







为百万兆级加速架构做高性能 Linpack 优化
摘要
我们详细叙述了在 rocHPL 中做的性能优化,rocHPL 是 AMD 对 HPL 基准的开源实现,主要是针对节点进行优化的架构,是为百万兆级系统而设计的,比如:Frontier suppercomputer。
这个实现充分利用了节点上的使用高吞吐量的 GPU 加速器的高度优化的线性代数库,同时也使用了全部的CPU槽,执行延时敏感的分解阶段。
我们详述了难能可贵的性能挺高,例如一个多线程的方法在CPU 上计算 panel 的分解阶段,再例如,多个阶段之间分享节点上的 CPU 核的时间,再例如有几个优化用来隐藏 MPI 通信的时间。
我们展示了这个 HPL 基准的实现的性能结果,既在橡树岭国家实验室的Frontier 抢先体验版集群的单节点上进行了测试,也扩展到多节点上进行了测试。
1,简介
在2022年6月,坐落在 橡树岭国家实验室的 Frontier 超级计算机,首次亮相在超级计算机 Top500 名单榜,并且以HPL 基准 1.1EFLOPS的成绩位居榜首。 分数是上一届榜首的两倍多,Frontier 是第一个在 HPL 基准分数上超过 1 EFLOPS 的超级计算机,这使得它成为第一个 百万兆计算机。不久之后,AMD就将 rocHPL 开源了,大家都可以自由获得。
rocHPL 的一个变体,优化了通信性能,由 HPE 提供,在 Frontier 上面获得了超过 1EFLOPS 的分数。
在这篇论文中,我们详述这些性能优化的大部分,来帮助达到这个分数,我们希望这些优化能够提供有用的信息来帮助 用户 在异构系统上优化 HPL。
HPL是众多基准测试中的一个,用来衡量计算机系统某些方面的性能。其他通用的基准包括HPCG基准,它侧重于系统的主存储器带宽和系统级的 allreduce 的性能;还包括HPL-MxP基准,它侧重于系统在混合精度和低精度数学计算的吞吐率。
与这些基准一起,HPL 侧重于一个计算机系统的如下几个方面:64-bit 浮点数的计算速度,网络带宽,网络延迟。这使得 HPL 成为对新的计算系统的可靠性和整体性能的一个难以置信的有用的压力测试基准。
Frontier 在 HPL 基准上获得的高的 FLOP 速度,几乎完全是得益于它基于 GPU 加速的节点架构和网络的速度。
在高性能计算中使用加速器,是越来越流行的趋势。实际上,在2022年6月的超级计算机 TOP500 的名单中,前十名中,有7个是使用基于 GPU 加速的节点架构。以 Frontier 为例,每个节点由一个64 核的 AMD EPYC CPU,和4个 AMD Instict MI250X GPU 加速器。EPYC CPU 和 MI250X GPU 加速器都充分利用了 AMD 先进的 MCMs 打包技术。每一路 CPU 由八个8核心的 CCD 以及 IO-die组成,同时,每个 MI250 GPU 由两个GCDs组成。两个 GCDs之间是互联的,同时也连接到 CPU 槽, 这都是通过 AMD Infinity Fabric 实现的。
基于这样的节点架构,MI250X 加速器在每个 Frontier 节点中贡献了 98%以上的峰值 FLOPS 算力。
在 HPL 基准中执行的计算是求解一个随机的 NxN的线性方程组,使用的是 带选主元的分块的高斯消去法。其中系数矩阵 是 NxN,我们称之为矩阵 A,分布于 PxQ 的 MPI 进程网格中,基于 2维循环分块分布策略实现加载均衡。为了让 HPL 能够充分利用 GPU 加速器的高 FLOPS 算力,需要仔细考量算法实现的4个阶段,每个阶段都有不同的计算特性。这四个阶段如下:
1,FACT
列块分解,A矩阵的前导 NB 列块做 LU 分解。这个过程涉及执行分解的 P 个进程之间的 NB 次小规模集合通信,这是为了找到枢轴行。
2,LBCAST, 列块广播
将当前NB × NB对角块下方的尾随矩阵广播到计算网格中的所有其他进程。
3,RS,行交换
将FACT阶段确定的NB个枢轴应用于A矩阵的剩余列。
4,UPDATE
对A的尾随子矩阵应用秩为NB的更新。
这个阶段包括两个计算密集的操作:
a. 三角逆运算(也称为DTRSM)
b. 矩阵-矩阵乘法例程(也称为DGEMM)
典型的, HPL 基准运行时大多数时间花在了第四个阶段的尾随矩阵的更新中执行的 DGEMM 例程。这些历程经常都是在不同硬件上高度优化的,这样可以使得 HPL 的分数达到硬件峰值浮点算力很高的比例。在过去的十年来,加速器变得越来越普遍,有很多著作专门研究如何在HPL中利用加速器。一个自然的方法是在 HPL 中利用加速器提高大规模 DGEMM 计算,这样会把矩阵保持存放在 CPU 内存中,然后分流 DGEMM 操作到加速器中,通过切分矩阵成为小片,并且一小片一小片地处理,之间夹杂着数据的传输。Endo 和 Matsuoka 首先研究了利用 SIMD 加速器在 HPL 中提高DGEMM 性能,这项研究是基于一个异构的集群系统,其中只有一部分节点中包含加速器。
分流 DGEMM 的工作到加速器中的方法,Kistler 等也在 Road-runner 超级计算机得到了应用,这个系统中使用的是 PowerXcell 8i 加速器。Fatica 描述了在 CUDA 的 GPGPU 系统中使用该方法,他们描述了一个流水线策略来搬移输入输出矩阵进出GPU,来加速DGEMM 和 DTRSM 并且将数据移动隐藏在GPGPU的计算时间中。将这个流水线策略扩展到整个集群上的示例,是有 Wang 和 Rohr 等人描述的。其他作者为其他编程模型设计了类似的方法,例如 OpenCL 和其他加速器,例如 Intel Xeon Phi,甚至有的集群中混合使用不同类型的加速器。
在最近的研究中,一些作者注意到加速器的计算速率提升已经超过了主机-加速器之间链路带宽的改进。事实上,一些现代GPU加速器,包括MI250X GPU,还包含了专门的硬件单元,进一步加速了矩阵-矩阵乘法的计算速率。这使得Fatica描述的用于加速DGEMM和HPL中其他例程的流水线策略变得不切实际。为了隐藏主机和加速器之间的数据移动,每个内核中完成的计算量必须大幅增加,这通常会导致HPL中出现不合理的大块参数,从而在其他阶段造成瓶颈。
为了缓解这个问题,Tan等人和Kim等人提出了在现代GPU加速器上实现HPL的方法,其中整个问题都存储在GPU的内存中,而不是主机的DDR内存中,这个想法最初出现在Kistler等人的研究中。这种方法的好处是消除了需要为大型计算例程将数据移动到/从加速器的需求。
随后,几个大型MPI通信阶段也可以利用支持GPU的MPI例程,直接在不同GPU的HBM(高带宽内存)之间移动数据,并在可用时利用节点内GPU之间的快速硬件链接。
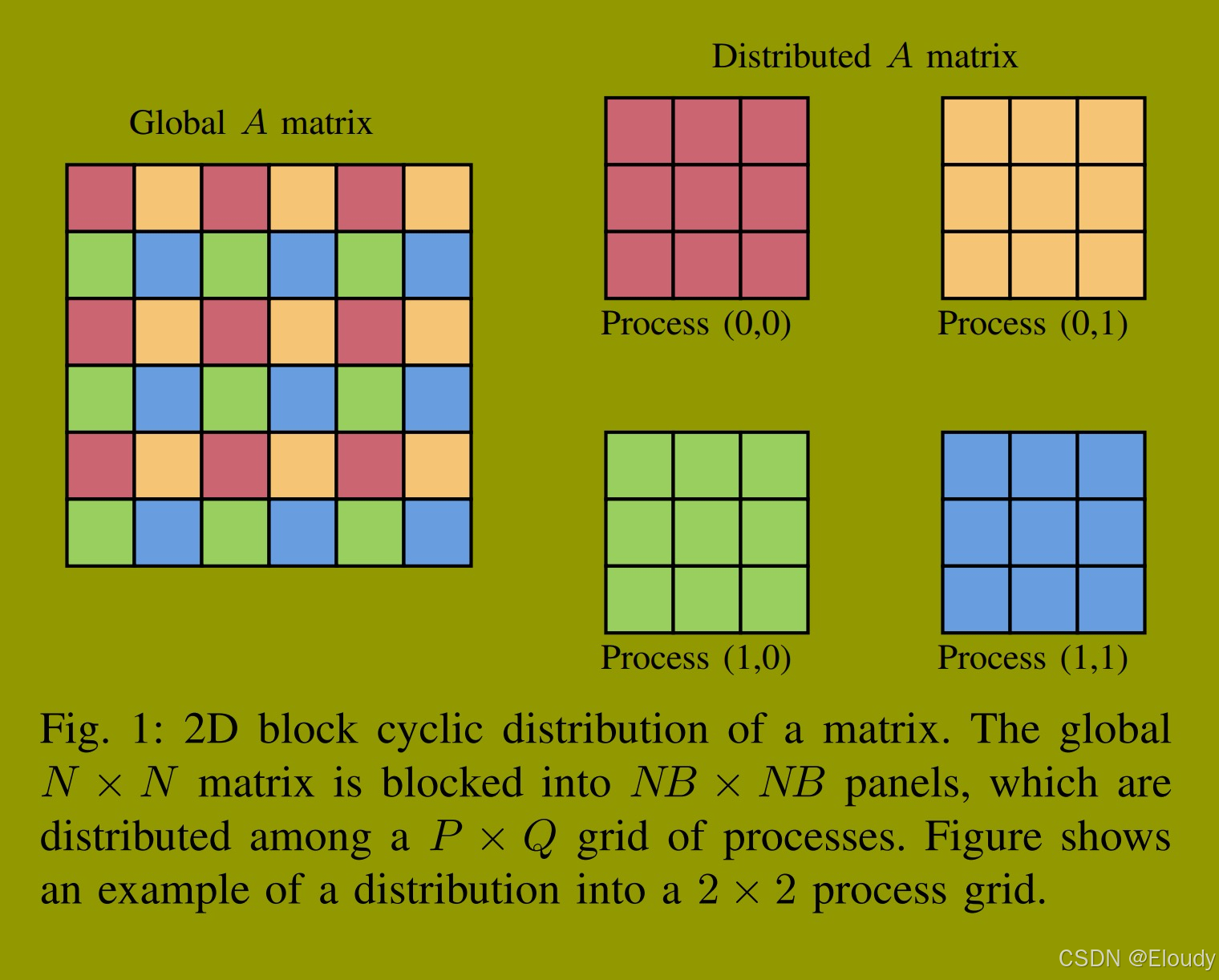
图1,
矩阵的2D块循环分布,全局 NxN 的矩阵切分成为 NB x NB 的列块,它们分布在一个 P x Q 的进程网格。
图中给出一个 2x2 进程网格的分布示例。
