







文章目录
- 检测(Detection)在计算机视觉中的位置
- 检测任务
- 几个文本检测的较新方法
- FOTS(【2018CVPR】Fast Oriented Text Spotting with a Unified Network)
- TextSnake(【2018ECCV】 TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes)
- ContourNet(【2020 CVPR】ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection)
- ABCNet(【2020 CVPR Oral】ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network)
- 参考
文本检测(Text Detection)是计算机视觉领域的经典问题,该技术旨在寻求一种可靠方法作为文本识别技术的前端,是目标检测(Object Detection)领域的一个子问题
检测(Detection)在计算机视觉中的位置
计算机视觉有四大基本任务: 分割(classification)、定位(检测localization、detection)、语义分割(Semantic segmentation)、实例分割(Instance segmentation)

这四个任务需要对图像的理解逐步深入。给定一张输入图像,图像分类任务旨在判断该图像所属类别。定位是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。但是,语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。此外,目标跟踪通常是用于视频数据,和目标检测有密切的联系,同时要利用帧之间的时序关系。
作者:张皓
链接:https://www.zhihu.com/question/36500536/answer/304469552
来源:知乎

上图中,从上到下逐渐复杂
复杂程度: 分割(同分类)–>定位(一个或固定数目的目标)–>检测(和定位其实很类似,也是用一个bounding box)–>语义分割(像素级的分割)–>实例分割(在前者的基础上区分出同类的不同实例)
检测任务
经典数据集
PASCAL VOC 包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。
MS COCO COCO比VOC更困难。COCO包含80k训练图像、40k验证图像、和20k没有公开标记的测试图像(test-dev),80个类别,平均每张图7.2个目标。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试。区别于ImageNet常用于做分类,COCO用来做检测,因为COCO没label
评价指标
mAP (mean average precision) 目标检测中的常用评价指标,计算方法如下。当预测的包围盒和真实包围盒的交并比大于某一阈值(通常为0.5),则认为该预测正确。对每个类别,我们画出它的查准率-查全率(precision-recall)曲线,平均准确率是曲线下的面积。之后再对所有类别的平均准确率求平均,即可得到mAP,其取值为[0, 100%]。
交并比(intersection over union, IoU) 算法预测的包围盒和真实包围盒交集的面积除以这两个包围盒并集的面积,取值为[0, 1]。交并比度量了算法预测的包围盒和真实包围盒的接近程度,交并比越大,两个包围盒的重叠程度越高。
发展历史
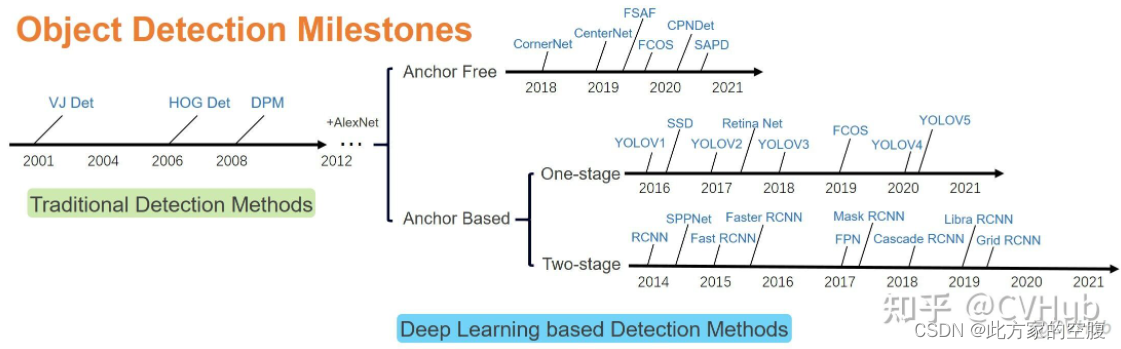
经典的LeNet、AlexNet、VGG、GoogleNet用来做分类,RCNN、Fast RCNN、Faster RCNN、YOLO、SSD则用来做检测
-
单阶段目标检测方法是指只需一次提取特征即可实现目标检测,其速度相比多阶段的算法快,一般精度稍微低一些
-
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修),这类算法的典型代表是基于region proposal的R-CNN系算法,如R-CNN,SPPNet ,Fast R-CNN,Faster R-CNN,FPN,R-FCN等
什么叫Anchor
熟悉PS、AE等图像视频处理软件的盆友可能在软件使用中见过"锚点"工具,这个锚点与目标检测中的anchor的作用就是类似的。anchor就是一些图像上预设好的一些不同大小、比例的检测框,换句话也可以说anchor是一些预先的滑动窗口的中心点。
