







 本文介绍了物体检测领域的经典算法,包括RCNN、SPP-Net、Fast R-CNN、Faster R-CNN以及YOLO。RCNN提出特征提取和SVM分类,但速度慢;SPP-Net解决了图像变形问题;Fast R-CNN引入ROI Pooling,速度提升,无需SVM;Faster R-CNN通过RPN进一步加速;YOLO采用回归方法,结合选择与识别,实现快速检测。
本文介绍了物体检测领域的经典算法,包括RCNN、SPP-Net、Fast R-CNN、Faster R-CNN以及YOLO。RCNN提出特征提取和SVM分类,但速度慢;SPP-Net解决了图像变形问题;Fast R-CNN引入ROI Pooling,速度提升,无需SVM;Faster R-CNN通过RPN进一步加速;YOLO采用回归方法,结合选择与识别,实现快速检测。
2014年CVPR上的经典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》,这篇文章的算法思想又被称之为:R-CNN(Regions with Convolutional Neural Network Features),是物体检测领域曾经获得state-of-art精度的经典文献。
这篇paper的思想,改变了物体检测的总思路,现在好多文献关于深度学习的物体检测的算法,基本上都是继承了这个思想,比如:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,所以学习经典算法,有助于我们以后搞物体检测的其它paper。
在R-CNN 之后,又出现了SPP,fast-RCNN,faster-RCNN,把原来RCNN 13s 处理一张图片的速度提高到了大概0.2s 处理一张图片。但是RCNN 是这各系列的方法的基础。不过据说好像这些算法都不能实现real-time,所有后来又出现了YOLO,SSD。RCNN
2.1论文算法思路:
1) 输入一张图片
2) 定位出2000个proposal(把可能的物体框出来)
3) 用CNN 提取特征
4) 用SVM进行分类
因为这2000个proposal 框出的图片大小不同,但是利用caffe最后处理的时候要求所有照片的大小一致,否则就会报错。所以作者把框出的proposal resize 成227*227,然后对于每一个proposal,都进行一次特征提取。最后通过全连接层得到一个4096*1 维 的向量。这样做的优点是精度比较高,缺点是速度非常慢。如果是使用alexnet 跑voc12 的话精度大概在58.5%,如果用VGG的话精度大概在66%左右,但是VGG计算量比alexnet 要大很多。
通过CNN得到特征之后,作者采用了SVM 进行分类。这里是一个2分类处理。作者把小于-1 的负样本先刷掉,然后再通过非极大值抑制的方法处理proposal 相交的情况,所有找到能够代表最终检测结果的proposal,对它们进行回归,最后找到图像的分类。
但是这个方法有需要在CNN 和SVM之间进行切换。这样不但不方便,而且速度还很慢。更重要的是,因为要在CNN和SVM之间来回切换,这样会导致无法确定最优的模型。
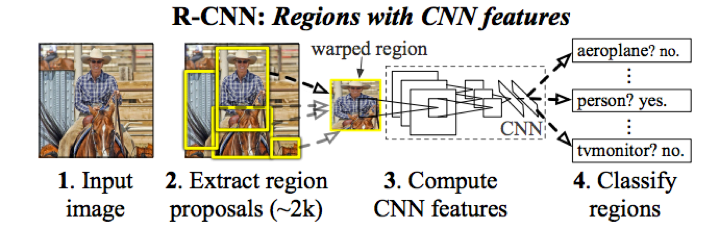
RCNN存在非常多的缺陷。比如它的速度非常的慢,即使在GPU加速下也处理一张图片也需要13s,而且还要使用到SVM 分类器,所以还要在CNN网络和SVM分类器之间进行切换。另外由于它会对proposal进行resize,把所有的图像都变成227*227 的大小,这样会导致某些图像变形失真。
- SPP-NET
针对这些问题,香港中文大学的大牛何凯明教授提出了SPP-net。
它主要是针对输入图像会变形失真进行处理。它代替了传统CNN的pool5层,使的它的pooling bins 的大小可变。这样的好处是是的图片不会因为resize 而变形。它把一张图片分成不同大小的super pixel,然后用它们组成大小不同的proposal,这样就提高了生成proposal 的速度。但是它还是存在缺陷。
- FAST-RCNN
和RCNN一样,它还是采用了多阶段的训练过程,在CNN网络和SVM分类器之间切换,速度还是比较慢。
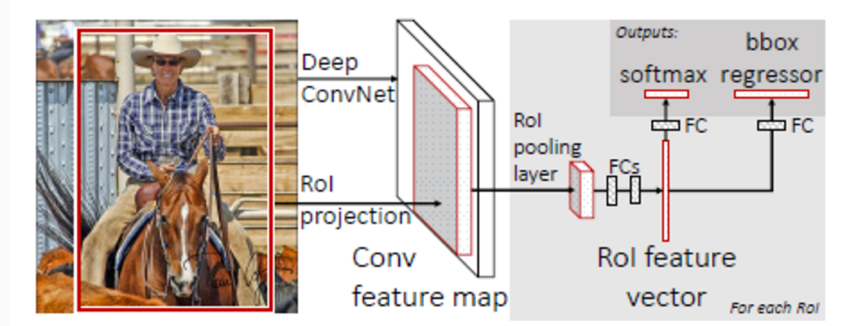
它的改进如下:
1) 输入从单输入变为双输入
2) 引入ROI pooling层(这个含有一层SPP)
3) 在全连接之后不再通过SVM分类,而是使用了softmax 和bbox regressor
通过这样的处理:
1) 它的速度提高了很多(训练速度是RCNN快了9倍,测试速度快了200多倍)
2) 而且训练中所有的层都可以得到更新
3) 不再需要SVM分类器来分类
- FASTER-RCNN
最后比FAST RCNN 的是Faster-RCNN,后者提出的改进是对于proposal 的处理。Fast RCNN 需要对数据先做一个预处理(selective search),而SS比较耗时,但是faster RCNN 则是把这个放到了网络中(RPN),这样使得整个框架都可以在一个网络中运行。从proposal 的数量上看,SS一般会生成大概2000个proposal,但是RPN大概只有几百个,所以faster-RCNN 会更快。
6.YOLO (这个还不是很理解,还请大神指正)
不过好像因为RCNN 框架目前的瓶颈在于:把dectection 问题转成图片局部区域的分类问题之后,不能充分利用图片局部object 在整个图片的信息,所以RBG 大神又提出了YOLO(you only look once),使用regression的方法,把物体框的选择与识别进行结合,一步输出。















 4346
4346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









