







一、什么是检索增强的生成模型(RAG)
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
1.1 大模型目前固有的局限性
- 1.LMM的知识不是实时的
- 2.LMM可能不知道你私有的领域/业务知识
1.2 检索增强生成(RAG)
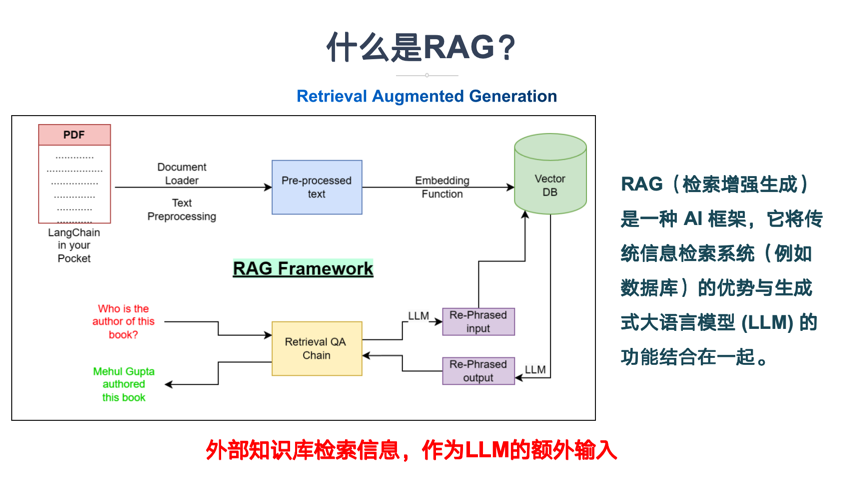
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成),RAG是一种 AI 框架,它将传统信息检索系统(例如数据库)的优势与生成式大语言模型 (LLM) 的功能结合在一起。
LLM通过将这些额外的知识与自己的语言技能相结合,可以撰写更准确、更具时效性且更贴合具体需求的文字。
如何理解RAG?
通过上一个问题,我们知道了什么是RAG?了解到RAG是一种结合了信息检索、文本增强和文本生成的自然语言处理(NLP)的技术。
RAG的目的是通过从外部知识库检索相关信息来辅助大语言模型生成更准确、更丰富的文本内容。那我们如何理解RAG的检索、增强和生成呢?
- 检索:检索是RAG流程的第一步,从预先建立的知识库中检索与问题相关的信息。这一步的目的是为后续的生成过程提供有用的上下文信息和知识支撑。
- 增强:RAG中增强是将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。通过增强步骤,LLM模型能够充分利用外部知识库中的信息。
- 生成:生成是RAG流程的最后一步。这一步的目的是结合LLM生成符合用户需求的回答。生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成文本内容。
RAG的“检索、增强、生成”,谁增强了谁,谁生成了答案,主语很重要。是从知识库中检索到的问答对,增强了LLM的提示词(prompt),LLM拿着增强后的Prompt生成了问题答案。
如何使用RAG?
我们如何使用RAG?接下来以RAG搭建知识问答系统具体步骤为例,来讲解如何使用RAG?