然而,这种实现方式也带来了一些复杂性。面板分解仍然是HPL中一个复杂的、对通信和延迟敏感的阶段,不太适合在加速器上进行细粒度并行。此外,MPI通信仍然需要由主机进程协调,将这些通信与加速器上的有用工作重叠可能具有挑战性。
Tan等人和Kim等人都选择利用主机CPU执行面板分解,在每次迭代中只在GPU和CPU之间传输所需的数据。这种减少的数据移动允许FACT和LBCAST阶段轻松地与GPU上的尾随更新计算重叠。执行行交换阶段所需的通信会导致GPU空闲时间,两项研究都通过将行交换和尾随更新分割成几个较小的部分,并通过流水线处理来隐藏较小尾随更新的通信来解决这个问题。Tan等人甚至实现了更进一步的流水线处理,使用多个CPU线程在面板分解进行的同时推进面板广播阶段。这种方法可能会导致网络接口的一些拥塞,Kim等人没有使用这种方法,而是使用NVIDIA的NCCL通信库进行GPU直接通信,该库使用GPU内核进行数据移动,使得与其他通信重叠变得不切实际。
在本文中,我们详细介绍了我们为HPL实现的一些优化,以提高在像Frontier这样的GPU加速节点架构上的性能。特别是,我们详细描述了一种多线程策略,用于在本质上串行的面板分解阶段提取数据并行性,重叠CPU和GPU计算,并通过分割尾随更新公式来隐藏GPU-GPU通信时间。然后,我们展示了这种HPL基准测试实现在ORNL的Crusher集群上的一些性能结果,显示了我们的优化在隐藏MPI通信时间方面的有效性,并展示了良好的多节点扩展性能,最后给出了一些结论性的评论。
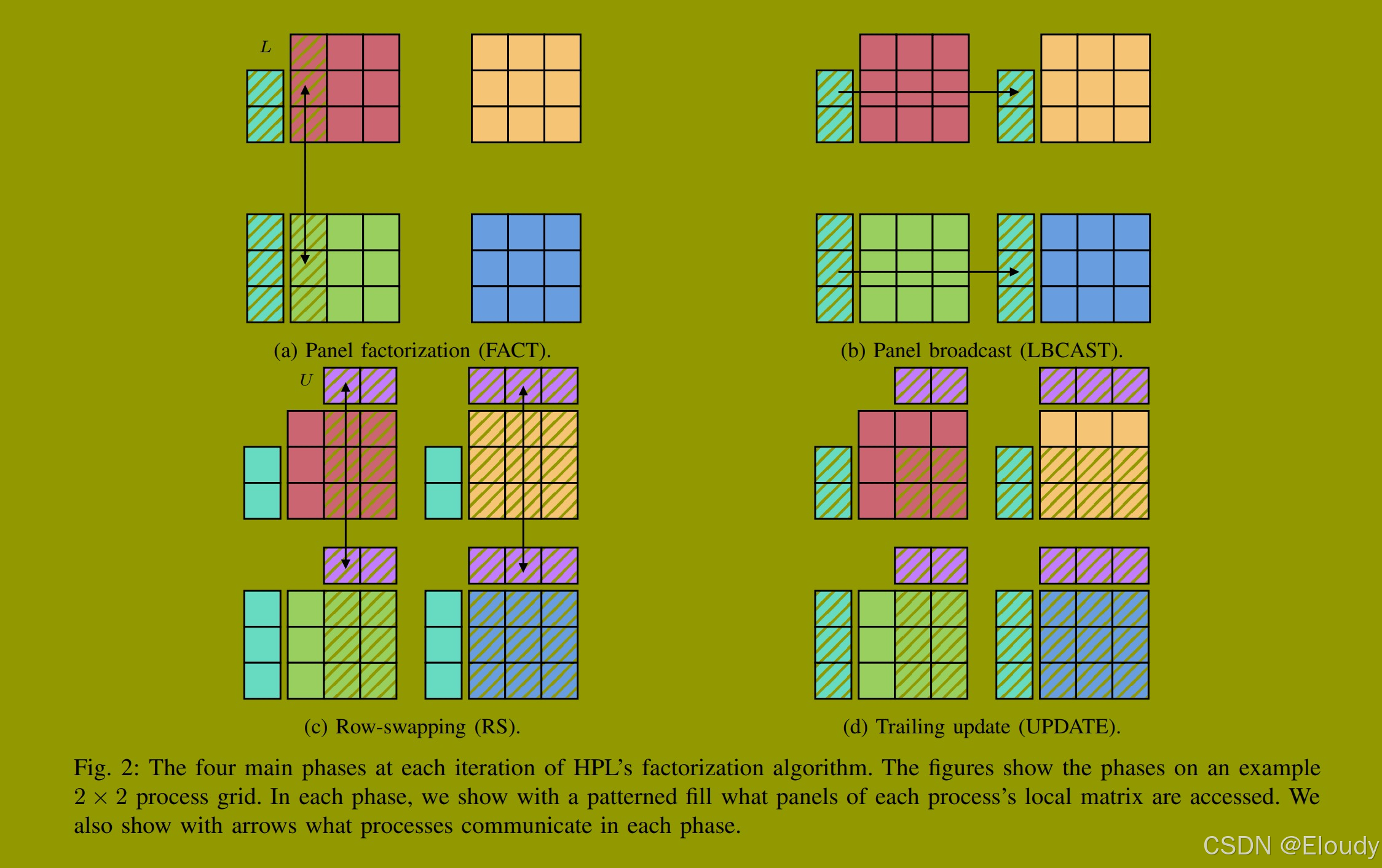
图2,HPL 分解算法在一次迭代中的4个主要阶段。这些图展示了在一个 2x2 的进程网格中的这些阶段。在每个阶段,我们展示了填充的模式,进程本地矩阵的哪些列块会被访问。我们也用箭头展示了什么样的进程会进行通信。
2,HPL 概览
HPL基准测试首先在P × Q进程的二维网格上生成一个分布式的 N × N 双精度矩阵A。为了负载平衡,全局矩阵A被分成NB × NB大小的面板,这些面板以2D块循环方式分布到进程网格中。图1图形化地描述了2 × 2进程网格的这种分布示例。还生成了一个长度为N的右侧向量b,并将其附加到A上,形成一个N × (N + 1)的增广系统。
线性系统通过带部分主元的分块高斯消元算法求解。通过将A视为增广系统,线性系统Ax = b本质上被转换为上三角系统Ux = bˆ = L^(-1)P^(-1)b,其中A = PLU是A的LU分解(带行主元)。经过这种转换,解向量x可以通过应用U^(-1)轻松求得。分块算法沿A的对角线迭代进行。每次迭代包括四个主要阶段,这些阶段本身包含不同级别的计算和进程间通信。
首先,在每次迭代中,对角线当前位置的NB列块进行LU分解,仅在这NB列内应用行主元,保持矩阵的其余部分不变。这个阶段称为"面板分解"(FACT),如图2a所示。只访问最左边的面板块,如图中的图案面板所示,且只在拥有这NB列部分的进程中进行。参与面板分解的进程必须频繁通信,以确定分解过程中要应用的NB个行主元。图中的箭头表示这些进程之间的通信。确定不同行主元的每次通信本质上是涉及该进程列中所有进程的全归约操作,因为进程必须共同确定主元行并接收该行的副本。在这个阶段结束时,面板列将被主元化和LU分解,产生一个在进程列之间分布的N × NB下三角矩阵L。
