






论文地址:https://arxiv.org/abs/1911.08947v2
 https://github.com/open-mmlab/mmocr
https://github.com/open-mmlab/mmocr一:网络简介

网络结构:
U-net特征提取 + FPN多尺度特征融合 + 文本区域分割/文本边界回归 + 可微二值化 = 文本bbox
可微二值化(Differentiable Binarization ) :
创新点在于对每一个像素点进行自适应二值化,二值化阈值由网络学习,提高文本检测鲁棒。
可微二值化公式如下:
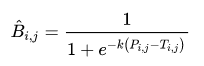
类似于sigmoid(蓝色)激活函数,DB(红色)函数曲线如下:

网络输出:
probability map :文本概率图
threshold map :文本阈值图
binary map :由probability map和threshold map通过DB公式计算得到的文本二值图
Loss函数:
![]()
L_s:文本实例概率图的loss
L_t:阈值图loss
L_b:DBloss,即文本二值图的loss
二:数据处理
数据前处理(训练阶段):

其中:
img:原始图像增强(旋转翻转resize等)之后随机crop,然后等比例长边resize到640,短边padding到640,最终得到640x640训练样本
gt_shrink0:probability map
gt_thr: threshold map
gt_shrink_mask0 & gt_thr_mask0: 损失计算mask图
后处理(仅推理阶段使用):
直接使用 0.3 概率阈值二值化 probability map 得到文本二值图
三:训练可能出现问题
Q:测试recall指标很低,可视化结果文本bbox漏检很多?
A:先输出文本二值化图,如果二值化图中文本已经被分割出来说明推理后处理阶段参数不合适;
可以调小bbox阈值 或者 更改曲线多边形拟合参数 或者 直接使用外接矩形选取二值图文本区域
Q:训练出现Loss发散,最终不收敛的情况?
A:一般会根据 数据前处理、loss选择、网络结构 三个方面依次分析;
数据前处理:
首先可视化输入网络数据,如下图所示:

过于密集的文本会最终导致不计入loss,当这样的样本过多时容易训练发散;
可以去除异常数据,增加全局数据,调整训练测试尺度(对比640随机crop)
loss选择:
一般会使用bbce(平衡二值交叉熵)、L1(L1回归损失)和dice
当样本前景稀疏,dice更好,反之bbce更好
网络结构:
当增大backbone收益不在增加,可以尝试DCN(可变卷积)模块增强特征学习
因为基于MMOCR项目训练实验,可以快速使用MMdetection支持backbone快速实验
比如最近比较火的swin transformer backbone,只需更改configs文件即可:

















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











