






在NLP任务中,需要将自然语言交给计算机来处理,但是计算机无法直接理解人类的语言,所以首先要将语言数字化。词向量提供了一种很好的将语言数字化的方法。
一种最简单的词向量表示方法是onehot representation,即onehot编码。但是这种词向量的表示有一定的缺点,如维数灾难,无法表示词之间的相似性。
另一种词向量是Distributed Representation,其基本思想是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量。所有这些向量构成词向量空间,而每一向量则可视为该空间中的一个点,可以根据两个向量的距离来判断它们之间的相似性。word2vec就是一种Distributed Representation。
word2vec模型是由Mikolov于2013年提出的。由word2vec模型学习的单词向量已经被证明具有语义的意义,并且在各种NLP任务中都很有用。当提到word2vec算法或模型的时候,指的是其背后用于计算word vector的CBoW模型和Skip-gram模型,它们只是浅层神经网络,并不是深度学习算法。
本文主要介绍原始的continuous bag-of-word(CBOW)和skip-gram(SG)模型,同时介绍了对以上两种模型训练的优化算法,包括hierarchical softmax和negative sampling。
Continuous Bag-of-Word Model(CBoW)
One-word context
首先考虑最简单的情况,上下文只有一个词,即给定上下文中的一个词,来预测目标词汇。图1展示了只考虑上下文只含有一个词的神经网络模型。
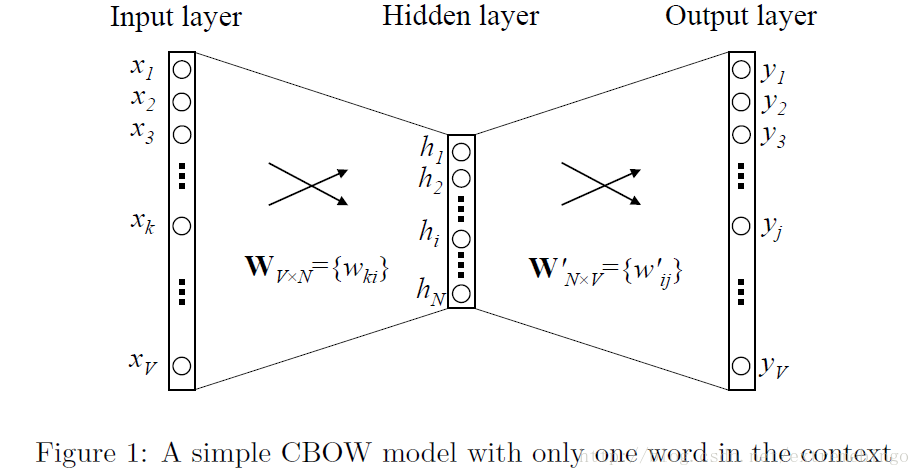
假设词汇量大小为
V
,则输入层和输出层的神经元个数都为
输入层与隐含层之间的权重矩阵为
WV×N={wki}
,用
vw
表示输入的那个词与隐含层连接的权重,因此
vw
为
W
矩阵的其中一个行向量。若输入一个词,假设
本质上就是将
W
的第
隐含层与输出层之间的权重矩阵为 W′N×V={w′ij} ,对于词典里的每一个词,定义一个score uj ,即输出层的输入值
其中, v′wj 是 W′ 的第 j 列。
通过softmax来得到输入词的后验分布,即
其中 yj 为输出层第 j 个神经元的输出。
将式(1)和式(2)代入(3)式可得
vw
和
v′w
是词
w
的两种表示。
vw :输入向量。
v′w :输出向量。
一般可以选取任意一个作为词向量。