- 数据准备与知识库构建:
- 收集数据: 首先,需要收集与问答系统相关的各种数据,这些数据可以来自文档、网页、数据库等多种来源。
- 数据清洗: 对收集到的数据进行清洗,去除噪声、重复项和无关信息,确保数据的质量和准确性。
- 知识库构建: 将清洗后的数据构建成知识库。这通常包括将文本分割成较小的片段(chunks),使用文本嵌入模型(如GLM)将这些片段转换成向量,并将这些向量存储在向量数据库(如FAISS、Milvus等)中。
- 检索模块设计:
- 问题向量化: 当用户输入查询问题时,使用相同的文本嵌入模型将问题转换成向量。
- 相似度检索: 在向量数据库中检索与问题向量最相似的知识库片段(chunks)。这通常通过计算向量之间的相似度(如余弦相似度)来实现。
- 结果排序: 根据相似度得分对检索到的结果进行排序,选择最相关的片段作为后续生成的输入。
- 生成模块设计:
- 上下文融合:将检索到的相关片段与原始问题合并,形成更丰富的上下文信息。
- 大语言模型生成:使用大语言模型(如GLM)基于上述上下文信息生成回答。大语言模型会学习如何根据检索到的信息来生成准确、有用的回答。
大家可以结合自己的业务领域知识,开始搭建医疗、法律、产品知识问答。先搭建Demo,然后工作中不断完善知识库问答对。
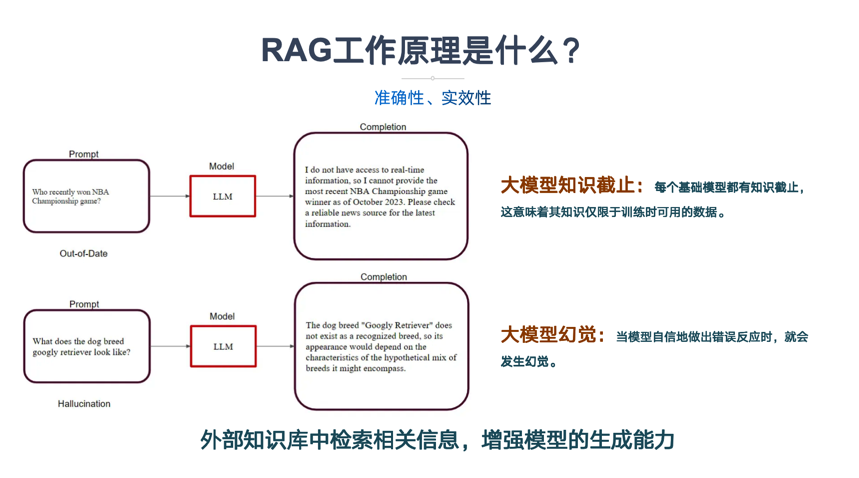
1.3 RAG工作原理是什么?
大型语言模型(LLM)面临两个问题,第一个问题是LLM会产生幻觉,第二个是LLM的知识中断。
- 幻觉:当模型所训练的数据没有问题的答案时,它会自信地做出错误反应,就会发生幻觉。
- 知识截止:当 LLM 返回的信息与模型的训练数据相比过时时。每个基础模型都有知识截止,这意味着其知识仅限于训练时可用的数据。
检索增强生成 (RAG) 摆脱了知识限制,整合了外部数据,从外部知识库中检索相关信息,增强模型的生成能力。
1.4 RAG基本搭建流程
通过检索增强技术,将用户查询与索引知识融合,利用大语言模型生成准确回答。
- 知识准备:收集并转换知识文档为文本数据,进行预处理和索引。
- 嵌入与索引:使用嵌入模型将文本转换为向量,并存储在向量数据库中。
- 查询检索:用户查询转换为向量,从数据库中检索相关知识。
- 提示增强:结合检索结果构建增强提示模版。
- 生成回答:大语言模型根据增强模版生成准确回答。
1.5 RAG技术架构
RAG技术架构主要由两个核心模块组成,检索模块(Retriever)和生成模块(Generator)。
