量的TTS录音。在中,低质量的录音被用于基于微调的扬声器自适应。基于变分自动编码器的干净语音和噪声分解也被提出用于Tacotron TTS。他们使用人工破坏的语音数据或真实的有噪声语音进行了说话人自适应,并试图通过所提出的因子分解来创建说话人自适应的“干净”TTS语音。在我们之前的工作中,我们在VCTK语料库上构建了一个多说话者Tacotron TTS模型,使用从单独训练的ASV模型转移来的说话者嵌入。并执行零样本扬声器自适应。VCTK数据集包含来自大约一百个不同英语方言的使用者的高质量语音记录。然而,我们的模型对可见说话者进行了过度拟合,尽管合成语音的质量很高,但看不见说话者的语音特征和方言并没有很好地再现。我们假设,对于我们的任务来说,这个speaker的数量可能很小,增加训练扬声器的数量可以更好地覆盖扬声器空间,避免过度适应可见扬声器,从而提高看不见扬声器的相似性和感知方言。然而,大于VCTK的TTS质量数据集不容易找到或创建。
一个更现实的解决方案是说话人扩充,即数据扩充,用于增加用于神经网络训练的说话人数量。这已经针对ASV进行了研究,其中他们通过简单地重新采样原始音频来创建“人造”speaker。他们发现,这种方法改进了他们的扬声器模型,而且他们的系统将人造扬声器识别为与原始扬声器分离。
这被称为“声道长度扰动”(VTLP),它还改善了ASR。这可能对多扬声器TTS有用,因为通过添加更多的扬声器,我们可以希望神经网络能够意识到更多样的扬声器特性,从而避免过度适应可见扬声器。
除了上述人工扬声器增强之外,我们还考虑了扬声器增强的另一个想法,其中我们使用非理想的TTS数据,即为TTS以外的目的收集的录音,这些录音可能不符合我们通常的高质量录音标准,但有更大数量的扬声器。然而,不小心地混合来自较差记录条件的数据预计会降低合成语音的质量。此外,与人工说话人增强不同,它还增加了训练数据库中包含的不同方言的数量。因此,我们再次借鉴了说话人识别的思想,比如我们之前论文中的神经说话人嵌入,并提出了一种改进的Tacotron语音合成器来明确处理两个因素,通道和方言。这里,通道是由录音设备的频率特性、噪声和混响共同引起的因素。更准确地说,在所提出的合成器中,神经方言嵌入向量用于调节Tacotron的编码器,信道标签用于调节Tacotron的postnet。
Speaker Augmentation for TTS
数据增强已被证明对语音识别和说话人识别非常有效。尽管过去曾研究过语音合成的数据增强,但改进幅度相当小,语音合成的最佳增强策略仍然未知。在本文中,我们考虑了两种扬声器增强思想,并研究了这种增强如何改进多扬声器端到端TTS。
Artificial speaker augmentation
扬声器增强的第一种方法与相同,其中我们通过操纵高质量的音频信号来创建“人造”speaker。这是对波形的重新采样,产生的信号具有不同的基频、说话速率、共振峰和频谱。我们使用SoX“速度”命令实现了这种增强,该命令通过重新采样来加速或减慢音频。我们创建了每个VCTK说话者语音的“x0.9”和“x1.1”重采样版本,并使用该增强数据集来训练说话者增强的Tacotron模型。
Speaker augmentation using low-quality data
扬声器增强的第二种方法是使用为TTS以外的目的收集的低质量数据,例如ASR(自动语音识别)。这样的数据可以代表不同范围的说话者和方言,并且可以用于语音合成的说话者增强的目的。我们的目标是仅将低质量数据用于speaker增强,并且我们假设目标speaker数据是有限的,但记录在高质量的录音室中。这与之前的工作不同,之前的工作使用低质量的录音进行扬声器自适应和多扬声器建模。