简单分析一下模型的计算量,由于输入层是onehot编码的,所以输入层与隐含层之间的计算量并不大。整个模型的大部分计算量都集中在隐藏层和输出层之间的计算,以及输出层的softmax运算。因此,后续将有对这一部分优化的描述。
更新隐含层和输出层之间的权重 W′
对于一个样本,训练的目标是使得(4)式最大,即最大化期望输出的条件概率( j∗ 为输出层期望输出的词的index值)
其中(6)式由(5)式代入(3)得到。
令损失函数为
因此,问题转化为了最小化损失函数 E 。
对(8)式中的
其中,当 j=j∗ 时, tj=1 ,否则 tj=0 。
对 w′ij 求导,得到隐藏层和输出层之间权重的梯度
其中 hi 为隐藏层第 i 个神经元的输出。
所以,通过采用随机梯度下降法,可以得到以下的参数更新方式
或
其中 η>0 为学习率。
注:按照上面的权重更新方式,必须计算词典中每一个词的概率 yj ,然后比较 yj 和 tj 的大小关系。
更新输入层和隐含层之间的权重 W
求
由(1)式可得
等价于张量积
∂E∂W 中只有一行是非零的,其它的行都为零。
参数更新的方式为
vwI 是唯一的偏导数不为0的行,其它行的偏导数都为0,参数值保持不变,不进行更新操作。
Multi-word context(CBoW)
如下图所示的CBoW模型,上下文存在多个词。注:输入层与隐含层之间的
C
个权值
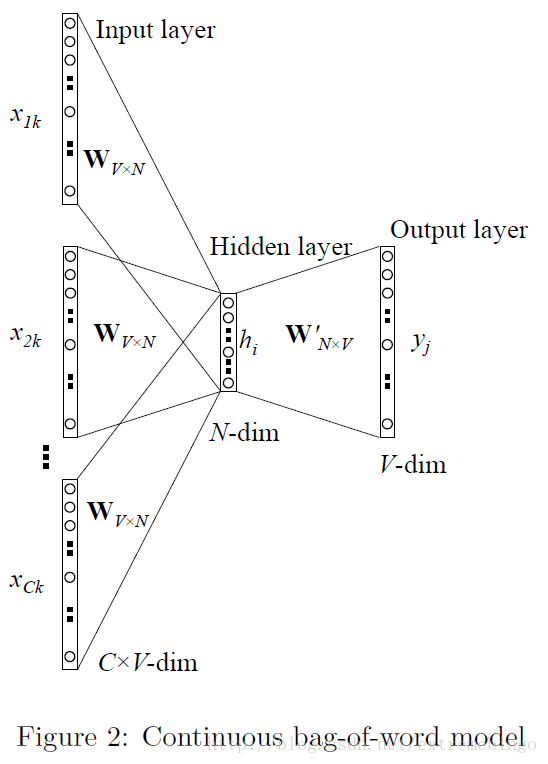
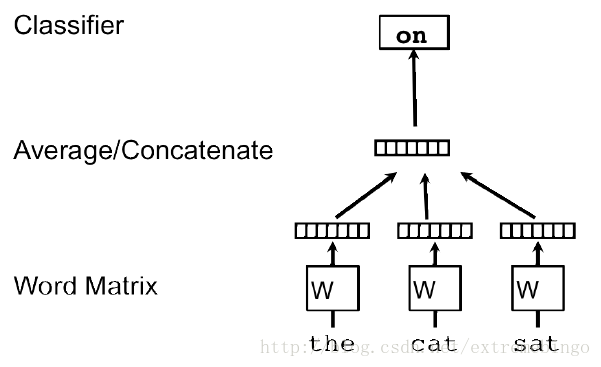
如上图所示,给定上下文”the”, “cat”, “sat”,来预测第四个词”on”。输入的词各自映射为矩阵 W 的一行。
当只考虑上下文只有一个词的情况时,是直接采用的输入向量。CBoW是将输入的上下文的向量取平均值来作为隐含层的输出,即
C 是上下文中词的数量。
损失函数
隐含层与输出层之前参数的更新
对于每一个训练样本,需要将(20)式的参数更新应用于隐含层和输出层之间的每一个元素。
输入层与隐含层之间参数的更新
Skip-Gram Model
Skip-Gram Model正好跟CBoW模型相反,如图3所示。目标词现在在输入层,上下文的词在输出层。和CBoW类似,Skip-Gram的输出层权值共享,因此,也和图1类似,只是图1中输出层只有一个元素为1,而这里存在 C 个为1的元素。
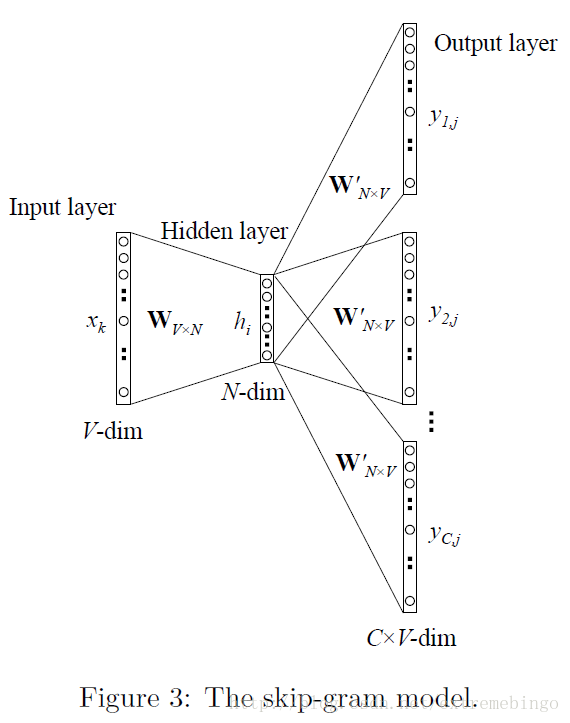
同样使用
对于输出层的输出,不再只输出一个多项式分布,现在总共有 C 个多项式分布的输出
其中
wc,j
为输出层的第
c
个多项式分布的第
其中,
v′wj
词典中第
j
个词
参数的更新与上下文只有一个词的情况类似,即
其中, uj∗c 为期望的第 c 个上下文词在词典中的index。
