







近期阅读了几篇物体检测的文章,简单记录一下阅读所得。主要包括RCNN系列三篇和YOLO、SSD等几篇准确和速度都不错的论文。
1.RCNN
Rich feature hierarchies for accurate object detection and semantic segmentation
。
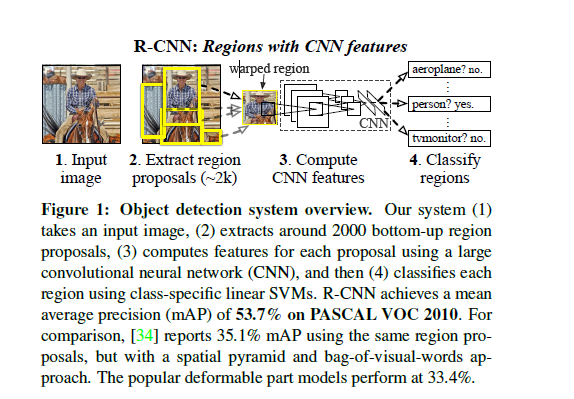
1.1摘要
传统最优的方法是在高层上下文组合底层的多维特征。本文提出一种简单的多尺度的检测方法。(1)使用高容量CNN,自下而上的定义候选区域,用于定位和分割物体;(2)如果带有label的数据太少,提前训练一个监督的模型,然后再对特定领域的数据进行fine-tuning。
传统的检测方法有两种:(1)将帧定位作为一种回归问题,但是被Szegedy证实效果不好;(2)滑动窗口:CNN使用这种方法超过20年,但适用于特定领域的检测,如人脸、行人等。为了增强分辨率,这些
1.2RCNN方法计算过程
(1)使用selective search方法,提取大约2000个候选区域;
(2)将候选区域Resize成227*227,使用CNN计算一组等长特征;
CNN包括5层卷积和2层全连接层。
IoU:Intersection Of Union。对于计算score之后的候选区域,采用非极大值抑制的方法,如果该区域与一个得分score更高的块的IoU的面积超过一个阈值,则将其丢弃。
该检测方法有两个优势:
(a)CNN权值在所有类别的图片中共享;
(b)CNN计算之后的特征只有4096维度,比其他方法的维度大大降低。
计算候选区域+CNN特征速度:GPU, 13S/image;CPU, 53S/image
(3)调用SVM分类
对于lable数量太少的问题,我们先基于ILSVRC大数据预训练一个模型,然后基于小数据量PASCAL进行fine-tuning,实验证明这种方法效果很好。
2.SPP-NET
论文发表日期:2015.4.23
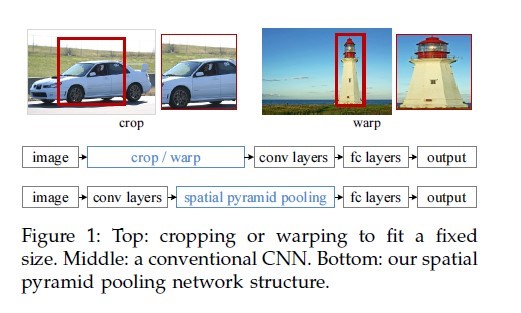