面板分解完成后,参与分解的每个进程将其L矩阵部分以及传达主元信息的一些索引数据打包到缓冲区中,并将此缓冲区广播到进程网格中同一行的所有其他进程。这一步如图2b所示。这一步不执行计算,只访问或修改保存L的缓冲区中的数据。由于 L 矩阵在 HPL 基准测试的大部分时间里通常很大,这个阶段的性能严重依赖于可用于进程间通信的带宽量,以及所使用的广播算法的效率。

L 矩阵和主元信息广播到所有进程后,每个进程的最后一个主要通信阶段是将 FACT 中确定的所有行主元应用到每个进程上 A 矩阵的剩余部分,并集体构造位于当前分解面板右侧的U矩阵。由于在这个阶段已知完整的NB个主元,我们可以通过等同于 MPI_Scatterv 后跟 MPI_Allgatherv 的例程批量执行所需的通信。每个进程首先将要通信的行组装到缓冲区中,这需要对其本地A矩阵进行不规则访问。包含当前分解面板的进程行中的每个进程然后通过Scatterv通信将NB源行分散到每个进程列中的目标进程。之后,一列中的所有进程通过Allgatherv通信集体组装其分布式NB×N矩阵U的部分。图2c图形化地显示了访问的数据和通信方向。
迭代的最后阶段计算量最大,但不需要进程间通信。全局矩阵的主元行已组装成 U 矩阵,FACT 的计算扩展到这些行,并作为单个 DTRSM 例程应用,使用分解对角面板的低三角部分。构造 L 和 U 矩阵并分别沿进程行和列复制后,最后的计算是对分布在所有进程中的A的尾随子矩阵应用秩NB更新。这个计算是一个分布式的 N×N×NB DGEMM,它从 A 的尾随子矩阵中减去 LU 的乘积。图2d图形化地显示了这个计算访问的数据。
3,rocHPL 的设计
AMD 的 HPL 基准测试实现 rocHPL 基于 Netlib 上托管的开源 HPL 实现。这个参考 HPL 代码使用 MPI 并行化,但没有其他并行编程模型。我们对这个 HPL 实现的修改涉及通过 AMD 的 ROCm 平台、运行时和工具链添加 GPU 支持。rocHPL 代码使用 HIP 编程语言编写,并通过 rocBLAS 数学库利用为 AMD 最新独立 GPU 高度优化的线性代数例程。
如上所述,Tan 等人和 Kim 等人的最新研究都认为,现代加速器的计算吞吐量如此之大,以至于整个矩阵A必须存储在加速器的高带宽内存(HBM)中,因为从/向 CPU 内存移动数据的成本太高。由于 AMD Instinct MI250X 加速器包含专门加速关键 DGEMM 计算的硬件,计算吞吐量甚至比这些研究考虑的还要高。因此,我们必须在 rocHPL 中采用类似的设计,将矩阵A存储在每个 MI250X 的 128 GB HBM 容量中。
然后自然要考虑是否应该在加速器上执行 HPL 基准测试的所有阶段,主机进程仅用于协调MPI通信。UPDATE 阶段当然非常适合加速器的高计算吞吐量。同样,LBCAST 和 RS 阶段也容易映射到加速器上,因为行交换所需的本地数据移动使用 GPU 的高内存带宽加速,MPI 通信可以利用 GPU之间的高带宽 Infinity Fabric 链接以及节点上 GPU 直接连接到网络接口卡(NIC)。然而,FACT 阶段在加速器上执行仍然是一个挑战。虽然 FACT 中的许多单独 BLAS 计算在 GPU 上会加速,但行主元所需的通信会要求频繁的主机-设备同步,因此会由于内核启动延迟而引入大量 GPU 空闲时间。因此,我们采用类似于 Tan 等人和 Kim 等人的方法,将必要的数据传回主机进程,以便在 CPU 上执行 FACT 计算,然后将所需数据发送回加速器。
