







Sparse matrix vector multiplication - part 1 — ROCm Blogs (amd.com)

2023年11月3日,作者:[Paul Mullowney](Paul Mullowney — ROCm Blogs)。
稀疏矩阵向量乘法(SpMV)是几乎每种隐式[稀疏线性代数求解器]的核心计算算法。从简单的Krylov算法到多重网格方法,这些算法的性能在很大程度上取决于SpMV实现的速度。由于SpMV的算术强度非常低,算术强度定义为每次内存访问的浮点操作次数,因此实现的速度受内存带宽的限制。最大化内存带宽的实现会比简单的实现具有更优越的性能。或者,利用稀疏矩阵中固有结构从而减少所需内存访问次数的实现,也会获得更高的性能。在这篇博客文章中,我们将开发HIP实现的通用SpMV操作
包括几种标准的SpMV实现格式:
- 标量压缩稀疏行(CSR)
- 向量CSR
- ELLPACK
- 阻塞ELLPACK
许多常见的SpMV API,例如[rocSparse],使用这种通用接口。我们希望在实现与ROCm中提供的实现之间提供公平的比较。在SpMV公式中,α 和 β为标量,A是尺寸为 m×n 的稀疏矩阵,y 是尺寸为 m×1 的稠密向量,x 是尺寸为 n×1 的稠密向量。矩阵的一个关键统计量是每行的平均非零元素数nnz_avg。在这篇文章中,我们将基于这个度量分配不同GPU计算资源的工作负载。
首先,我们将回顾广泛使用的CSR和ELLPACK格式的稀疏矩阵。在描述实现之后,我们将比较它们在AMD MI250X架构对于各种稀疏矩阵的相对性能。从一种矩阵存储格式到另一种的转换算法可能是一个代价高昂的过程。我们的[代码]样例将提供CSR和ELLPACK之间非优化的设备实现的转换算法,但本文将不详细讨论它们。
存储格式
我们首先通过一个简单的例子来回顾不同的稀疏矩阵存储格式。在下面的图中,我们展示了一个 5×5 的矩阵,它有 12 个非零元素。该稀疏矩阵的坐标(COO)格式由三个数组(行、列和值)组成,长度相同。我们使用 0 基索引表示行和列。数据按行优先顺序排序,因此第 0 行的所有数据首先列出,接下来是第 1 行、第 2 行,依此类推。

压缩稀疏行(CSR)格式
CSR 格式用于存储稀疏矩阵,源于对上述行数据结构的简单压缩。首先,我们统计每一行中非零元素的数量。然后,通过对行计数进行累加计算来完成数据结构的构建。压缩后的行数据结构(接下来称为行偏移量)大小为 m+1。第一个值为 0,剩下的值是累加和的结果。这个数据结构非常有用,因为通过相邻读取可以提供每一行稀疏矩阵乘以密集向量(即稀疏点积)计算的起始和结束索引。

ELLPACK格式
当每行的非零元素数量差异较小时,ELLPACK格式是一种有效的稀疏矩阵-向量乘法(SpMV)数据结构。与CSR格式相比,该格式将存储顺序反转为列优先,并使用零填充来实现数据结构的统一。每行的条目数由所有行中最大的非零元素数量决定。任何非零元素数量少于最大数量的行将使用零填充值和“合理”的列索引进行填充。例如,可以使用该行中最后一个有效的列索引进行填充,以确保重新读取先前加载的索引和值对。
可以将此数据结构可视化为将数组中所有的值(和列索引)向左移动。

通过将ELLPACK数据结构按行分块,可以进一步优化该格式。这能够在实现数据统一的同时,最小化零填充的数量。我们将这种优化称为分块ELLPACK(Blocked ELLPACK)。
GPU内核实现
以下是基于CSR和ELLPACK格式的一些标准SpMV实现:
标量CSR内核
最简单的GPU加速SpMV实现之一是标量内核方法。标量内核为每个SpMV中的稀疏点积分配一个线程。每个线程以顺序的方式处理稀疏点积,从而不需要更高级的技术,如共享内存和/或warp级别的归约。以下代码片段展示了标量CSR内核的简单实现。
__global__ void scalar_csr_kernel(const int m,
const int *__restrict__ row_offsets,
const int *__restrict__ cols,
const double *__restrict__ vals,
const double *__restrict__ x,
double *__restrict__ y,
const double alpha,
const double beta)
{
const int row = threadIdx.x + blockDim.x * blockIdx.x;
if (row < m) {
// determine the start and ends of each row
int p = row_offsets[row];
int q = row_offsets[row+1];
// run the full sparse row * vector dot product operation
double sum = 0;
for (int i = p; i < q; i++) {
sum += vals[i] * x[cols[i]];
}
// write to memory
if (beta == 0) {
y[row] = alpha * sum;
} else {
y[row] = alpha * sum + beta * y[row];
}
}
}
void scalar_csr(int m,
int threads_per_block,
int * row_offsets,
int * cols,
double * vals,
double * x,
double * y,
double alpha,
double beta)
{
int num_blocks = (m + threads_per_block - 1) / threads_per_block;
dim3 grid(num_blocks, 1, 1);
dim3 block(threads_per_block, 1, 1);