2.1摘要
引入一种空间金字塔模型,输入的图像尺寸可以不再固定大小。因为整个计算网络中,卷积层对于尺寸大小无要求,只有全连接层需要固定尺寸,所以在全连接fc层之前加入一个SPP层,将输入特征组合成固定尺寸。
2.2优势
(1)SPP可以对任意尺寸的输入图像产出一个固定尺寸的向量,还可以产出多种尺度的图片
(2)SPP使用多尺度的空间容器
(3)SPP可以聚合多种维度的特征
3.Fast RCNN
论文发表日期:2015.9.27
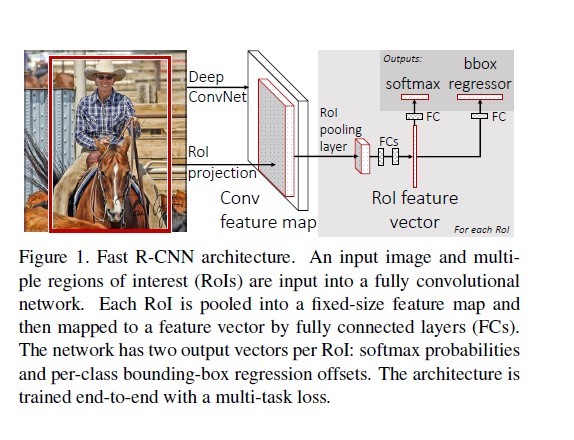
3.1摘要
Fast RCNN的优点为:
(1)检测准确率高;
(2)训练过程只有一个阶段;
(3)训练可以更新所有层参数;
(4)特征计算不需要硬盘存储。
3.2整体架构
(1)输入为一副图片和包含的一系列区域特征ROI(r,c,h,w)上左高宽
(2)使用conv计算全图的卷积特征
(3)根据ROI提取对应且定长的卷积特征
(4)fc分为两个分支,一个分支产出分类类型的概率(softmax),一个分支产出对应分类的左、上、宽、长四个维度坐标。
3.3实验过程
(1)最后一层被ROI层代替,其中H和W的在第一层全连接层设置,VGG16中设置为7*7;
(2)最终的输出修改为K+1类和每个检测出的区域的bounding-box
(3)输入包括两部分:图片和候选区域ROI
训练中,SGD采用分层次取样的方法,首先选取N个样本,然后从每个样本中选取R/N个ROI区域,同一样本中的ROI区域共享计算和内存,这种方法从理论上讲会造成训练过程不收敛,但是试验中效果还好。N=2,R=128
损失函数 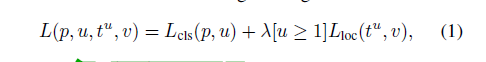
其中:
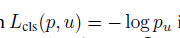

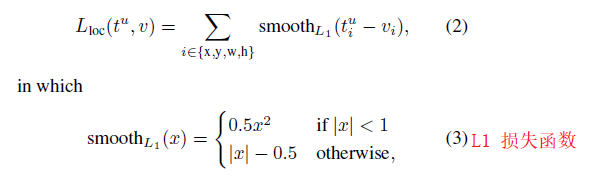
每个mini-batch包含128张图片,其中每张图片分为64个ROI区域。在前向计算的全连接层,使用SVD分解。