幸运的是,在 CPU 上执行 FACT 阶段为使用 HPL 基准测试中的"前瞻"机制通过本地计算隐藏一些必要的 MPI 通信提供了一种相对简单的方法。通过注意到每次迭代的 FACT 阶段只需要矩阵的下一个 NB 列,前瞻通过在每个将在下一次迭代中执行 FACT 阶段的进程上分割 UPDATE 阶段来工作。这些进程首先只对前导 NB 列执行 UPDATE 阶段,然后立即开始将这些列传输到主机进行分解,同时在剩余的本地矩阵上完成 UPDATE 阶段。这种方法导致一次迭代的执行时间线类似于图3所示。当 UPDATE 阶段开始时,首先只对前瞻部分执行计算,以便这部分列可以传输到 CPU,然后在 FACT 阶段后传回。一旦 FACT 数据回到 GPU,就可以进行 LBCAST 通信,同时在 GPU 上完成剩余的尾随 UPDATE。不参与 FACT 阶段的进程只是在 LBCAST 阶段等待。UPDATE 阶段完成后,应用 FACT 中计算的行主元,这需要一个 GPU 内核来收集要通信的行,然后进行 MPI 通信,再用一个 GPU 内核将接收到的行散布回 A 中。
A. 多线程列块分解
在HPL基准测试开始时,每次迭代中加速器上的计算工作可以有效地隐藏FACT计算的主机传输以及LBCAST通信。但随着基准测试的进行,UPDATE阶段执行的工作量减少,直到无法再隐藏这些其他阶段。为了最大化通信和分解被UPDATE隐藏的基准测试持续时间,并在关键路径上花费最少的时间不执行UPDATE阶段,在CPU上尽可能快地执行FACT阶段至关重要。
rocHPL的设计是让每个MPI进程管理一个且仅一个GPU设备。对于MI250X GPU,其中每个模块的 GCD 对操作系统呈现为不同的 GPU,每个 MPI rank 管理一个唯一的 GCD。假设每个 MPI rank 也绑定到一个不同的 CPU 核心,这就留下了许多可能未使用的 CPU 核心,可以通过多线程在 FACT 阶段利用这些核心。虽然许多 CPU BLAS 库为计算密集的BLAS例程(如FACT中需要的DGEMM和DTRSM)提供多线程实现,但我们选择通过手动在CPU线程之间分配计算来对整个FACT阶段进行多线程处理。
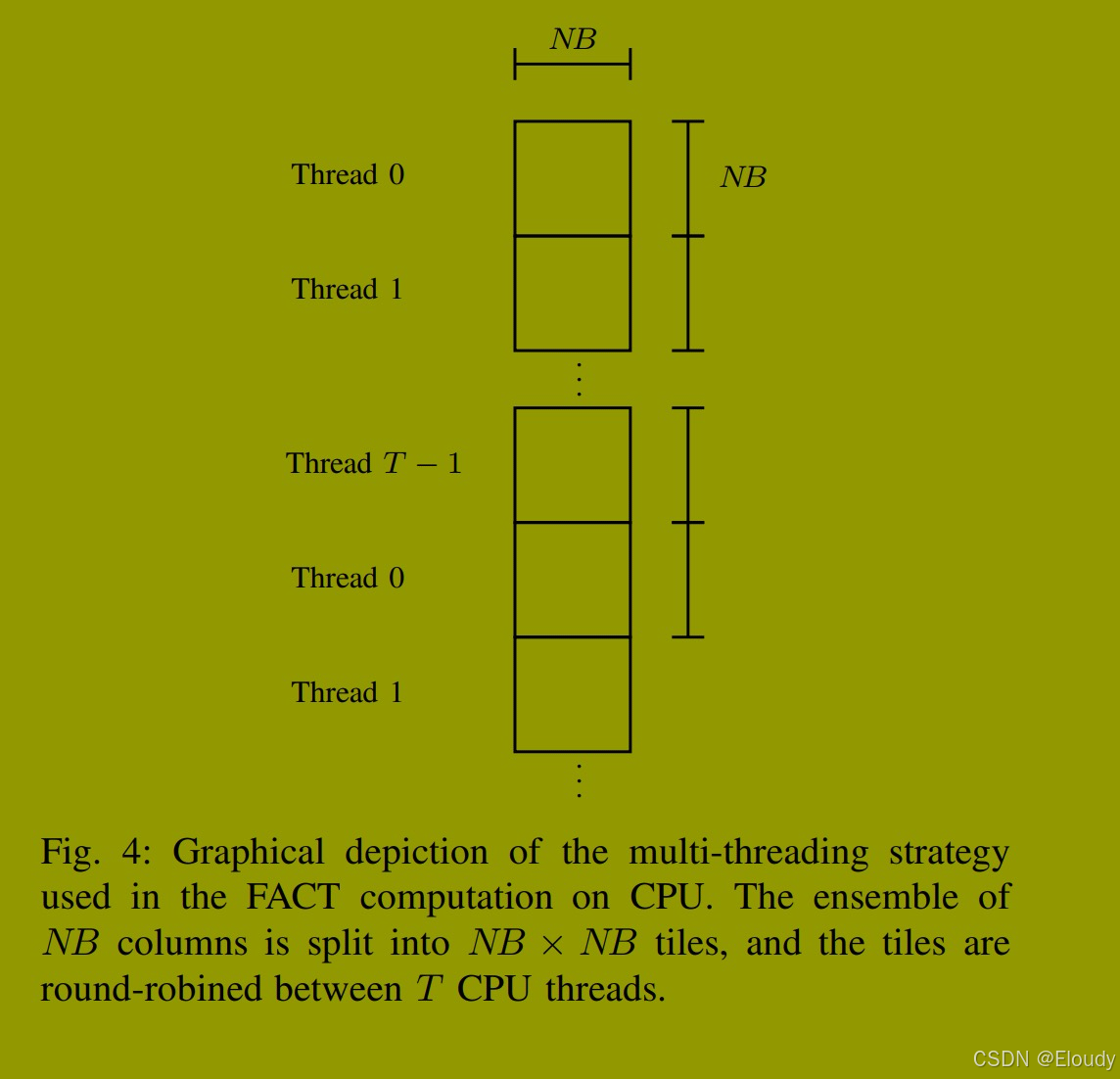
FACT阶段中进行LU分解的矩阵又高又窄。它只有NB列,但可能有数千行。这使得它适合通过在主机上的线程之间分配行块来并行化,这种方法类似于Castaldo等人的并行缓存分配(PCA)技术和Dongarra等人以及Kurzak等人关于并行面板分解的工作。在FACT阶段开始时,我们创建一个包含T个线程的OpenMP并行区域,并通过将高而窄的矩阵分块为NB行的块,以轮询方式将块分配给每个线程,如图4所示。我们选择正方形块大小纯粹是为了方便,因为这样第一个块(将包含上三角因子以及主元过程中的所有源行)保证分配给主线程。
rocHPL基于的原始Netlib HPL代码包含几种串行和分块LU分解方法,包括左看、右看和Crout分解。每种方法都可以直接用分块策略并行化。主元行的确定通过所有OpenMP线程的并行归约来实现,之后主线程调用MPI来完成进程列中所有进程的归约。然后,主线程应用行主元并与剩余线程同步,以便使用所有线程以并行方式应用对尾随子矩阵的秩1更新。对于分块分解方法,应用了类似的想法,主线程对上三角因子执行DTRSM更新,之后每个线程使用结果执行其尾随更新部分。使用这种方法,每个块中的数据只由一个线程访问,除了主线程在应用行主元时的任何访问。因此,数据可以保留在绑定该线程的物理核心附近的CPU缓存中。此外,使用Frontier上的64核AMD CPU,FACT阶段访问的所有数据通常都保留在L3缓存中。