然而,这样的ASR数据不符合我们的高质量记录标准。它可能包含背景噪声和混响,不同于在轶事室中记录的典型TTS数据。此外,与人工说话人增强不同,它还增加了训练数据库中包含的不同方言的数量。因此,我们修改了Tacotron TTS的两个部分,它们使用神经扬声器嵌入来明确处理由扬声器增强的低质量数据带来的两个因素,通道和方言,如图1所示。
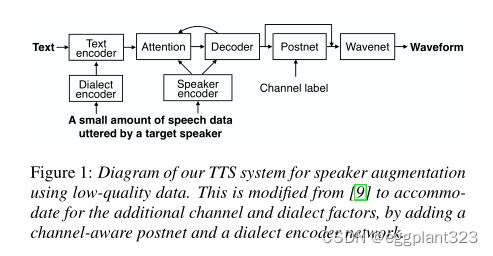
渠道感知postnet:第一次修订是使Tacotron的postnet依赖于渠道信息。在这里,通道意味着所有的录音设备、噪音和混响。我们只需使用一个热通道标签,指示训练期间每个话语来自哪个数据集。该信道标签被输入到后网的每个卷积层,后者控制由Tacotron解码器预测的频谱的整形和增强。然后,在合成时,我们选择最高质量的通道设置(VCTK),这将允许模型产生具有更好的扬声器表示和高音频质量的语音。这个想法与有关,其中信道因子用于调节解码器。在我们的想法中,我们将Tacotron视为一个语音生产模型,并将其postnet重新解释为一个渠道模型。
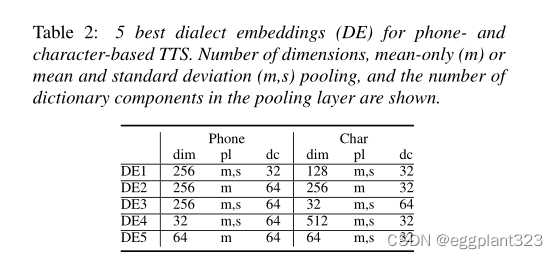
方言编码器网络和神经方言嵌入:第二次修订是使Tacotron的编码器依赖于训练和适应数据中包含的目标说话者的方言。我们的目标是为所有扬声器使用通用电话或字符输入,并基于从音频信号计算的神经方言嵌入向量对Tacotron的编码器进行因子分解。方言识别可以被视为口语识别的一个子任务,通常,说话人识别任务的方法可以直接转移到方言识别。因此,与我们的扬声器编码器网络类似,我们在方言编码器网络中重用了基于可学习字典编码(LDE)的网络架构。
Experiments
setup
我们使用两个基线模型,一个是基于音素的模型,它与我们之前工作中的最佳系统相同,另一个是具有字符输入的模型。4个扬声器被作为验证数据,4个扬声器作为测试集。使用在同一VCTK训练集上训练的WaveNets,将Tacotron输出的80维mel频谱图转换为16kHz波形。
Artificial speaker augmentation
我们创建了一个增强的VCTK数据集,如第2.1节所述,通过加速和减慢每个原始VCTK说话者的语音,并赋予他们唯一的说话者身份,从而产生了原始数据集的三倍多的“说话者”。然后,除了使用更大的增强数据集外,我们以与基线相同的方式训练了基于字符和基于语音的模型。
Speaker augmentation using low-quality ASR corpora
我们使用VCTK和为ASR收集的各种语料库创建了一个用于TTS训练的大型混合数据集,其中包含各种记录条件和英语方言。当我们拿出每个语料库的一些部分进行验证和测试时,我们将实际评估的重点放在VCTK说话者身上。
我们再一次训练了字符输入和电话输入模型。我们使用标准的训练/验证/测试集(在定义它们的地方),以及预定义的适应话语或扬声器之间常见的话语来提取扬声器嵌入。我们保持训练扬声器的数量与人工增强的VCTK集合中的相同。每个语料库选择两位演讲者添加到我们的开发集合中,用于初步模型评估和选择。下面,我们简要描述了在我们的多说话者TTS训练中使用的四个ASR语料库(关于说话者数量的信息见表1):
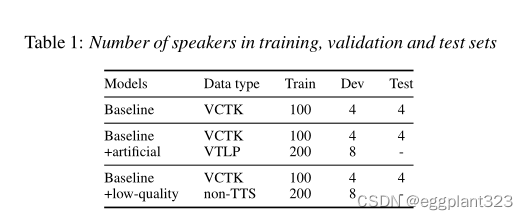
GRID,WSJ1,WSJCAM ,TIMIT——使用数据集