fine-tuning只对全连接层有效,在分类时使用softmax来替代RCNN中的SVM。
候选区域并非越多越好,随着候选区域的增加,预测的平均准确率会先有上升,然后缓慢的下降。
4.Faster RCNN
论文发表日期:2016.1.6
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
RPN: Region Proposal Network,全卷积网络,给出类别概率和物体bounding-box
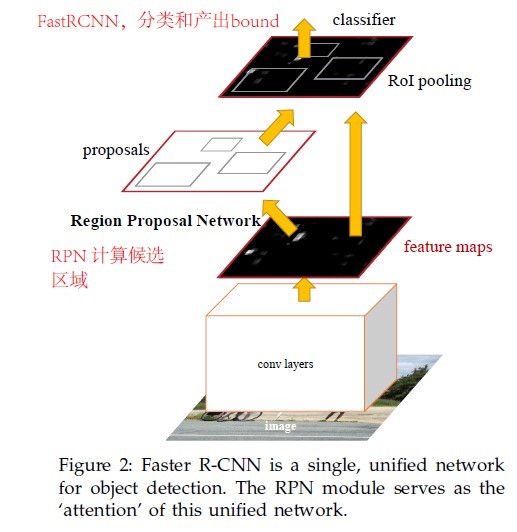
4.1摘要
提出RPN网络,采用全卷积网络,同时给出类别概率和物体的bounding-box。这种方法在
区域提取中耗时很少。GPU:5fps。
4.2架构
包括两部分:
(1)RPN在深度卷积网络中计算候选区域;
Region Proposal Network,输入任意尺寸的图片,输出候选区域类型及bound信息。
在卷积网络的最后一层的卷积特征上面,引入一个小的滑动网络,该滑动网络的输入是n*n大小的卷积特征,输出是一组低维特征(ZF网络256, VGG网络512维),后面接一个Relu层。
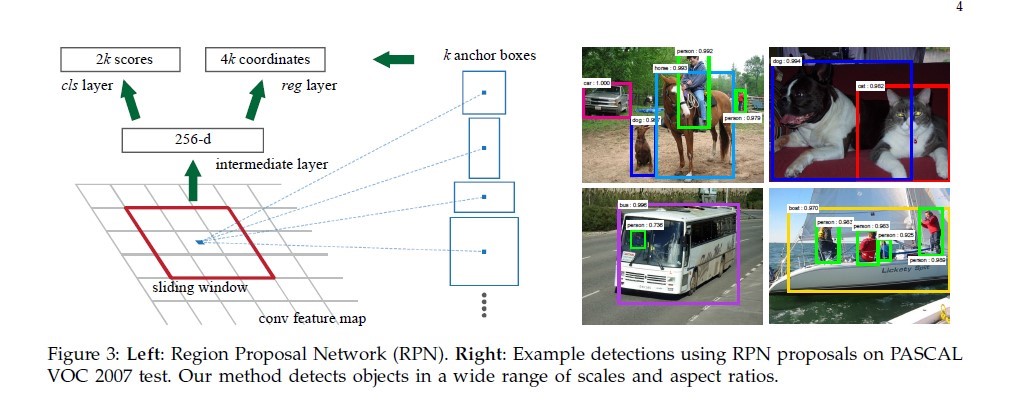
在滑动网络的每一步会产出候选区域的位置和类型,我们称候选位置为一个anchor。
训练过程,已有参数通过ImageNet训练进行Find Tune,没有的初始化为均值为0 的高斯(0.01),
(2)使用Fast-RCNN计算分类和bounding-box
4.3训练步骤
(1)训练RPN网络,使用ImageNet网络的参数初始化,做fine tune;
(2)训练Fast -RCNN
(3)训练的Fast-RCNN来初始化RPN网络,固定卷积参数,只fine tune RPN独有的层
(4)固定share的卷积层,fine tune Fast-RCNN
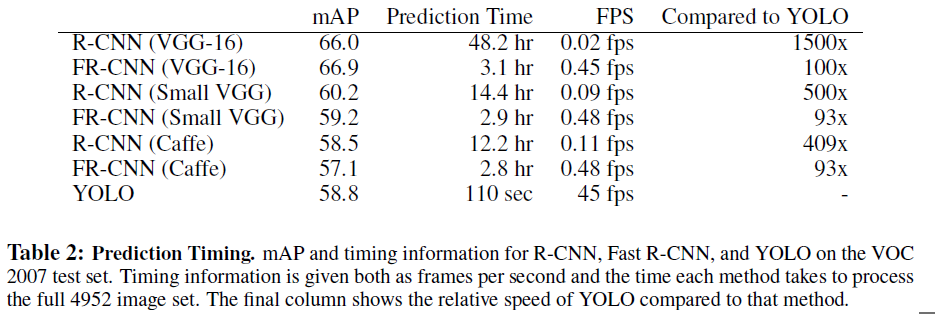
5.YOLO
,论文发表日期:2016.5.9