- 检索模块(Retriever):
- 文本嵌入:使用预训练的文本嵌入模型(如GLM)将查询和文档转换成向量表示,以便在向量空间中进行相似度计算。
- 向量搜索:利用高效的向量搜索技术(如FAISS、Milvus等向量数据库)在向量空间中检索与查询向量最相似的文档或段落。
- 双塔模型:检索模块常采用双塔模型(Dual-Encoder)进行高效的向量化检索。双塔模型由两个独立的编码器组成,一个用于编码查询,另一个用于编码文档。这两个编码器将查询和文档映射到相同的向量空间中,以便进行相似度计算。
- 生成模块(Generator):
- 强大的生成模型:生成模块通常使用在大规模数据上预训练的生成模型(如GLM),这些模型在生成自然语言文本方面表现出色。
- 上下文融合:生成模块将检索到的相关文档与原始查询合并,形成更丰富的上下文信息,作为生成模型的输入。
- 生成过程:生成模型根据输入的上下文信息,生成连贯、准确且信息丰富的回答或文本。
结合高效的检索模块(Retriever)与强大的生成模型(Generator),实现基于外部知识增强的自然语言生成能力。
二、RAG的工作原理和基本搭建流程
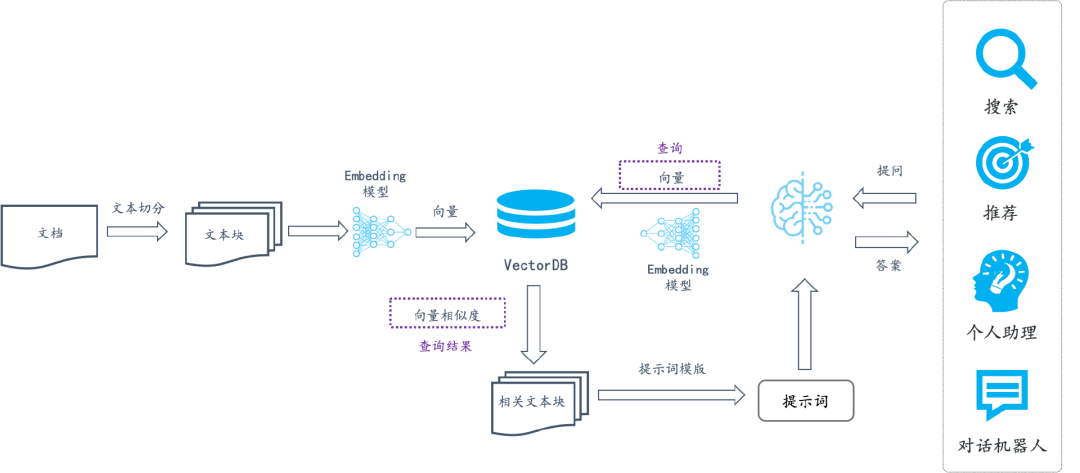
RAG搭建过程
- 1.文档加载,并按一定条件切割成片
- 2.将切割的文本片段灌人检索引擎
- 3.封装检索接口
- 4.构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
2.1 文档的加载与切割
安装 pdf 解析库
pip install pdfminer.six
构建文档提取文字方法
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
调用方法加载本地文档
paragraphs = extract_text_from_pdf("llama2.pdf", min_line_length=10)
# 打印文档前4段内容
for para in paragraphs[:4]:
print(para+"\n")
2.2 LLM接口封装
安装openai库和环境变量库
pip install --upgrade openai
pip install -U python-dotenv
加载环境变量,将我们的OpenAI Key 加载进来,在根目录建一个 .env 文件,把我们申请的OPENAI_API_KEY 填写进去,文件内容如下:
