






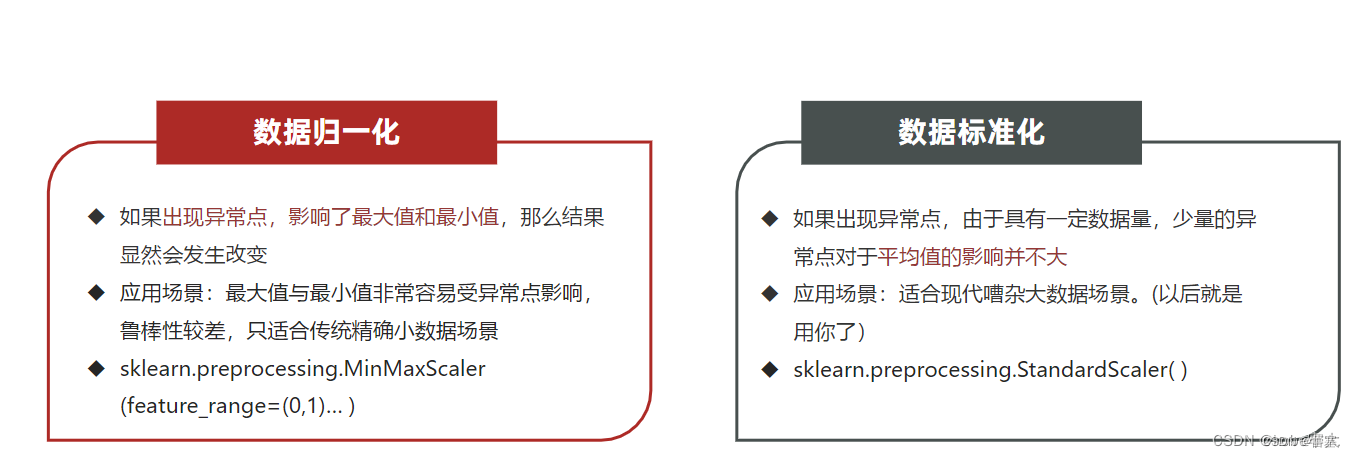
一、特征预处理
为什么做归一化和标准化 ?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响
(支配)目标结果,使得一些模型(算法)无法学习到其它的特征。
经典案例:利用python实现knn分类算法,用鸢尾花数据集
具体代码如下:
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import seaborn as sns
import pandas as pd
#加载数据集
iris_data = load_iris()
print(f'数据集-->\n{iris_data.feature_names}\n{iris_data.data[:10]}')
print(f'\n目标数-->\n{iris_data.target_names}\n{iris_data.target}')
#数据展示
iris_df = pd.DataFrame(iris_data['data'],columns=iris_data.feature_names)
iris_df['target'] = iris_data.target
print(iris_df)
feature_names = list(iris_data.feature_names)
print(feature_names)
for i in range(len(feature_names)):
for j in range(i+1,len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