scalar_csr_kernel<<<grid, block>>>(m, row_offsets, cols, vals, x, y, alpha, beta);
}正如上面所述,计算仅在行级并行化。设nthreads为每个块中的线程数,则完成计算所需的独立块数量通过上取整函数计算为:
在这个上下文中,nthreads是一个可以调整的参数,我们可以利用它来最大化此实现的性能。在内核定义中,然后我们:
- 基于线程和块的简单映射计算行,
- 确保我们不读取超出行偏移数组范围的任何数组边界,
- 通过连续读取行偏移数组确定列(以及向量)索引和矩阵值,
- 执行稀疏点积的标量计算,最后
- 将结果写入内存。
在最后一步,我们可以通过测试y向量是被覆盖还是更新来节省一些内存带宽。标量CSR实现对于最广泛的稀疏矩阵来说会表现出一般的性能。然而,在某些情况下,这个内核可能是有效的,即当每行非零元素的平均数较小时。实际上,当每行非零元素的平均数较高时,将需要多个请求来完成内存事务,并且内存合并会很少。相比之下,当每行非零元素的平均数非常低时,可以将高内存带宽与该内核的简单特性结合起来,从而实现良好的性能。
请参阅以下[示例]了解如何从矩阵市场文件输入运行标量CSR内核。
向量化的CSR内核
GPU加速的SpMV中最通用且高性能的实现之一是向量内核方法。与标量内核不同,向量内核使用一个warp中的多个线程来并行化每个稀疏点积的计算。这需要使用共享内存或warp shuffle操作来减少线程间的部分累加值。根据(每行非零元素的平均数)来选择每个稀疏行-向量乘积分配的warp线程数的启发式方法。我们通常发现,通过选择不大于
的最小的2的幂数可以获得最佳性能。
此时,有必要通过一个代码示例来研究实现的细节。这里我们关注仅使用warp shuffle操作完成稀疏点积的情况。需要注意的是,每个输出结果最多只能由wavefront大小(线程数)计算,在MI200架构上这个数值是64。当每行的平均非零元素数远大于wavefront大小时,这可能会限制性能。
template <int THREADS_PER_ROW>
__global__ void vector_csr_kernel(const int m,
const int *__restrict__ row_offsets,
const int *__restrict__ cols,
const double *__restrict__ vals,
const double *__restrict__ x,
double *__restrict__ y,
const double alpha,
const double beta)
{
const int row = threadIdx.y + blockDim.y * blockIdx.x;
if (row < m) {
// determine the start and ends of each row
int p = row_offsets[row];
int q = row_offsets[row+1];
// start the sparse row * vector dot product operation
double sum = 0;
for (int i = p + threadIdx.x; i < q; i += THREADS_PER_ROW) {
sum += vals[i] * x[cols[i]];
}
// finish the sparse row * vector dot product operation
#pragma unroll
for (int i = THREADS_PER_ROW >> 1; i > 0; i >>= 1)
sum += __shfl_down(sum, i, THREADS_PER_ROW);
// write to memory
if (!threadIdx.x) {
if (beta == 0) {
y[row] = alpha * sum;
} else {
y[row] = alpha * sum + beta * y[row];
}
}
}
}
void vector_csr(int m,
int threads_per_block,
int warpSize,
int * row_offsets,
int * cols,
double * vals,
double * x,
double * y,
double alpha,
double beta)
{
int nnz_per_row = nnz / m;
int threads_per_row = prevPowerOf2(nnz_per_row);
// limit the number of threads per row to be no larger than the wavefront (warp) size
threads_per_row = threads_per_row > warpSize ? warpSize : threads_per_row;
int rows_per_block = threads_per_block / threads_per_row;
int num_blocks = (m + rows_per_block - 1) / rows_per_block;
dim3 grid(num_blocks, 1, 1);
dim3 block(threads_per_row, rows_per_block, 1);
if (threads_per_row <= 2)
vector_csr_kernel<2><<<grid, block>>>(m, row_offsets, cols, vals, x, y, alpha, beta);
else if (threads_per_row <= 4)
vector_csr_kernel<4><<<grid, block>>>(m, row_offsets, cols, vals, x, y, alpha, beta);
...