You Only Look Once: Unified, Real-Time Object Detection
项目主页:http://pjreddie.com/darknet/yolo/

5.1摘要
提出一种新的方法,将物体检测问题作为一种回归问题处理,从空间分离出物体边界和类别。整个过程为一个网络一气呵成,速度达到一秒45副图片。
输入:一副图片
输出:物体box和类别预测
5.2优劣
Yolo有三个优势:
(1)执行速度很快,TitanX GPU 45/S, 快速版本150/s
(2)预测面向全局,学习的是整副图片特征
(3)学习可归纳概括的特征表示
劣势:
定位准确差,尤其是定位小物体
空间依赖太强,目前一个网格智能预测2个物体和1中类型,且这种约束不能检测一个群体内的小物体,如一群飞行中的鸟
5.3架构
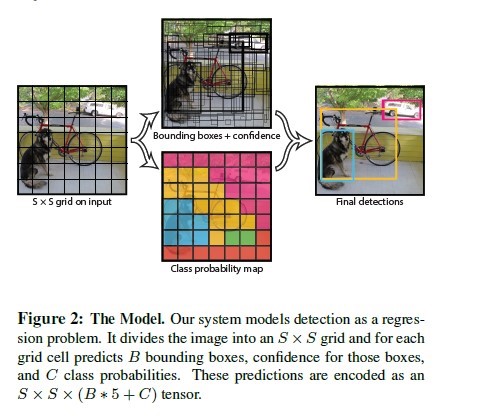
将输入图片分割成S*S的网格,如果一个物体的中心落在网格内,则这个网格负责这个物体的区域box和类别预测,每个网格可以预测B个物体和C个类别。
每个预测的box包括五个维度(x,y,w,h)和confidence,x和y表示预测物体的中心,w和h表示宽度和高度,confidence表示预测和实际标注的IOU,C表示预测的类别,当前总共20类,所以大小为20维度。
所以最终产出的特征向量为S*S*(B*5+C),其中
S为分割的网格数
B为预测的物体区域box数量
C为预测的类别数,总共20。
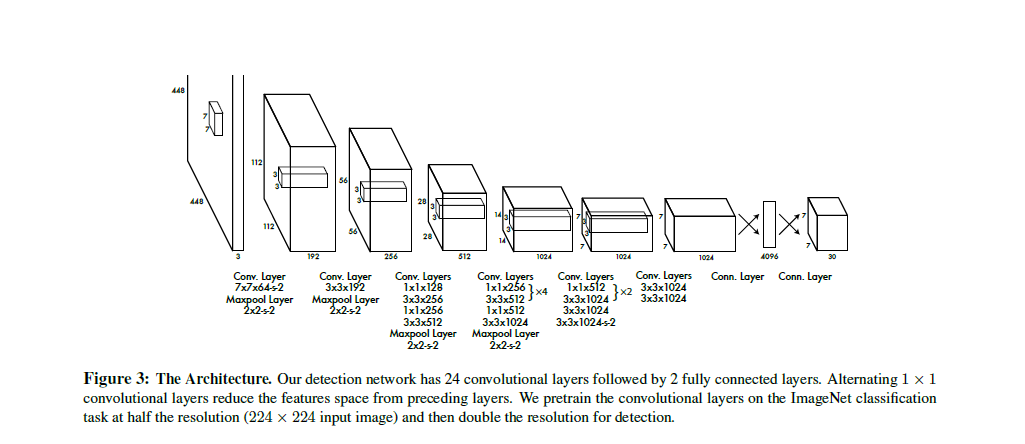
5.4训练
网络结构中包含24个卷积层和2个全连接层, Fast YOLO使用9个卷积层,最终产出为7*7*30维度
训练中首先进行预训练。
使用前面的20层卷积+平均下采样层+全连接层在ImageNet上预训练,图片大小为448*448,最后一层输出的box大小用图片的长宽做归一化,最长产出的值在0-1之间。
最后一层使用逻辑激活函数,其他层使用leakly Relu
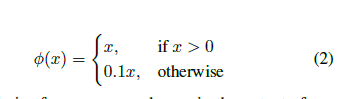
