







1 基本步骤
k均值聚类算法是一种基于划分的聚类方法,即把数据样本划分成k个分区,每个分区代表一簇。这些簇的形成旨在优化优化一个客观的划分准则,如基于距离的相异性函数,使得在同一簇中,样本是“相似的”,不同簇的样本是“相异的”。
目标:使得类内距离尽可能小,类间距离尽可能大。常用的是类内距离度量准则,即求下式最小:
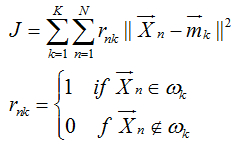

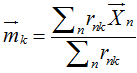
k均值的基本聚类过程如下:
(1)选取k个样本作为初始聚类中心;

(2)对每个待分类样本,计算它与每个聚类中心的距离,将其指派给距离最小的中心点所代表的那一类;
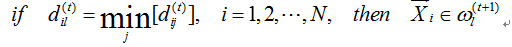
(3)重新计算每类的类心;

(4)若目标函数达到最优或达到最大迭代次数,则停止,否则跳到步骤(2)。
2 注意的问题:
(1)k的确定
a. 按先验知识确定k。
b. 让k从小到大逐步增加,每个k都用k-均值法分类,J随k的增加而单调减少,但速度在一定时候会减缓,曲率变化最大点对应最优类数。
(2)初始聚类中心的选取
a. 凭经验。
b. 将模式随机分成k类,计算每类中心,作为初始类心。
c. 求以每个特征点为球心,某一正数d为半径的球型区域中的特征点个数(即该特征点的密度),选取密度最大的特征点为第一个初始聚类中心,然后,在与该中心大于某个距离d的那些特征点中选取另一个具有最大密度的特征点作为第二个初始聚类中心,直到选取k个初始类心。
d. 用相距最远的k个特征点作为类心。
e. 当N较大时,先随机地从N个模式中取出一部分模式用层次聚类法聚成k类,以每类的重心作为初始类心。
(3)距离的度量
最常用的是欧式距离。其它度量方法还有绝对值距离、马氏距离、余弦相似度等
欧式距离:

(4)算法停止条件
一般是目标函数达到最优或者达到最大的迭代次数即终止。对于欧氏距离,一般使用误差平方和准则。即:

(5)收敛性
可以证明,k均值聚类算法是一定会收敛的。
3 优缺点分析
Kmeans算法试图找到使平方误差准则函数最小的簇,需要事先指定聚类数目。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。时间复杂度与样本数量线性相关,所以,对于处理大数据集合,该算法非常高效,且伸缩性较好。
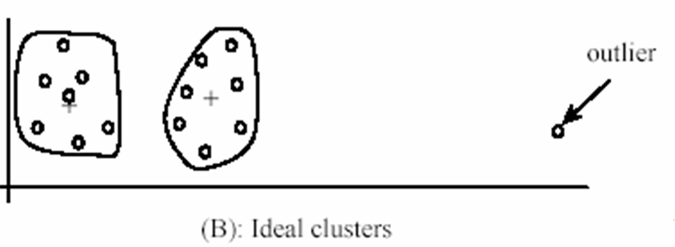
其对初始聚类中心敏感比较敏感,经常以局部最优结束,不合适的初始值不能得到满意的聚类结果,可以进行多次聚类,选取最好的一次作为最后的聚类结果;同时对“噪声”和孤立点敏感,并且该方法不适于发现非凸面形状的簇或大小差别很大的簇。
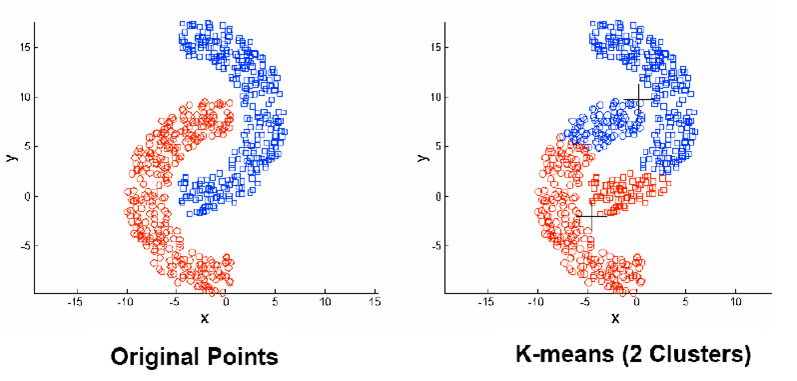

