






1,简介 Dynamic Parallelism
Dynamic Parallelism 是 CUDA 的一项特性,允许一个 CUDA kernel 在 GPU 上直接启动其他 CUDA kernel,而无需返回主机。这种特性使得在 GPU 上可以实现更复杂的并行计算模式,特别适用于递归算法、分层次计算和自适应网格细化等场景。
2,示例一:kernel 启动单个 kernel
#include <iostream>
#include <cuda_runtime.h>
// 子 kernel,计算每个元素的平方
__global__ void childKernel(int* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
data[idx] +=100;
}
}
// 父 kernel,启动子 kernel
__global__ void parentKernel(int* data, int n) {
// 假设每个 block 处理 256 个元素
int threadsPerBlock = 1024;
int blocks = (n + threadsPerBlock - 1) / threadsPerBlock;
// 启动子 kernel
childKernel<<<blocks, threadsPerBlock>>>(data, n);
// 等待子 kernel 完成
// cudaDeviceSynchronize();
}
// 主机代码
int main() {
const int n = 1024*1024*512;
int* h_data = new int[n];
int* d_data;
// 初始化数据
for (int i = 0; i < n; ++i) {
h_data[i] = i;
}
// 分配设备内存
cudaMalloc(&d_data, n * sizeof(int));
cudaMemcpy(d_data, h_data, n * sizeof(int), cudaMemcpyHostToDevice);
// 启动父 kernel
parentKernel<<<1, 1>>>(d_data, n);
// 复制结果回主机
cudaMemcpy(h_data, d_data, n * sizeof(int), cudaMemcpyDeviceToHost);
// 输出结果
for (int i = 0; i < 10; ++i) {
std::cout << h_data[i] << " ";
}
std::cout << std::endl;
// 清理
delete[] h_data;
cudaFree(d_data);
return 0;
}编译:
nvcc hello.cu -rdc=true -arch=sm_75 -lcudart -Xcompiler -lcudadevrt
或者Makefile:
DEV_FLAGS := -rdc=true -arch=sm_75 -Xcompiler
EXE := hello
aLL: $(EXE)
%: %.cu
nvcc $< -o $@ $(DEV_FLAGS) -lcudart -lcudadevrt
.PHONY: clean
clean:
-rm -rf $(EXE)运行:
![]()
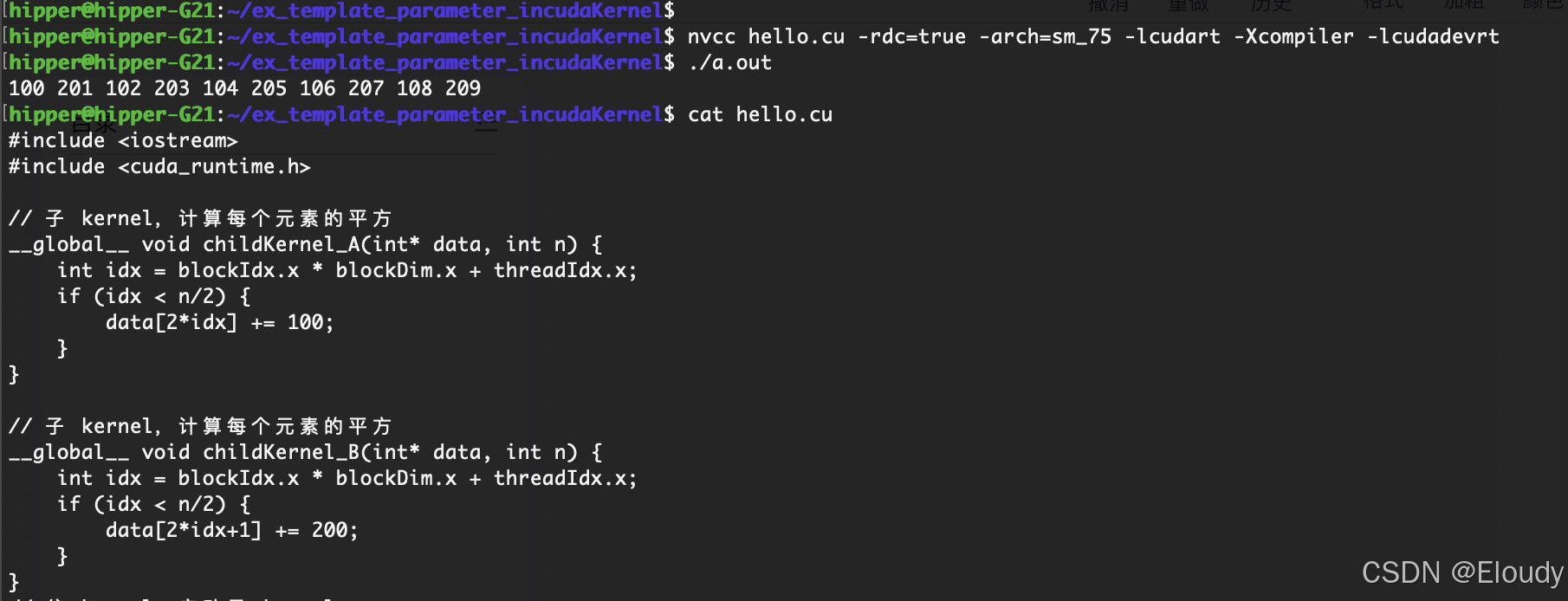
3,示例二:kernel 启动两个 kernel
#include <iostream>
#include <cuda_runtime.h>
// data[2k] += 100;
__global__ void childKernel_A(int* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n/2) {
data[2*idx] += 100;
}
}
//data[2k+] += 200;
__global__ void childKernel_B(int* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n/2) {
data[2*idx+1] += 200;
}
}
// launch kernels
__global__ void parentKernel(int* data, int n) {
if(threadIdx.x==0){
int threadsPerBlock = 1024;
int blocks = (n/2 + threadsPerBlock - 1) / threadsPerBlock;
childKernel_A<<<blocks, threadsPerBlock>>>(data, n);
//cudaDeviceSynchronize();
}
else if(threadIdx.x==1){
int threadsPerBlock = 1024;
int blocks = (n/2 + threadsPerBlock - 1) / threadsPerBlock;
childKernel_B<<<blocks, threadsPerBlock>>>(data, n);
}
}
int main() {
const int n = 1024*1024*512;
int* h_data = new int[n];
int* d_data;
for (int i = 0; i < n; ++i) {
h_data[i] = i;
}
cudaMalloc(&d_data, n * sizeof(int));
cudaMemcpy(d_data, h_data, n * sizeof(int), cudaMemcpyHostToDevice);
parentKernel<<<1, 2>>>(d_data, n);
cudaMemcpy(h_data, d_data, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < 10; ++i) {
std::cout << h_data[i] << " ";
}
std::cout << std::endl;
delete[] h_data;
cudaFree(d_data);
return 0;
}nvcc hello.cu -rdc=true -arch=sm_75 -lcudart -Xcompiler -lcudadevrt
运行:
4,总结:
4.1 优势
减少主机干预: 通过在设备上直接启动子 kernel,减少了主机与设备之间的通信开销。
简化代码结构: 允许在 GPU 上实现更复杂的控制流和计算模式。
提高性能: 在某些场景下,通过减少主机干预和优化并行计算,可以提高整体性能。
4.2 使用场景
需要与其他 GPU 计算框架集成,需要精细控制 GPU 资源和行为。
递归算法: 如快速排序、树形数据结构遍历。
自适应网格细化: 在计算流体力学和其他科学计算中。
分层次计算: 如多级网格方法。

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