else if (threads_per_row <= 32)
vector_csr_kernel<32><<<grid, block>>>(m, row_offsets, cols, vals, x, y, alpha, beta);
else
vector_csr_kernel<64><<<grid, block>>>(m, row_offsets, cols, vals, x, y, alpha, beta);
}相比标量实现,该实现有几个主要不同点。我们使用来构建二维的线程块。
- 线程块的x维表示分配给每行的线程数。这是通过函数prevPowerOf2计算得出的,它计算不大于输入变量的最小2的幂。
- y维表示每个线程块处理的行数。
- 线程块的总数由每个块处理的行数决定。
我们使用模板在编译时确定每行的线程数。这使得在循环展开的过程中可以进行优化。
内核开始时,与标量内核类似,但一个关键区别在于如何从块/网格启动启发式方法计算行索引。注意,我们使用线程索引和块大小的y分量来计算这个值。然后,稀疏点积分为两个步骤:
- 每个线程以模板参数的倍数遍历该行,计算稀疏点积的部分结果。
- 完成后,子warp使用shuffle down操作将值累加到每个wavefront中的0号线程。
这里我们注意到,在稀疏点积步骤的任一部分中都没有同步步骤。这是因为我们限制自己进行的累加操作至少与wavefront大小一样小。
请参考以下[示例],了解如何通过矩阵市场文件输入运行向量化的CSR内核。
ELLPACK 核心算法
ELLPACK 的稀疏矩阵向量乘法(SpMV)实现沿着行进行并行计算。由于数据已经重新排序为按列存储,ELLPACK 数据中的内存访问沿着连续的行是合并的。在下面展示的实现中,我们假设输入的 cols 和 vals 数组已经转换为 ELLPACK 格式。这个格式的一个关键参数是每行的最大非零元素数量,这也是作为参数传入的。
__global__ void ellpack_kernel(const int m,
const int max_nnz_per_row,
const int *__restrict__ cols,
const double *__restrict__ vals,
const double *__restrict__ x,
double *__restrict__ y,
const double alpha,
const double beta)