sns.lmplot(x=col1,y=col2,hue='target',data=iris_df)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f'{col1} vs {col2}')
plt.show()
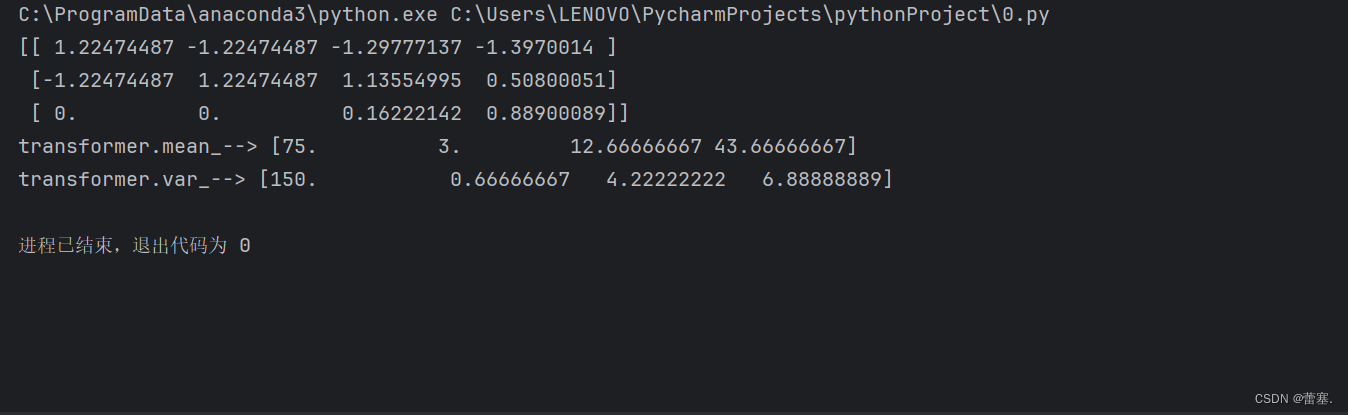
from sklearn.preprocessing import StandardScaler
def dm03_StandardScaler():
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化标准化对象
transformer = StandardScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
# 5. 打印每列数据的均值和标准差
print('transformer.mean_-->', transformer.mean_)
print('transformer.var_-->', transformer.var_)
# 调用函数
dm03_StandardScaler()
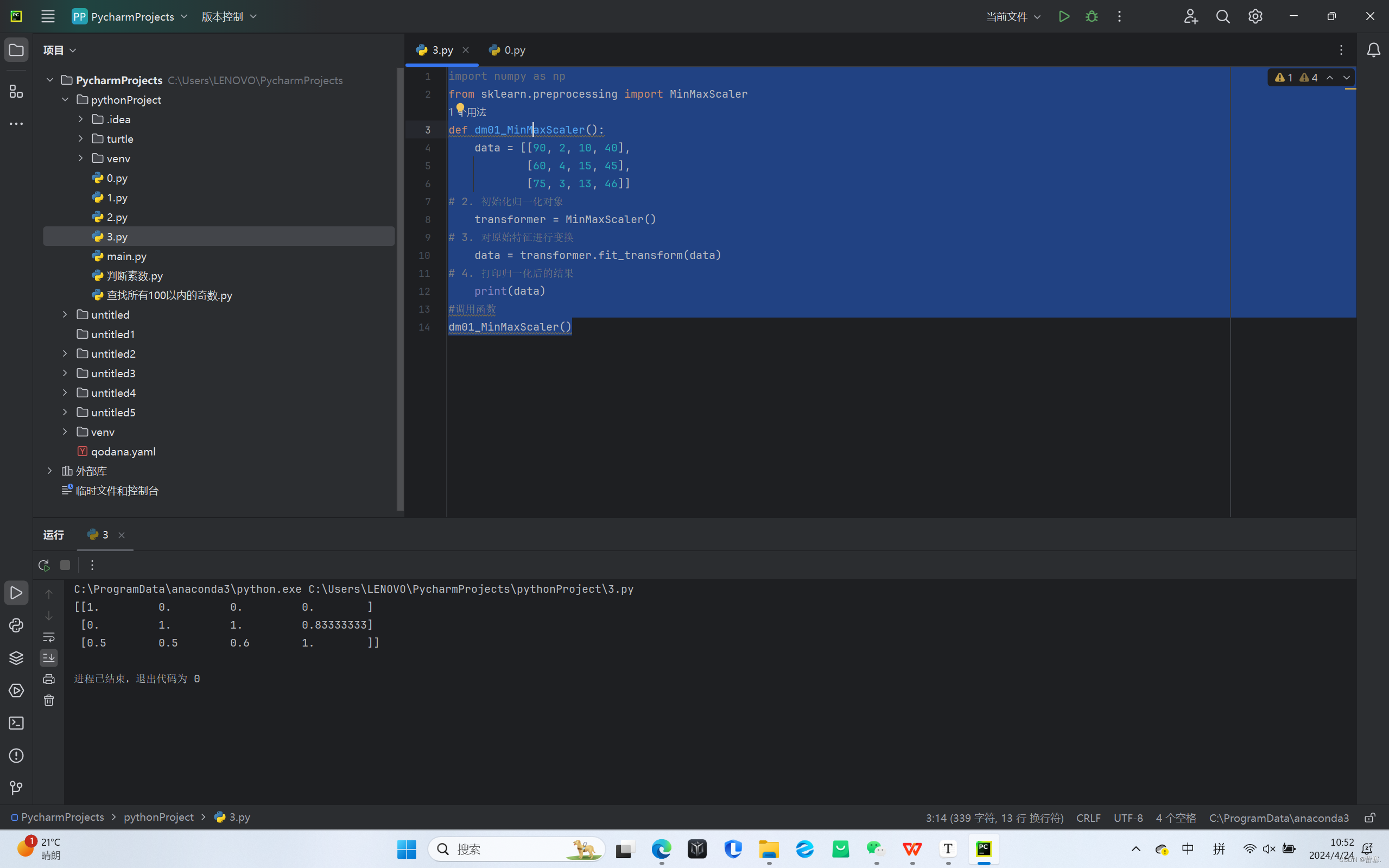
import numpy as np
from sklearn.preprocessing import MinMaxScaler
def dm01_MinMaxScaler():
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
#调用函数
dm01_MinMaxScaler()















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