/*解释上段中的三种方法:
左看法(Left-looking factorization):
这种方法在计算当前列时,主要使用已经计算好的左侧列。
它通过更新当前列来逐步构建LU分解。
左看法通常在内存访问方面较为高效,特别是对于大型矩阵。
右看法(Right-looking factorization):
这种方法在计算当前列后,立即更新其右侧的所有列。
它通过不断更新剩余的子矩阵来构建LU分解。
右看法通常在并行计算中表现良好,因为它允许更多的并行操作。
Crout分解(Crout factorization):
Crout方法是一种混合方法,结合了左看和右看的特点。
它同时计算L的一列和U的一行。
Crout方法在某些情况下可以提供更好的数值稳定性。
这三种方法都是实现LU分解的不同策略,各有其优缺点。选择使用哪种方法通常取决于具体的应用场景、硬件架构和性能需求。在HPL(High-Performance Linpack)基准测试中,提供多种方法可以让用户根据特定系统的特性选择最优的实现。
*/
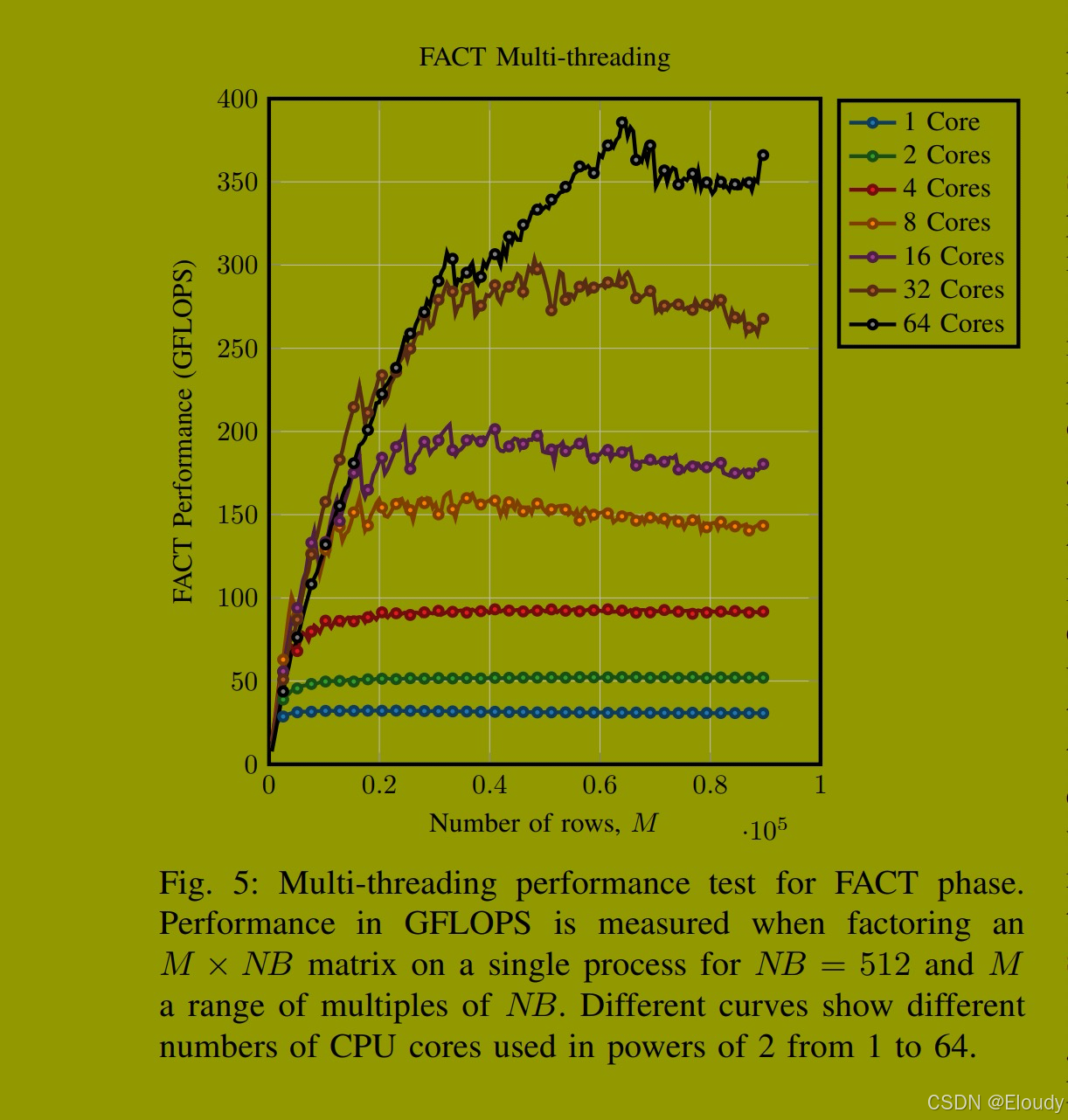
为了展示FACT阶段这种多线程策略的性能优势,我们在图5中展示了使用BLIS v4.0作为CPU BLAS库在单个Frontier节点上的性能测试结果。测量了对M × NB矩阵进行分解的FACT阶段性能,其中NB = 512,M取NB的各种倍数。我们使用单个进程运行此测试,以消除主线程用于确定和交换MPI主元的时间。使用的分解算法是递归右看,递归中有两个细分,基本块大小为16。在基本块上,使用的分解算法是右看分解。我们使用不同数量的CPU核心在这些问题规模上执行FACT计算。从图中可以看出,通过多线程,FACT阶段的性能得到了显著改善,即使对于相对较小的问题规模,使用大量CPU核心也能提高性能。
B. CPU核心时间共享
在FACT阶段的多线程策略中,一个重要的考虑因素是如何放置CPU线程以最大化每次FACT计算的性能。以Frontier节点架构为例;由于节点中有八个GCD,我们启动八个MPI进程,并将每个进程绑定到最靠近它将管理的GCD的CCD(参见[18]中的节点拓扑图)。一个自然的选择是让每个进程在进入FACT阶段时创建额外的七个OpenMP线程,这样进程可以利用其CCD中的所有八个CPU核心。
/* 对上段的解释: [18] 中的图:

There are [4x] NUMA domains per node and [2x] L3 cache regions per NUMA for a total of [8x] L3 cache regions. The 8 GPUs are each associated with one of the L3 regions as follows:
NUMA 0:
hardware threads 000-007, 064-071 | GPU 4
hardware threads 008-015, 072-079 | GPU 5
NUMA 1:
hardware threads 016-023, 080-087 | GPU 2
hardware threads 024-031, 088-095 | GPU 3
NUMA 2:
hardware threads 032-039, 096-103 | GPU 6