{
const int row = threadIdx.x + blockDim.x * blockIdx.x;
if (row < m) {
double sum = 0;
for (int i=row; i < max_nnz_per_row*m; i+=m)
{
sum += vals[i] * x[cols[i]];
}
// write to memory
if (beta == 0) {
y[row] = alpha * sum;
} else {
y[row] = alpha * sum + beta * y[row];
}
}
}
void ellpack(int m,
int threads_per_block,
int max_nnz_per_row,
int * cols,
double * vals,
double * x,
double * y,
double alpha,
double beta)
{
int num_blocks = (m + threads_per_block - 1) / threads_per_block;
dim3 grid(num_blocks, 1, 1);
dim3 block(threads_per_block, 1, 1);
ellpack_kernel<<<grid, block>>>(m, max_nnz_per_row, cols, vals, x, y, alpha, beta);
}线程块的工作分解与标量 CSR 格式相同。此外,稀疏点积操作也以标量方式进行。此核函数与标量 CSR 核心的关键区别在于矩阵以合并的方式访问。在数据结构中的填充使我们能够在稀疏点积实现中编写没有昂贵条件判断的代码。
请参见以下[示例],了解如何从矩阵市场文件输入运行 ELLPACK 核函数。该示例包括从 CSR 格式到 ELLPACK 的设备转换。
Blocked ELLPACK 核心
Blocked ELLPACK 数据结构设计的目的是为了最大限度地减少在 ELLPACK 结构中引入的额外内存读取。每行的最大条目数是在行集合内部计算的,该集合的大小是波前尺寸的倍数。然后,在每个块中计算局部的 ELLPACK 结构。每个块然后连接起来形成全局数据结构。这需要一个额外的小数组,类似于 CSR 行偏移量数组,用于指示每个块的开始和结束,按每行的最大列数计算。
