









训练
创建环境:
conda create -n trans python=3.6
conda install rdkit -c rdkit
conda install future six tqdm pandas
pip torch torchvision torchaudio (cuda 11.1等)
pip install torchtext==0.3.1
租用服务器使用及环境安装,可以将其看成远程服务器Linux系统。
1、将代码传到work的同目录,数据只能是data目录。
可以 ls 查看当前目录
2、环境中是有anaconda的,直接根据自己所需创建一个环境。
- 自己的项目为例 (建议使用pip单个安装,不然会报错)
conda create -n trans python=3.6
conda install rdkit -c rdkit
conda install future six tqdm pandas
- torch的安装
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116,这里的cu116,就可以根据自己的环境换成cu11x等,x就是相应的cuda版本。 pip install torchtext==0.3.1
3、开始训练——逆合成
- 处理数据
dataset=STEREO_separated_augm
python preprocess.py -train_src data/${dataset}/tgt-train.txt \
-train_tgt data/${dataset}/src-train.txt \
-valid_src data/${dataset}/tgt-val.txt \
-valid_tgt data/${dataset}/src-val.txt \
-save_data data/${dataset}/${dataset} \
-src_seq_length 1000 -tgt_seq_length 1000 \
-src_vocab_size 1000 -tgt_vocab_size 1000 -share_vocab
注意,这里保持原代码不变, 即model_builder.py里面的261行处:
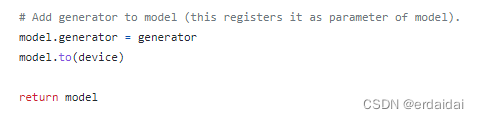
后续在没有gpu的环境运行保存的模型会在这里改动。
- 开始训练
dataset=STEREO_separated_augm
python train.py -data data/${dataset}/${dataset} \
-save_model experiments/checkpoints/${dataset}_model \
-seed 42 -gpu_ranks 0 -save_checkpoint_steps 10000 -keep_checkpoint 20 \
-train_steps 500000 -param_init 0 -param_init_glorot -max_generator_batches 32 \
-batch_size 4096 -batch_type tokens -normalization tokens -max_grad_norm 0 -accum_count 4 \
-optim adam -adam_beta1 0.9 -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 \
-learning_rate 2 -label_smoothing 0.0 -report_every 1000 \
-layers 4 -rnn_size 256 -word_vec_size 256 -encoder_type transformer -decoder_type transformer \
-dropout 0.1 -position_encoding -share_embeddings \
-global_attention general -global_attention_function softmax -self_attn_type scaled-dot \
-heads 8 -transformer_ff 2048
3、开始训练——正向预测
- 处理数据
dataset=STEREO_separated_augm
python preprocess.py -train_src data/${dataset}/src-train.txt \
-train_tgt data/${dataset}/tgt-train.txt \
-valid_src data/${dataset}/src-val.txt \
-valid_tgt data/${dataset}/tgt-val.txt \
-save_data data/${dataset}/${dataset} \
-src_seq_length 1000 -tgt_seq_length 1000 \
-src_vocab_size 1000 -tgt_vocab_size 1000 -share_vocab
- 开始训练
dataset=STEREO_separated_augm
python train.py -data data/${dataset}/${dataset} \
-save_model experiments/checkpoints/${dataset}_model \
-seed 42 -gpu_ranks 0 -save_checkpoint_steps 10000 -keep_checkpoint 20 \
-train_steps 500000 -param_init 0 -param_init_glorot -max_generator_batches 32 \
-batch_size 4096 -batch_type tokens -normalization tokens -max_grad_norm 0 -accum_count 4 \
-optim adam -adam_beta1 0.9 -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 \
-learning_rate 2 -label_smoothing 0.0 -report_every 1000 \
-layers 4 -rnn_size 256 -word_vec_size 256 -encoder_type transformer -decoder_type transformer \
-dropout 0.1 -position_encoding -share_embeddings \
-global_attention general -global_attention_function softmax -self_attn_type scaled-dot \
-heads 8 -transformer_ff 2048
部署
创建环境:
conda create -n trans python=3.7
conda activate trans
conda install rdkit -c rdkit
conda install future six tqdm pandas
安装相关的库:
(没有GPU的机器上部署)
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install torchtext==0.3.1
pip install flask















 2020
2020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