以下引用"AIZOO"公众号中对其的解释
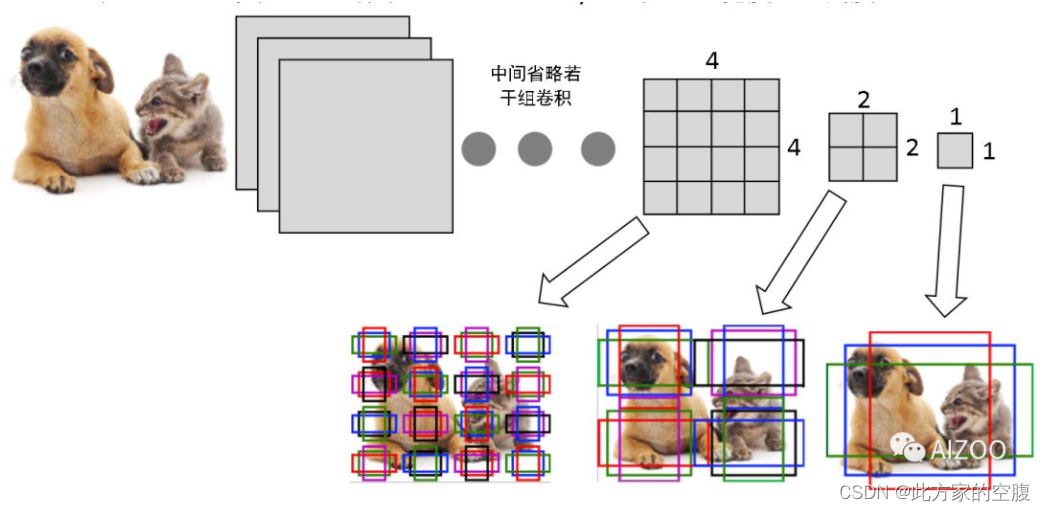
下图来自《动手学深度学习》中的例子,假设一个256x256大小的图片,经过64、128和256倍下采样,会产生4x4、2x2、1x1大小的特征图,我们在这三个特征图上每个点上都设置三个不同大小的anchor。当然,这只是一个例子,实际的SSD模型,在300x300的输入下,anchor数量也特别多,其在38x38、19x19、10x10、5x5、3x3、1x1的六个特征图上,每个点分别设置4、6、6、6、6、4个不同大小和长宽比的anchor,所以一共有38x38x4+ 19x19x6+ 10x10x6+ 5x5x6+ 3x3x4+ 1x1x4= 8732个anchor。
上图中,每个fearture map"像素点"上画出的三种颜色的检测框位置(或者检测框的中心位置)对应到原图上就是anchor的位置,详细内容进入链接新手也能彻底搞懂的目标检测进行查看
检测架构
当前的目标检测器通常由一个与检测任务无关的主干特征提取器和一组包含检测专用先验知识的颈部和头部组成。颈部 / 头部中的常见组件可能包括感兴趣区域(RoI)操作、区域候选网络(RPN)或锚、特征金字塔网络(FPN)等。如果用于特定任务的颈部 / 头部的设计与主干的设计解耦,它们可以并行发展。从经验上看,目标检测研究受益于对通用主干和检测专用模块的大量独立探索。长期以来,由于卷积网络的实际设计,这些主干一直是多尺度、分层的架构,这严重影响了用于多尺度(如 FPN)目标检测的颈 / 头的设计。
机器之心: https://www.jiqizhixin.com/articles/2022-04-01-10
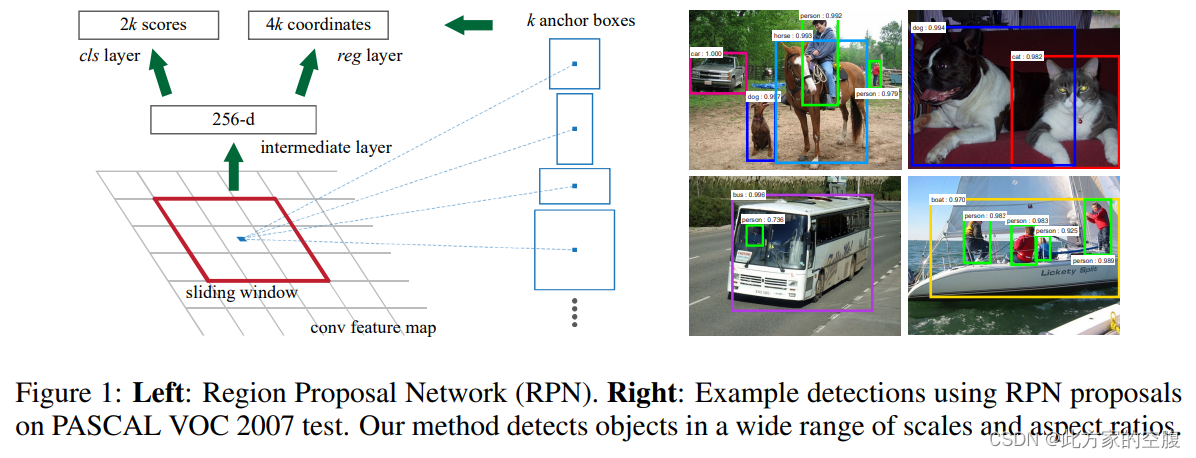
RPN
FasterRCNN前言:
State-of-the-art object detection networks depend on region proposal algorithms
to hypothesize object locations. Advances like SPPnet and Fast R-CNN
have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a
fully-convolutional network that simultaneously predicts object bounds and objectness scores at each position. RPNs are trained end-to-end to generate highquality region proposals, which are used by Fast R-CNN for detection. With a
simple alternating optimization, RPN and Fast R-CNN can be trained to share
convolutional features. For the very deep VGG-16 model [19], our detection
system has a frame rate of 5fps (including all steps) on a GPU, while achieving
state-of-the-art object detection accuracy on PASCAL VOC 2007 (73.2% mAP)
and 2012 (70.4% mAP) using 300 proposals per image. Code is available at
https://github.com/ShaoqingRen/faster_rcnn.
上图为原文中解释RPN网络结构的图。文章中说RPN为一个全卷积层
上图为常见的解释FasterRCNN的图。注意其中RPN的位置(向左上方的箭头也就是RPN)
- 图中RoI Pooling的作用: 和一般的pooling一样,是为了减少feature map的像素量,加快运算速度
- 最后的classifier为一个FC和softmax,输出每个proposal具体属于哪个类别的概率
参考文章https://zhuanlan.zhihu.com/p/31426458第四节,结构如下。可见其不仅用softmax输出分类概率(每个物体属于哪类的概率),还回归推断了bbox的新位置(bbox_pred)