下面代码片段展示了一个实现。首先需要注意的是,代码对波前大小的以2为底对数进行了模板处理,以避免用于计算全局波索引的整数除法。全局波索引用于立即从内核返回那些在计算中不起作用的尾波。
template<int LOG2WFSIZE>
__global__ void blocked_ellpack_kernel(const int m,
const int tw,
const int *__restrict__ max_nnz_per_row_per_warp,
const int *__restrict__ cols,
const double *__restrict__ vals,
const double *__restrict__ x,
double *__restrict__ y,
const double alpha,
const double beta)
{
const int row = threadIdx.x + blockDim.x * blockIdx.x;
const int warp = row>>LOG2WFSIZE;
if (warp>=tw) return;
const int lane = row&(warpSize-1);
int p = max_nnz_per_row_per_warp[warp];
int q = max_nnz_per_row_per_warp[warp+1];
p<<=LOG2WFSIZE;
q<<=LOG2WFSIZE;
if (row < m) {
// sparse dot product implementation
double sum = 0;
for (p+=lane; p<q; p+=warpSize)
{
sum += vals[p] * x[cols[p]];
}
// write to memory
if (beta == 0) {
y[row] = alpha * sum;
} else {
y[row] = alpha * sum + beta * y[row];
}
}
}请参考以下示例,了解如何从矩阵市场文件输入运行 Block ELLPACK 核心。本示例包括从 CSR 格式转换为设备上的 Block ELLPACK 格式的过程。
性能