OPENAI_API_KEY=Bearer hk-xxxxxxxxxxxxxxx
OPENAI_BASE_URL=https://api.openai-hk.com/v1
编写代码加载环境变量
import os
from openai import OpenAI
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv(), verbose=True) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://api.openai-hk.com/v1", ) # 使用香港的 API 服务器
安装requests包
pip install requests
封装 openai 接口
def get_completion(prompt, model="gpt-4o"):
'''封装 openai 接口'''
messages = [{
"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7, # 控制输出的随机性,0.0-1.0之间,越小越确定
)
return response.choices[0].message.content
2.3 Prompt 模板
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
inputs = {
}
for k, v in kwargs.items():
if isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n\n'.join(v)
else:
val = v
inputs[k] = val
return prompt_template.format(**inputs)
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息,回答用户的问题。
已知信息:
{context} # 从向量数据库检索出原始文档
用户问:
{query} # 用户的提问
如果已知信息中不包含用户问题的答案,或者已知信息不足以回答用户问题,请回答“我无法回答您的问题”。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""
三、向量检索
3.1 什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 ( x , y ) (x,y) (x,y), 表示从原点 ( 0 , 0 ) (0,0) (0,0) 到点 ( x , y ) (x,y) (x,y) 的有向线段。

以此类推,我可以用一组坐标 ( x 0 , x 1 , … , x N − 1 ) (x_0, x_1, \ldots, x_{N-1}) (x0,x1,…,xN−1) 表示一个 N N N 维空间中的向量, N N N 叫向量的维度。
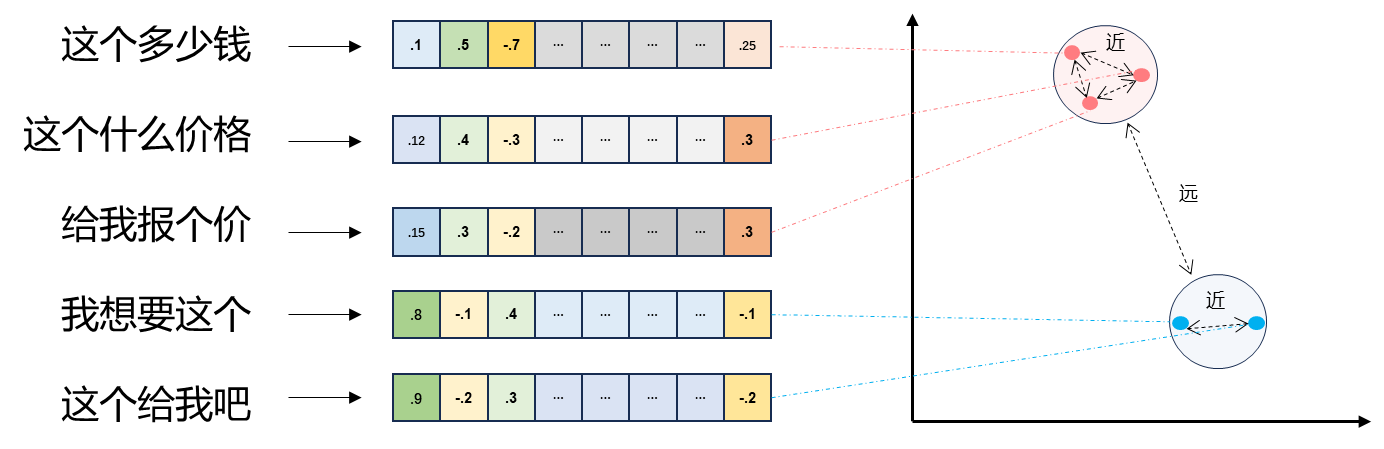
3.1.1 文本向量(Text Embeddings)
- 将文本转换成一组 N N N 维浮点数,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
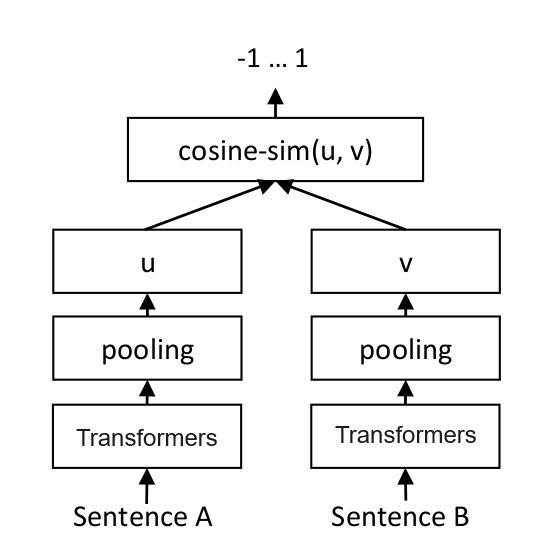
3.1.2 文本向量是怎样得到的
- 构建相关(正例)与不相关(负例)的句子对样本
- 训练双塔模型,让正例间的距离小,负例间的距离大
例如:
3.2 向量间的相似度计算
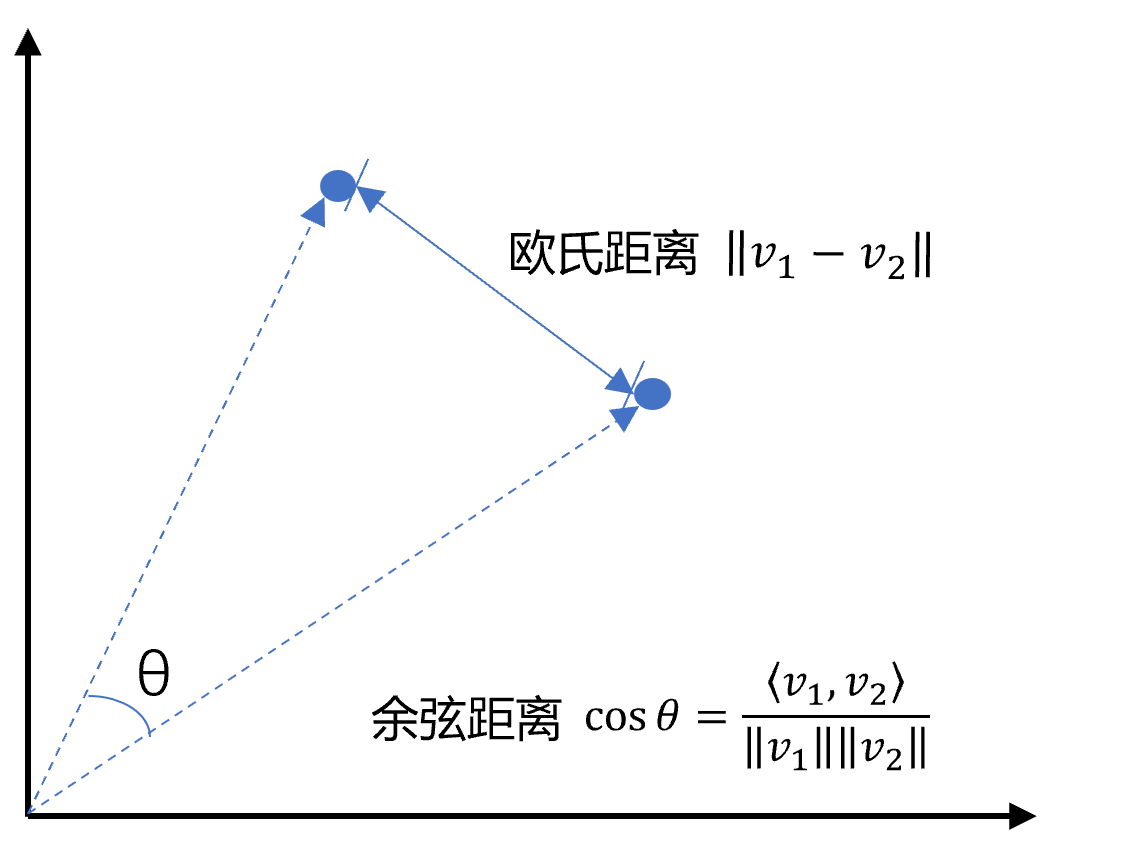
向量间的相似度计算在数学上有欧氏距离和余弦距离两种。
安装numpy库
pip install numpy
构建相似度计算公式:
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
封装 openai 的 Embeddings 模型接口
def get_embeddings(texts, model="text-embedding-ada-002", dimensions=None):
'''封装 OpenAI 的 Embedding 模型接口'''
if model == "text-embedding-ada-002":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
大多数场景下,开源的嵌入模型使用都很一般,要提升检索召回率,建议对模型进行微调。
进行测试
test_query = ["测试文本"]
vec = get_embeddings(test_query)[0]
print(f"Total dimension: {
len(vec)}")
print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