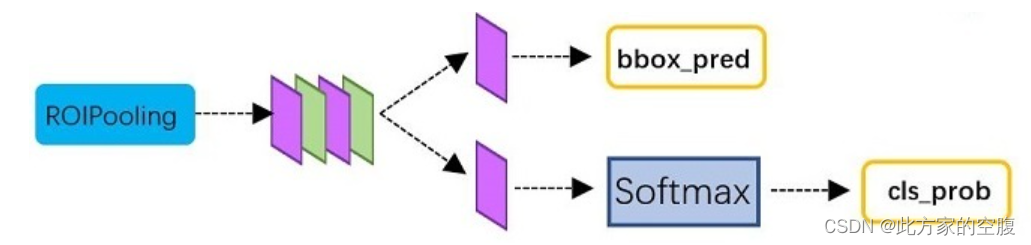
RPN(Region Proposal Network)来源于Faster RCNN。RCN是Faster RCNN的backbone
FasterRCNN= RPN + FastRCNN
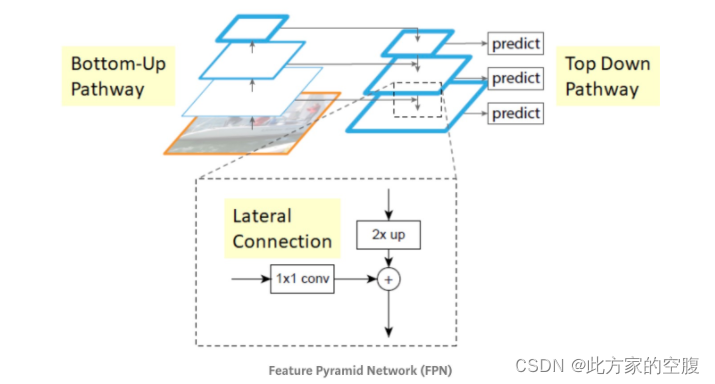
FPN(特征金字塔网络)
FPN([2016 CVPR]): https://arxiv.org/abs/1612.03144
前言: 特征金字塔是识别系统中用于检测不同尺度对象的基本组件。但是最近的深度学习对象检测器已经避免了金字塔表示,部分原因是它们是计算和内存密集型的。在本文中,我们利用深度卷积网络固有的多尺度金字塔层次结构来构建具有边际额外成本的特征金字塔。开发了一种具有横向连接的自上而下的架构,用于在所有尺度上构建高级语义特征图。这种称为特征金字塔网络 (FPN) 的架构在多个应用程序中作为通用特征提取器显示出显着的改进。在基本的 Faster R-CNN 系统中使用 FPN,我们的方法在 COCO 检测基准上实现了最先进的单模型结果,没有花里胡哨,超越了所有现有的单模型条目,包括来自 COCO 2016 挑战赛获胜者的条目。
FPN的特征金字塔很不一样的地方在于这种金字塔有横向的连接
这种金字塔的区分可以参考这篇文章: http://note4lin.top/post/fpn/
机器之心: https://www.jiqizhixin.com/articles/2017-07-25-2
一些特征金字塔的对比
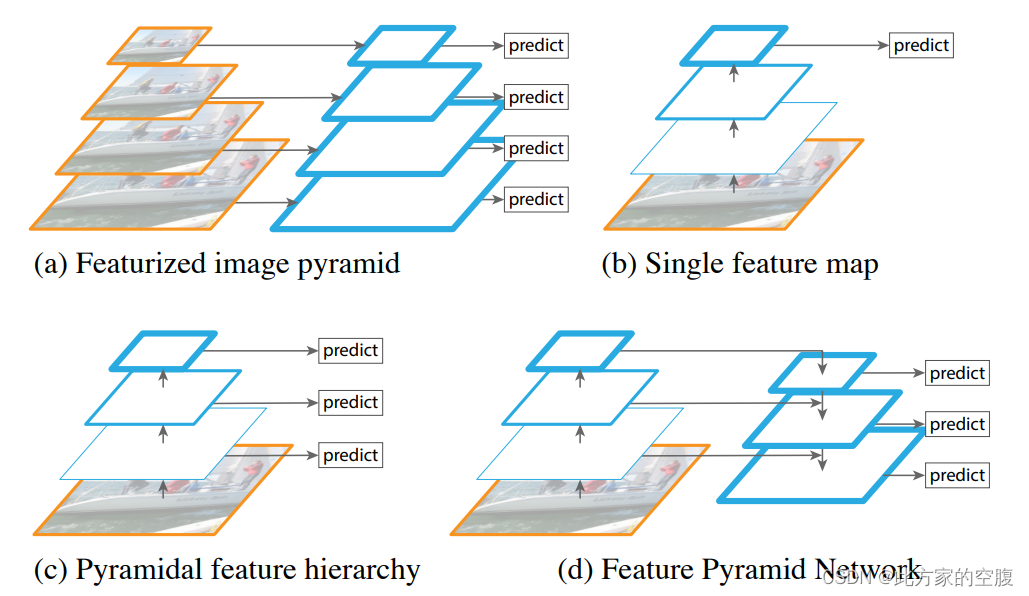
(a) 使用图像金字塔构建特征金字塔。特征是在每个图像尺度上独立计算的,这很慢。
(b) 最近的检测系统选择仅使用单尺度特征来加快检测速度。
© 另一种方法是重用由 ConvNet 计算的金字塔特征层次结构,就好像它是一个特征化的图像金字塔一样。
(d) FPN提出的特征金字塔网络 (FPN) 与 (b) 和 © 一样快,但更准确。在该图中,特征图由蓝色轮廓表示,较粗的轮廓表示语义上更强的特征。
下图是上图中D的更准确描述