使用的损失函数为

网络输出使用平方和误差,并引入尺度因子λ 对类概率和bbox的误差进行加权,同时为了反映出偏离在大的bbox中的影响比较小,文章使用bbox宽高的平方根
为了避免过拟合,引入drou p层和增加泛数据,droup层添加在第一层全连接后面,rate为0.5,引入的泛数据为做缩放和翻转成源图像的1/5,引入过渡曝光和色彩饱和度变化的数据。
5.5实验
准确率较高
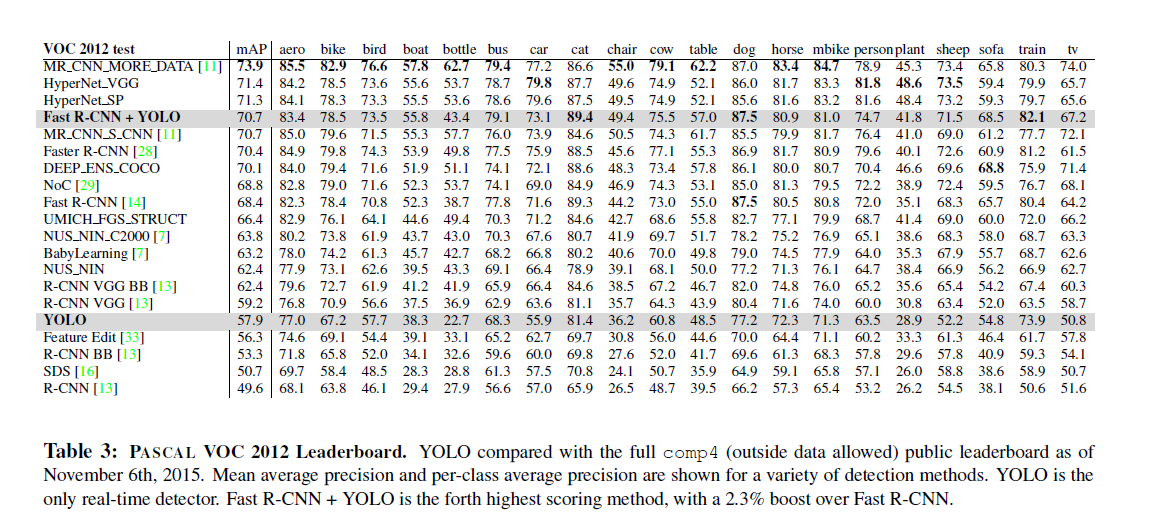
速度很快
6.SSD
论文发表日期:2016.5
SSD: Single Shot MultiBox Detector
code地址:https://github.com/weiliu89/caffe/tree/ssd
6.1摘要
提出一种用于检测物体的单一深度网络,将输出的box空间离散化为一系列不同纵横比和尺度的默认box中。
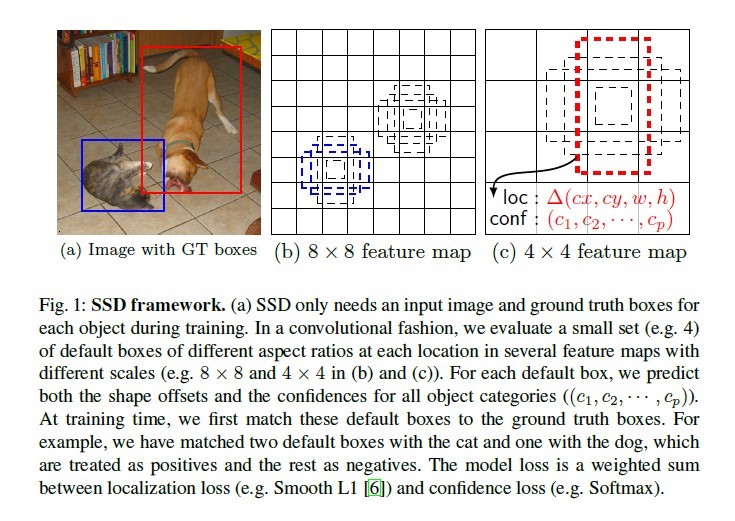
6.2架构
SSD首先基于前馈深度网络产出固定长度的bounding box和概率,然后通过一层非最大化抑制层产出最终的检测结果。网络分为两部分:第一部分是用于图像分类的基础结构,叫做基础网络;第二部分为附加网络,产出检测结果,包括三个核心部分:
(1)多尺度特征图,添加卷积特征层,这些层逐渐减小尺度,同时每个尺度都进行预测
(2)卷积预测
(2)默认的boxs和纵横比
网络结构图:
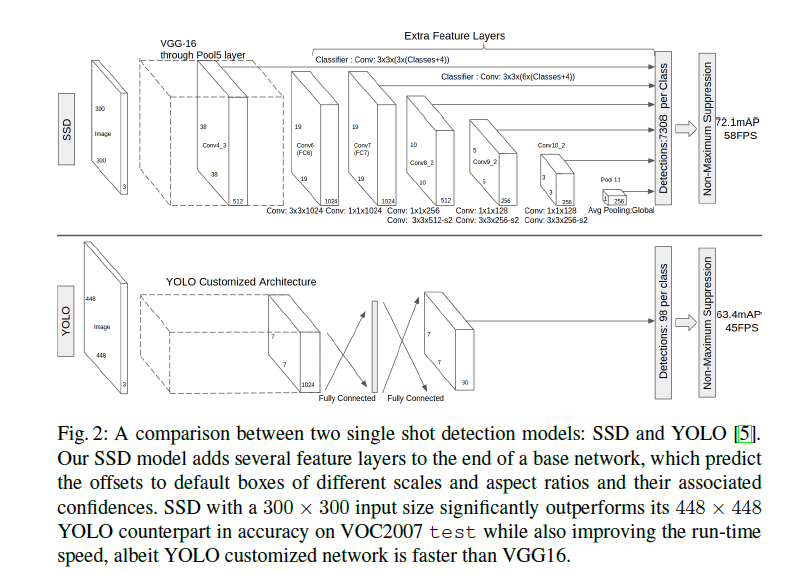
对于默认box,选择不同翻转和缩放尺度,不同尺度之间,共享权值。
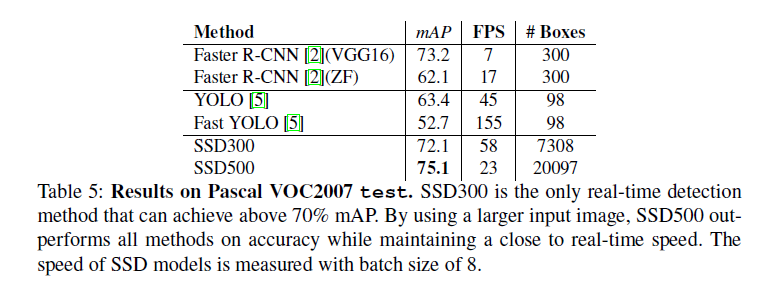
6.3实验
小的尺寸图片对于检测小物体效果不佳,图片尺寸500之后,SSD效果优Yolo.

SSD的执行速度也很快。















 2016
2016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