Modeling channel and dialect factors
**GT频道标签:**除了通过将VCTK与四个新的ASR语料库混合直接训练外,我们还训练了带有地面实况频道标记的电话和角色模型。我们使用一个热编码来指示每个训练话语来自哪个语料库,并且通道标签被输入到Tacotron postnet。
LDE-based neural dialect embeddings: 鉴于我们的目标是只模拟英语方言,使用标准的NIST LRE配方并不理想。我们选择使用具有六种英语方言的A TR方言语料库:澳大利亚语、英国语和各种美国英语。阅读和自发的语音记录被采样,以便它们在训练中保持平衡。我们的方言编码器网络是基于LDE的,我们进行了超参数扫描。与说话人嵌入类似,我们计算了合成语音和基本事实语音的方言嵌入之间的余弦相似性得分,并相应地为电话和字符模型选择了五个最佳嵌入。这些嵌入的详细信息见表2。
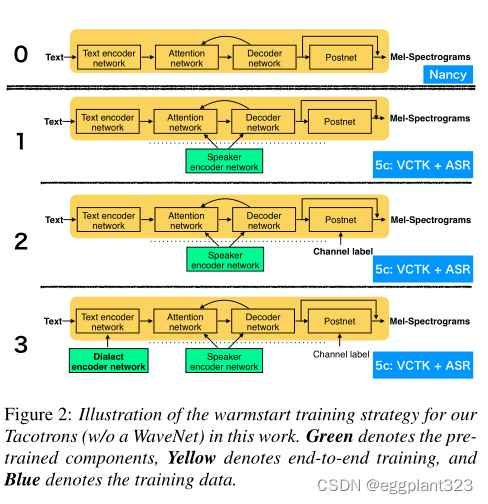
暖启动训练策略:我们采用了暖启动训练方案,其中整个Tacotron训练分为四个阶段(见图2),每个阶段的参数都从前一阶段的参数初始化。在第0阶段,在暴雪2011的Nancy数据集上训练种子单扬声器Tacotron2。在第一阶段,我们在5个语料库(VCTK+ASR)上训练了一个多物种性别依赖模型,参数从上一步初始化,并包括从单独训练的LDE模型中提取的扬声器嵌入,该模型具有均值池和角度softmax,在VoxCeleb上训练。这些嵌入与编码器的输出和注意力机制的输入以及解码器的prenet的输入串联[9]。在第二阶段,我们添加了频道标签。最后,在第3阶段,使用电话或字符模型的前5个方言嵌入之一,我们继续使用所有五个语料库、频道标签以及说话者和方言嵌入进行训练。每个阶段都经过训练,直到收敛。
Subjective evaluation setup
我们对以英语为母语的听众进行了一次众包在线听力测试。我们要求听众对每个样本的自然度进行1-5的平均意见得分(MOS)评分,并对说话者相似性进行1-5的差分MOS(DMOS)评分。我们还要求听众从六个选项中对方言提出明确的意见:美国语、加拿大语、英语、爱尔兰语、北爱尔兰语和苏格兰语。由于听众可能不熟悉这些口音,我们还在一个单独的网页上提供了未包含在测试中的VCTK扬声器的每个口音的参考样本,听众可以选择参考。
我们评估了20个不同的系统:自然语音、使用WaveNet的声码语音、电话和字符基线、VTLPagmented模型、使用额外ASR数据训练的总共5个训练语料库的模型(5c)、具有5c和通道标签(CL)的模型,以及具有5c+CL+方言嵌入(DE)的模型。对于每个系统,我们使用4个VCTK训练集(可见)扬声器、4个开发集扬声器和4个测试集扬声器(完全看不见)中的每个扬声器在训练过程中看不见的文本生成了20个样本。我们将样本分组为每组40个话语的集合,并让5个不同的听众对每组进行评估。共有60名听众完成了这项测试,每组10套。
方言混淆程度评价指标:由于方言识别即使对母语听众来说也是一项具有挑战性的任务,我们评估了真实口音与猜测口音的混淆矩阵。我们计算了自然语音方言的混淆矩阵和每个TTS系统的混淆矩阵之间的Frobenius距离,基于这样的想法,即如果TTS的混淆矩阵与自然语音的混淆矩阵相似,那么口音就可以很好地表示。
Subjective evaluation results and analysis
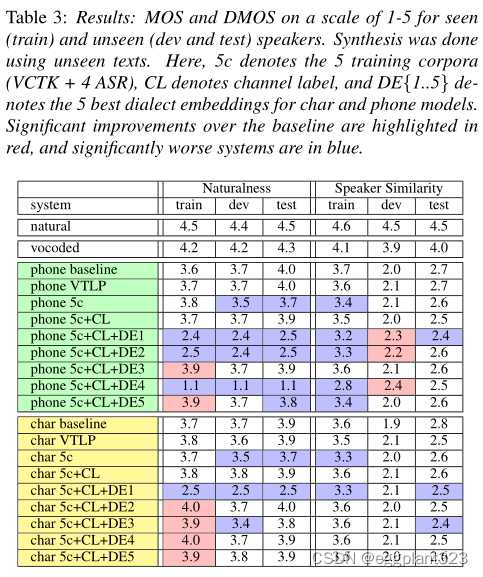