几个文本检测的较新方法
FOTS(【2018CVPR】Fast Oriented Text Spotting with a Unified Network)
这篇论文是一个集合了文本检测跟文字识别两部分的一个统一的端到端的框架,可同时对图像中的文字进行检测跟识别。
之前的大部分方法都是将检测跟识别当做两个独立的任务去做,先检测,再识别。这篇论文提出的框架处处是可微的,所以可以对其进行端到端的训练,结果表明,该网络无需复杂的后处理和高参数整定,易于训练,并且在保证精度的前提下大大提高速度
如下图所示

FOTS作为端到端的文本识别,使用了44.2ms; 而用某种其他方法,先检测再识别,两个步骤都分别用了四十多ms
TextSnake(【2018ECCV】 TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes)

对于一般的文本检测,往往用一个矩形框框出内容,而TextSnake采用弯曲的凸N边形框出内容并复原为矩形,这样使得文本检测更加有效
网络结构

ContourNet(【2020 CVPR】ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection)
文章设计了文本水平与竖直方向的轮廓检测方法,对尺度(形状)变化大的文本检测任务提高了精确度

上半部分是用简单BoundingBox做的检测
下半部分用水平与竖直两方向进行检测并融合,也即文章目的
ABCNet(【2020 CVPR Oral】ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network)
Adaptive-Bezier Curve Network
主要部分是通过参数化的贝塞尔曲线作为线框来检测文本,提高了检测的有效性,并且速度较快,达到了实时性的要求

如上图所示,对一个弯曲形的文字,使用Bezier曲线来对齐(所谓BezierAlign),并拉成一个平的,从而有了更好的效果


















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