hardware threads 040-047, 104-111 | GPU 7
NUMA 3:
hardware threads 048-055, 112-119 | GPU 0
hardware threads 056-063, 120-127 | GPU 1
*/
然而,通常一个进程可以利用比简单分区所有可用核心更多的CPU核心。考虑Frontier节点架构上的2D进程网格P × Q = 2 × 4。在HPL计算的任何给定迭代中,只有两个进程会协调计算面板分解,而其他六个进程在等待接收LBCAST。如果执行面板分解的两个进程各使用八个CPU核心,而剩余的六个MPI进程各使用一个CPU核心,那么在这次迭代中,插槽上会有42个空闲的CPU核心。随着基准测试进行迭代,每个FACT阶段使用的16个CPU核心总数将在不同的CCD之间循环,但我们仍然会在每次迭代中观察到总共42个空闲的CPU核心。基于这个观察,我们考虑通过将OpenMP线程过度订阅到物理CPU核心来利用每个HPL迭代中的所有CPU核心的通用方法。
在将节点本地P×Q进程网格启动到具有C个CPU核心的节点的一般情况下,我们将每个进程绑定到不同的根核心,并将剩余的C¯ = C - PQ核心视为资源池。这个池被分成P个不重叠的组,每组有C¯/P个核心,每组分配给不同的进程行。然后,每个进程列中的每个 MPI rank 使用 OpenMP 绑定来指定总共 T = 1 + C¯/P 个 OpenMP 线程,并将它们绑定到其根核心和其进程行的池分区。这样,每个FACT阶段将利用节点上总共PT = P + C¯个CPU核心。在节点上P × 1本地进程网格的极端情况下,这种核心绑定简化为可用CPU核心的简单分区,因为节点上的所有进程必须同时参与FACT阶段。在节点上1 × Q本地进程网格的另一个极端情况下,CPU核心共享量最大化,因为在任何给定时间最多只有一个节点上的进程会计算FACT阶段。
在rocHPL中,我们实现了一个通用的包装脚本,在启动基准测试时计算这些OpenMP绑定。CPU核心时间共享以及全局问题在计算节点之间的分解使用用户输入,描述每个节点上所需的本地进程网格配置。
C. 分割更新
从图3的执行时间线视图中可以看出,主机CPU和加速器之间的工作分配使我们能够有效地将FACT和LBCAST阶段隐藏在本地UPDATE计算之后。然而,执行RS阶段所需的通信时间仍然导致加速器的空闲时间。因此,考虑通过本地计算来隐藏这一通信时间是有利的。

实现这种通信隐藏的一个简单方法是将RS和UPDATE阶段按列划分为几个较小的块,并应用流水线策略。通过这种方式,对一个块执行UPDATE阶段的本地计算可以隐藏下一个块的RS阶段的通信时间。这种策略在Tan等人和Kim等人的研究中得到了应用,他们都使用多线程实现来协调不同的块和不同的阶段。然而,这种多线程策略在我们的HPL实现中成本较高,因为使用多个线程来流水线不同的阶段会占用本可以用于FACT的CPU核心。
因此,我们选择了一种替代方法来隐藏RS阶段的通信时间,这种方法不需要额外的多线程,我们称之为“分割更新”。我们用n表示HPL基准测试开始时进程本地A矩阵的列数。注意,由于A的二维块循环分布,n在每个进程列中都是相同的。考虑将本地矩阵按列分割为两部分,分别为n1和n2列,我们称之为本地A矩阵的“左”部分和“右”部分。我们选择n1,使其为NB的倍数。我们用UPDATE1和UPDATE2分别表示对左部分和右部分应用UPDATE阶段,同样适用于RS阶段。分割更新的想法是利用一个部分的UPDATE计算来隐藏另一个部分的RS阶段的MPI通信。关键观察是,为了做到这一点,必须在开始另一个部分的UPDATE之前收集一个部分所需的行以进行RS阶段。