为了衡量我们各种实现的性能,我们从多个来源选择矩阵。首先,我们从SuiteSparse矩阵集合中收集了一些经典的例子。下图中,这些矩阵用黑色标签表示。本文博客的部分作者与多个Exascale Computing Projects (ECP)团队密切合作。他们特别关注加速与这些代码相关的一些矩阵计算。其中包括来自ExaWind和Pele ECP项目的矩阵。所有数据已公开,托管于SuiteSparse集合。
我们从ExaWind项目中收集了几种类型的矩阵。ExaWind项目旨在建模整个风电场在大气边界层中的复杂流体运动。求解器由“背景”(AMR-Wind)和“叶片解析”求解器(Nalu-Wind)组成,分别尝试捕捉大尺度和小尺度行为。背景求解器有几个“类泊松”求解器,产生来自7点和27点模板的结构化矩阵。这些矩阵在图中用红色标签表示。叶片解析求解器使用非结构化网格来建模风力涡轮机叶片和塔周围的流体运动。我们使用了来自背景求解器压力泊松求解的各种大小网格的矩阵(参见SC21)。Nalu-Wind利用Hypre Boomer AMG(代数多重网格)算法求解压力-泊松方程。AMG求解器层次结构产生了稀疏矩阵,具有值得探索的有趣结构,这也是本文的一个部分。Nalu-Wind和Hypre的非结构化矩阵在图中用蓝色标签表示。
Pele ECP项目旨在建模复杂几何结构内的超高分辨率燃烧过程。Pele使用了自适应网格细化技术结合嵌入边界算法,实现了这一前所未有的计算规模。类似于AMR-Wind,该应用程序需要求解类泊松矩阵,以推进基础物理方程求解器。我们从这些类泊松问题中提取了几个大的和小的问题的矩阵。这些矩阵具有有趣的结构,值得进一步研究,在图中用绿色标签表示。
以下图中的性能结果是在单个MI250X GCD[1]上得到的。除了上面提供的代码示例外,我们还提供了一个示例,展示了如何从矩阵市场文件输入运行rocSPARSE CSR内核。
对于每个内核,我们使用每块256个线程。结果也生成了128和512线程每块的情况——通常比256稍微不太理想。在左图中,我们显示了按默认RocSparse性能缩放的每次SpMV执行的平均时间。在右图中,我们显示了设置成本,按三种格式的平均SpMV计时进行缩放,其中需要从CSR格式转换(ELLPACK和Block ELLPACK)或需要对CSR矩阵进行分析(RocSparseWithAnalysis)。
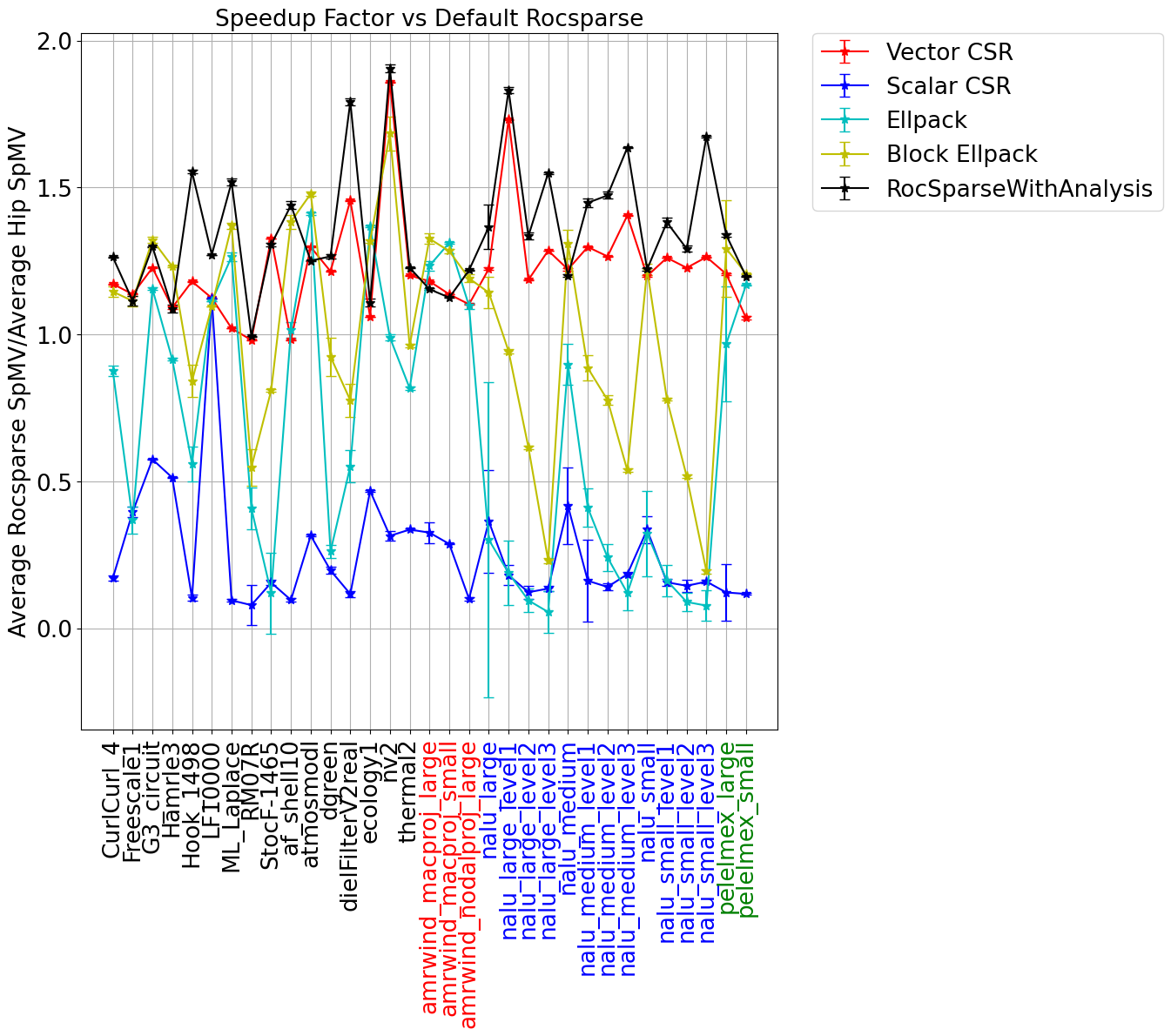
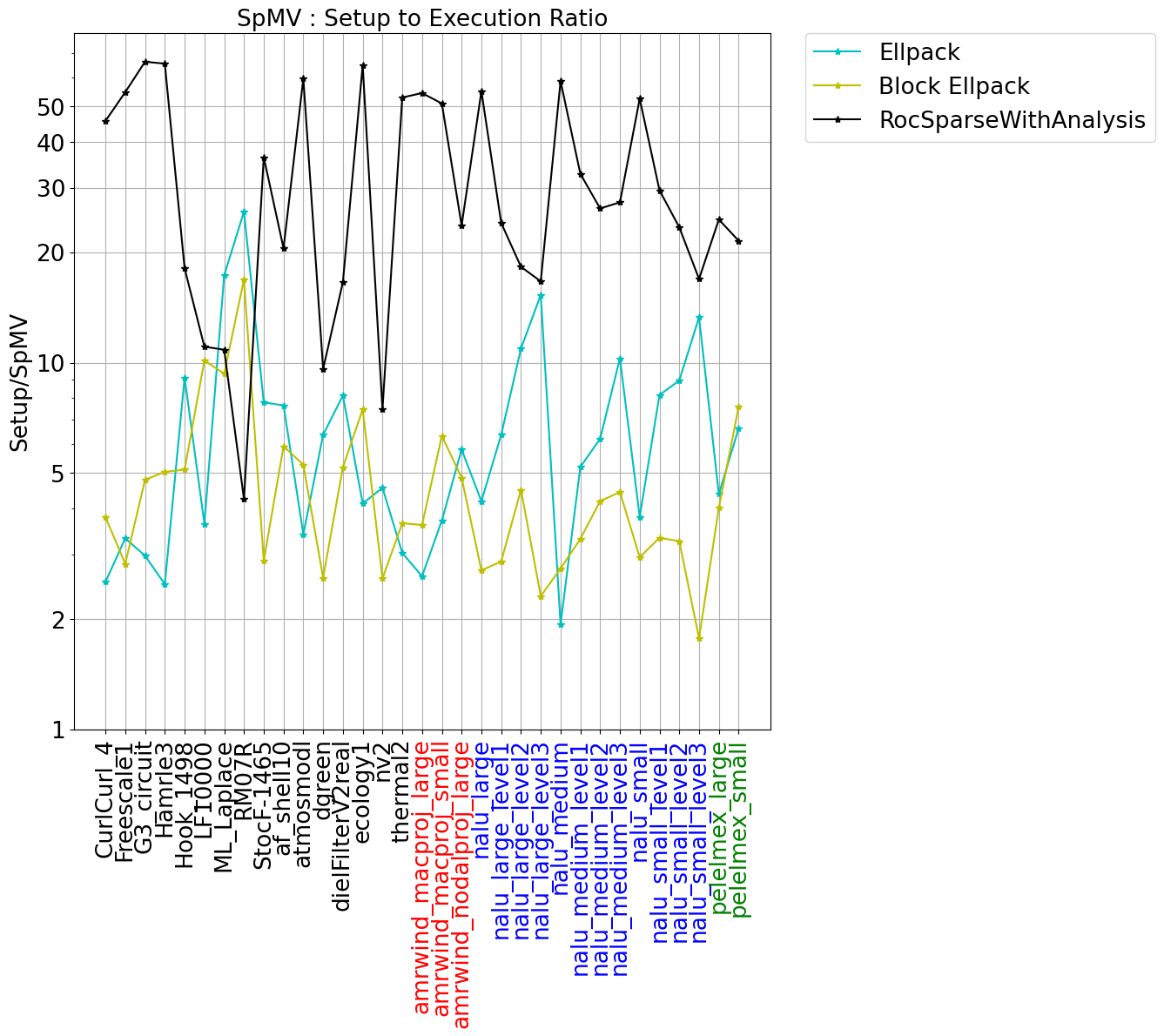