4 实现
利用了opencv来做数据显示
#include "highgui.h"
#include <math.h>
#include <time.h>
#include "cv.h"
void myKmeans(float* pSamples,int* pClusterResult,int clusterNum,
int sampleNum,int featureNum,
int AttempTimes=1,int* pInitCenter=NULL);
void main()
{
#define MAX_CLUSTERS 5
CvScalar color_tab[MAX_CLUSTERS];
IplImage* img = cvCreateImage( cvSize( 500, 500 ), IPL_DEPTH_8U, 3 );
CvRNG rng = cvRNG(cvGetTickCount());
CvPoint ipt;
color_tab[0] = CV_RGB(255,0,0);
color_tab[1] = CV_RGB(0,255,0);
color_tab[2] = CV_RGB(100,100,255);
color_tab[3] = CV_RGB(255,0,255);
color_tab[4] = CV_RGB(255,255,0);
int i,k;
int clusterNum = cvRandInt(&rng)%MAX_CLUSTERS + 2; //至少有两类
int sampleNum = cvRandInt(&rng)%1000 + 100; //至少100个点
int feaNum=2;
CvMat* sampleMat = cvCreateMat( sampleNum, 1, CV_32FC2 );
/* generate random sample from multigaussian distribution */
//产生高斯随机数
for( k = 0; k < clusterNum; k++ )
{
CvPoint center;
int topIndex=k*sampleNum/clusterNum;
int bottomIndex=(k == clusterNum - 1 ? sampleNum : (k+1)*sampleNum/clusterNum);
CvMat* localMat=cvCreateMatHeader(bottomIndex-topIndex,1,CV_32FC2);
center.x = cvRandInt(&rng)%img->width;
center.y = cvRandInt(&rng)%img->height;
cvGetRows( sampleMat, localMat, topIndex,bottomIndex, 1 );
/*此函数不会给localMat分配空间*/
cvRandArr( &rng, localMat, CV_RAND_NORMAL,
cvScalar(center.x,center.y,0,0),
cvScalar(img->width*0.1,img->height*0.1,0,0));
}
// shuffle samples 混乱数据
for( i = 0; i < sampleNum/2; i++ )
{
CvPoint2D32f* pt1 = (CvPoint2D32f*)sampleMat->data.fl + cvRandInt(&rng)%sampleNum;
CvPoint2D32f* pt2 = (CvPoint2D32f*)sampleMat->data.fl + cvRandInt(&rng)%sampleNum;
CvPoint2D32f temp;
CV_SWAP( *pt1, *pt2, temp );
}
float* pSamples=new float[sampleNum*feaNum];
int* pClusters=new int[sampleNum];
for (i=0;i<sampleNum;i++)
{
//feaNum=2
pSamples[i*feaNum]=(cvGet2D(sampleMat,i,0)).val[0];
pSamples[i*feaNum+1]=(cvGet2D(sampleMat,i,0)).val[1];
}
cvReleaseMat( &sampleMat );
cvZero( img );
for( i = 0; i < sampleNum; i++ )
{
//feaNum=2
ipt.x = (int)(pSamples[i*feaNum]);
ipt.y = (int)(pSamples[i*feaNum+1]);
cvCircle( img, ipt, 1, cvScalar(255,255,255), CV_FILLED, CV_AA, 0 );
}
cvSaveImage("origin.jpg",img);
myKmeans(pSamples,pClusters,clusterNum,sampleNum,feaNum,1,NULL);
cvZero( img );
for( i = 0; i < sampleNum; i++ )
{
//feaNum=2
int cluster_idx = pClusters[i];
ipt.x = (int)(pSamples[i*feaNum]);
ipt.y = (int)(pSamples[i*feaNum+1]);
cvCircle( img, ipt, 1, color_tab[cluster_idx], CV_FILLED, CV_AA, 0 );
}
delete[] pClusters;
pClusters=NULL;
delete[] pSamples;
pSamples=NULL;
cvNamedWindow( "clusters");
cvShowImage( "clusters", img );
cvWaitKey(0);
cvDestroyWindow( "clusters" );
cvSaveImage("clusters.jpg",img);
cvReleaseImage(&img);
}
//Kmeans聚类,得到的结果从0开始计数
void myKmeans(float* pSamples,int* pClusterResult,int clusterNum,int sampleNum,int featureNum,int AttempTimes,int* pInitCenter)
{
int i,j,k,t;
int IterationTimes; //当前迭代次数
double MinDistance; //与聚类中心的最小距离
int currentCategory; //当前点的类别
double VarSum; //平方误差和
double LastVarSum; //上一次的平方误差和
double minVarSum; //最小平方误差和
int clusterEmpty; //是否有空类
int bestCluster;
int MaxIterationTimes=100; //最大迭代次数
double Epslion=0.001; //聚类停止误差