MOS和DMOS结果如表3所示。使用Mann-Whitney U检验在p=0.01的阈值下测量统计显著性,并将系统与其各自的基线(即电话或字符)进行比较。明显较好和较差的系统分别用红色和蓝色突出显示。
A) Baseline vs. speaker augmentation
MOS和DMOS的结果显示出一种意想不到但有趣的趋势。与我们最初的预期相反,**当低质量数据、通道感知的postnet和方言感知的编码器都用于Tacotron训练时,我们获得了可见说话者自然度的统计显著改善。**这在两个方面令人惊讶。**首先,说话者的增加有助于自然度,而不是说话者的相似性。**其次,添加低质量的数据矛盾地提高了可视说话者的合成语音质量。这有点令人惊讶,但这一现象已经在2个基于电话的系统和4个基于字符的系统中得到了明确的证实。
手机和字符系统的MOS分数分别从3.6分提高到3.9分和3.7分提高到4.0分。对于一些基于手机的系统,开发套件扬声器的扬声器相似性也从2.0提高到2.4。我们可以推测,增加方言建模和更多不同的说话者有助于捕捉语音的重要方面,但在训练中看到的对说话者的过度拟合仍在发生。
B) Artificial vs. low-quality data:
接下来,我们看到VTLP(人工说话人增强)并没有提高自然度或说话人相似性,尽管已知这种方法在其他任务中效果良好。另一方面,不小心混合非理想数据确实会使结果恶化:我们看到,在某些情况下,简单地混合低质量数据会产生明显更差的结果,而添加通道感知后网只会在与方言嵌入相结合时显示出改进。这表明我们需要正确处理渠道和方言因素
C) Impacts of dialect encoders
表3的一个含义是,不同类型的方言编码器对合成的影响尚不清楚,包括它们并不能持续提高自然度和说话者相似性。然而,它们对于更好的方言建模似乎是必要的(见表4)。
D) Dialect identification and confusion:
表4显示了代表感知方言混淆的弗罗贝尼乌斯距离。Frobenius距离意味着合成语音感知方言的混淆矩阵与自然语音的混淆矩阵的相似程度。我们观察到隐形扬声器的相对改进(开发和测试)。**所有使用低质量数据的基于手机的系统都比看不见的speaker的基线系统具有更小的Frobenius距离。**这意味着添加低质量的数据有助于我们的合成器更好地生成合适的手机,并根据听众的感知更好地正确匹配方言。
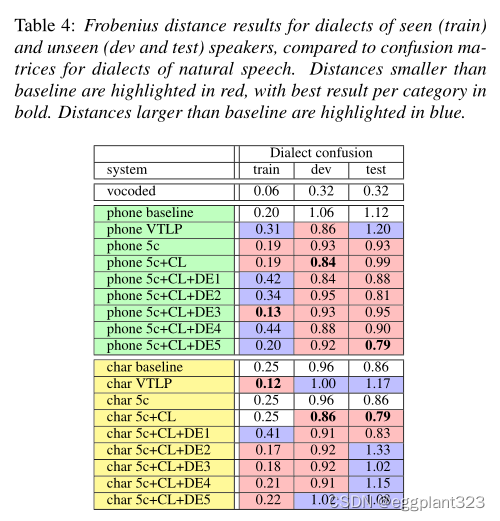
它还帮助一些基于字符的系统使用通道感知postnet和方言感知编码器。另一方面,我们看到,与看到的扬声器相比,看不见的扬声器(dev和test)具有更大的Frobenius距离,即使对于声码语音也是如此。这一趋势与表3中的说话者相似性判断一致。
conclusion
在本文中,我们研究了用于多扬声器端到端语音合成的两种现实的扬声器增强场景:人工增强和使用非理想低质量数据。我们修改了Tacotron的postnet和编码器,以支持低质量数据中的频道和方言变化。实验结果表明,使用不同英语口音的低质量数据是一种有效的多传感器端到端语音合成数据增强方法。与我们最初的预期相反,看到的说话者的自然度已经提高,听众对感知方言的评分与看不见的说话者的天然语音更好地匹配。我们的研究结果表明,提高说话人相似度仍然是一个挑战,未来的工作包括使用大型低质量数据库来训练初始种子模型,并将其微调为高质量的语料库。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