数据表明,这些矩阵集中的性能差异显著。使用RocSPARSE进行分析通常最快,但也伴随着最显著的设置成本。该算法对具有长尾的nnz(每行非零个数)分布的矩阵特别有效。Block ELLPACK实现通常也非常好,尤其是在每行nnz的方差较小时。与RocsparseWithAnalysis的成本相比,Block ELLPACK的设置成本往往小很多,收益也往往不错。
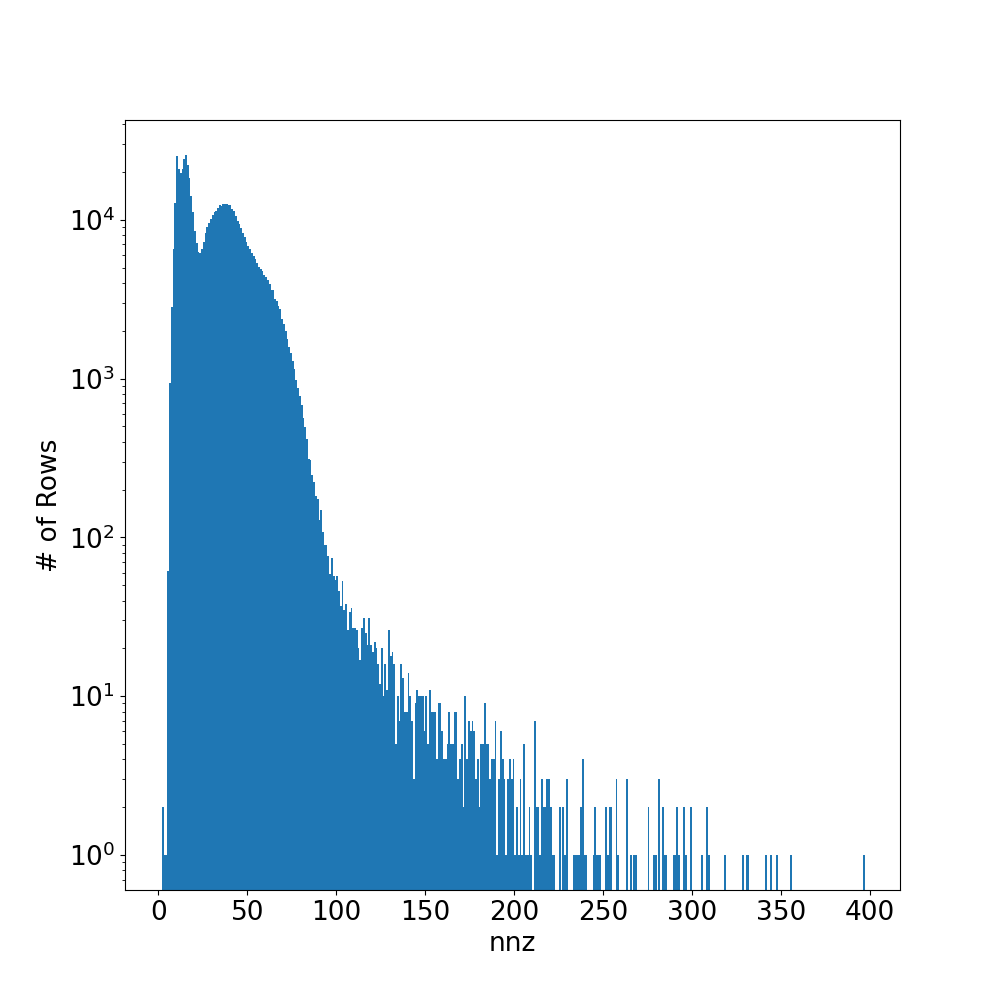
矩阵 _nalu_large_level1_、_nalu_large_level2_ 和 _nalu_large_level3_ 的每行非零元素数量 (nnz) 分布具有长尾特性。中等和小型版本的 nalu 矩阵也是如此。图中展示了 _nalu_large_level2_ 的分布和稀疏模式。由于稀疏模式的分散性和 nnz 每行分布的长尾特性,这些矩阵在 ELLPACK 存储格式中通常会导致大量的 0 填充。最终,ELLPACK 内核的简洁性无法克服这种 0 填充值导致的大量内存读取增加,这解释了为什么这些实现的性能会显著下降。相比之下,带分析的 RocSparse 内核可以很好地处理这些类型的矩阵。不那么令人意外的是,简单的矢量 CSR 内核在处理这些情况时表现得也相当不错。

结论
这就结束了使用 HIP 开发并优化一些基础 SpMV 核的第一部分。我们展示了几种不同存储格式在广泛矩阵上的性能表现。我们还展示了从 CSR 格式转换到 ELLPACK 和内部 Rocsparse 格式的性能代价。总体来说,Rocsparse 带分析的算法提供了最好的综合性能,然而它的设置成本比这里讨论的其他格式要高得多。
由于 SpMV 算法通常嵌入在更大的算法中,例如 AMG,选择最优格式时应考虑整个应用程序的性能概况。
作者感谢 Rajat Arora、Noel Chalmers、Justin Chang 和 Maria Ruiz Varela 的有益评论和反馈。
相关代码示例
如果有任何问题或意见,请在 GitHub 上联系我们 讨论区
[1]
测试在 ROCm 版本 5.4.22804 下进行。基准测试结果并非验证的性能数据,仅用于展示代码修改后的相对性能提升。实际性能结果取决于多种因素,包括系统配置和环境设置,结果的可重复性不作保证。
















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