float *pCenters=new float[clusterNum*featureNum]; //聚类中心
float *pBestCenters=new float[clusterNum*featureNum]; //聚类中心
int* pEveryTimesResult=new int[sampleNum*AttempTimes]; //每一次尝试的聚类结果
double* pSum=new double[clusterNum*featureNum]; //用于计算聚类中心
int* pNum=new int[clusterNum]; //每类的数目
memset(pClusterResult,0,sampleNum*sizeof(int));
//初始化聚类中心
if (NULL==pInitCenter)
{
srand((unsigned int)time(NULL));
int index_temp=rand()%sampleNum;
for (i=0;i<clusterNum;i++)
{
for (j=0;j<featureNum;j++)
{
pCenters[i*featureNum+j]=pSamples[index_temp*featureNum+j];
}
index_temp+=(sampleNum/clusterNum);
if (index_temp>=sampleNum)
{
index_temp%=sampleNum;
}
}
}
else
{
for (i=0;i<clusterNum;i++)
{
for (j=0;j<featureNum;j++)
{
pCenters[i*featureNum+j]=pSamples[pInitCenter[i]*featureNum+j];
}
}
}
//开始聚类
for (t=0;t<AttempTimes;t++)
{
//初始化聚类中心
if (0!=t)
{
srand((unsigned int)time(NULL));
int index_temp=rand()%sampleNum;
for (i=0;i<clusterNum;i++)
{
for (j=0;j<featureNum;j++)
{
pCenters[i*featureNum+j]=pSamples[index_temp*featureNum+j];
}
index_temp+=(sampleNum/clusterNum);
if (index_temp>=sampleNum)
{
index_temp%=sampleNum;
}
}
}
//聚类
IterationTimes=0;
VarSum=0;
LastVarSum=0;
clusterEmpty=0;
while(1)
{
bool hasEmpty=false;
IterationTimes++;
for (i=0;i<clusterNum;i++)
{
for (j=0;j<featureNum;j++)
{
pSum[i*featureNum+j]=0;
}
pNum[i]=0;
}
VarSum=0;
for (i=0;i<sampleNum;i++)
{
//计算当前点属于哪一类
for (k=0;k<clusterNum;k++)
{
double distance_temp=0;
for (j=0;j<featureNum;j++)
{
distance_temp+=(double)((double)(pCenters[k*featureNum+j]-pSamples[i*featureNum+j])*(pCenters[k*featureNum+j]-pSamples[i*featureNum+j]));
}
if (0==k || MinDistance>distance_temp)
{
MinDistance=distance_temp;
currentCategory=k;
}
}
pClusterResult[i]=currentCategory;
pEveryTimesResult[i*AttempTimes+t]=currentCategory;
//计算平方误差
VarSum+=sqrtl(MinDistance); //开方防止超出存储长度
//用于计算新的聚类中心
pNum[currentCategory]++;
for (j=0;j<featureNum;j++)
{
pSum[currentCategory*featureNum+j]+=pSamples[i*featureNum+j];
}
}
//重新计算聚类中心,注意可能会有空类
for (i=0;i<clusterNum;i++)
{
for(j=0;j<featureNum;j++)
{
if (pNum[i]!=0)
{
pCenters[i*featureNum+j]=pSum[i*featureNum+j]/(float)(pNum[i]);
}
else //直接使用原来的类心,是否会有形成死循环的可能,表示不清楚
{
hasEmpty=true;
}
}
}
//如果有空类,就至少还要循环两次
if (true==hasEmpty)
{
clusterEmpty=2;
}
else
{
clusterEmpty=clusterEmpty-1>=0 ? clusterEmpty-1 : 0;
}
if ((IterationTimes>=MaxIterationTimes
|| fabsl(VarSum-LastVarSum)<=Epslion)
&& (0==clusterEmpty))
{
break;
}
LastVarSum=VarSum;
}
if (0==t || minVarSum>VarSum)
{
minVarSum=VarSum;
bestCluster=t;
for (i=0;i<clusterNum;i++)
{
for(j=0;j<featureNum;j++)
{
pBestCenters[i*featureNum+j]=pCenters[i*featureNum+j];
}
}
}
}
delete[] pCenters;
pCenters=NULL;
delete[] pSum;
pSum=NULL;
delete[] pNum;
pNum=NULL;
delete[] pBestCenters;
pBestCenters=NULL;
if (bestCluster!=AttempTimes-1)
{
for (i=0;i<sampleNum;i++)
{
pClusterResult[i]=pEveryTimesResult[i*AttempTimes+bestCluster];
}
}
delete[] pEveryTimesResult;
pEveryTimesResult=NULL;
}
</span>
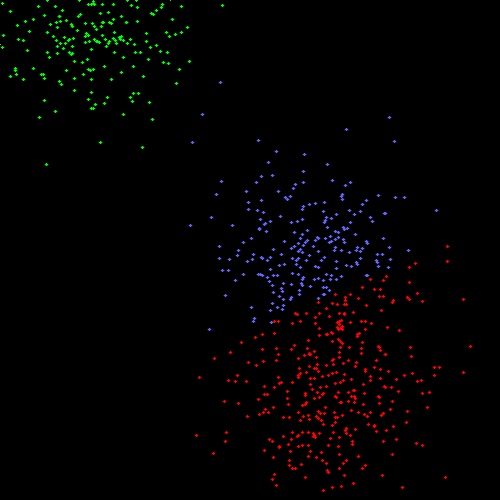
结果图:
参考资料:
http://blog.csdn.net/qll125596718/article/details/8243404
《数据挖掘 概念与技术》















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