分割更新的公式导致的执行时间线类似于图6所示。在每次迭代开始时,我们假设RS2通信已经完成。也就是说,我们假设本地A矩阵的右部分的行已经被通信,尽管不一定已经散布回A。我们开始迭代,通过从前瞻部分和左部分收集所需的行进行通信,并将右部分的通信行散布回A。在散布行的同时,仅执行前瞻部分的行通信,接收到的行写入前瞻部分。然后,迭代按没有分割更新的方式进行,UPDATE阶段在前瞻部分执行,结果复制回主机以进行FACT阶段和后续的LBCAST。在执行传输、FACT和LBCAST的同时,UPDATE2阶段在加速器上计算。然而,由于左部分的行已经为通信收集,因此此时也可以执行RS1通信,并被UPDATE2隐藏。在UPDATE2之后,右部分的下一次迭代的行被收集,以准备RS2通信。然后可以排队UPDATE1阶段,首先将通信行散布回A,RS2通信可以通过此本地计算来隐藏。注意,如果此过程执行了FACT阶段,则UPDATE1中更新的列数将为n1 - NB。
由于左侧和右侧更新以交错的方式进行,并与各自的行收集和散布交替进行,因此我们必须在每次迭代中保持每个进程的本地A矩阵右部分的列数n2固定,而n1则减少。由于我们选择n1为NB的倍数,最终n1将等于NB,前瞻部分最终将成为剩余左部分的全部。在这种情况下,将不再有分割更新的公式,迭代将回落到图3所示的形式,其中RS通信不再被UPDATE隐藏。
为了使分割更新公式有效地隐藏所有通信时间,本地A矩阵的右部分必须足够大,以隐藏与主机之间的数据传输,以及FACT、LBCAST和RS1阶段。因此,自然会问:如果UPDATE2阶段最初可以隐藏在这些阶段中花费的所有时间,随着基准测试的进行,它是否会继续隐藏这些时间?为了解决这个问题,注意到由于n2保持固定而n1减少,UPDATE2阶段在每次迭代中始终更新A的相同列数,只要n1保持非零。在计算成本方面,当n2保持固定时,UPDATE2计算与在此进程中更新的本地A的行数m线性缩放。同样,UPDATE2隐藏的其他阶段(除了RS1阶段)也与m共享这种线性缩放。实际上,主机之间的数据传输、FACT阶段和LBCAST阶段在每次迭代中更新的本地A的行数上都有线性复杂度。另一方面,RS1中的行交换通信的复杂度与n1成线性关系,因此随着n1的减少而减少。这一速率大致与本地A的行数减少的速率相同。因此,我们可以得出结论,如果UPDATE2最初可以隐藏这些组件中的每一个,它将继续隐藏它们,直到左部分减少到零列,RS2通信不再能够被隐藏。在实践中,我们观察到这种分割更新公式能够在单个Frontier节点上隐藏HPL基准测试执行时间的约75%的所有MPI通信。
由于选择n2的大小至关重要,以便仅足够隐藏FACT、LBCAST和RS1阶段,因此在基准测试开始时的选择是分割更新公式中的一个关键考虑因素。虽然可以使用一些性能模型来估计n2的最佳大小,但我们允许用户输入一个“分割比例”参数到rocHPL,以指示A的右部分应包含的列的百分比,并将此输入作为调优参数。对于在单个Frontier节点上运行的HPL,我们通常发现将本地A矩阵在左部分和右部分之间平分效果最佳。

















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