对输出层的输入求偏导
定义一个
V
维的向量
对隐含层和输出层之间的权重 W′ 求偏导
因此, W′ 的参数更新为
或
参数 W 的更新为
其中 EH 为 V 维向量
Optimizing Computational Efficiency
对于上文所描述的模型,每个词都能有两种向量表示,输入向量 vw 和输出向量 v′w 。其中,输入向量的学习是容易的,而输出向量的学习是困难的,因为为了更新 v′w ,需要对词典中的每一个词都计算输出层的输入 uj ,输出层的输出 yj ,以及预测误差 ej 。当词汇量很大,或者样本数很多的时候,这种计算方式是不可行的。下面的两种方法,都针对一个样本,通过限制输出向量的个数来减小计算量。
Hierarchical Softmax
Hierarchical Softmax是一种高效的计算softmax的方式。它采用二叉树来表示词典中的词,如下图所示。
V
个词是树的叶子节点,
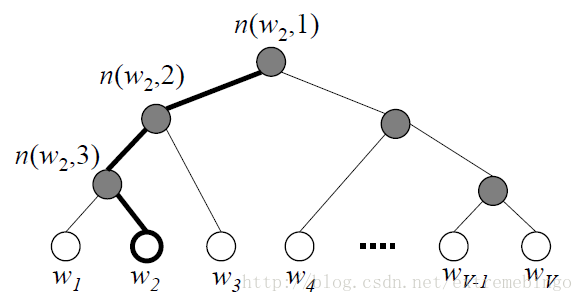
如上图所示,黑色的线表示从根节点啊到达词
w2
的路径,路径的长度
L(w2)=4
,
n(w,j)
表示从根节点到达词
w
的路径上的第
在Hierarchical Softmax模型中,没有针对词的输出向量,但是, V−1 个内部节点都有一个输出向量 v′n(w,j) 。
定义某个词作为输出词的概率为
其中,
ch(n)
为
n
单元的做孩子,
在上图中,计算 w2 为输出词的概率。在每个内部节点,行走的路径是随机的(往左和往右存在一定的概率)。定义,在内部节点 n ,向左走的概率为
因此,往右走的概率为
所以,在上图中, w2 为输出词的概率为
现在来看内部节点的向量表示是如何更新的。首先考虑只有一个词的上下文。为了方便,对公式作适当的简写
对于每个训练样本,其损失函数为
对损失函数
E
求关于
然后,对损失函数
E
求关于
因此,更新方程为
可以将 σ(v′jTh)−tj 理解为内部节点 n(w,j) 的预测误差。每个内部节点的任务是预测往左孩子走还是右孩子走。 tj=1 表示往左, tj=0 表示往右。 σ(v′jTh) 表示预测结果。对于一个训练样本,如果预测结果和真实值很接近,则 v′j 的变化会很小,否则, v′j 会变化一个合适的大小来达到更小的预测误差。
式(42)同样可以用来更新CBoW和skip-gram的参数。
为了学习输入层和隐含层的权重,求
E
关于隐含层输出
因此,可以用CBoW和skip-gram的更新方式来更新权重。
从更新的方程可以看出,每个训练样本的计算复杂度从 O(V) 降到了 O(log(V)) ,这可以极大地改善训练的速度。
Negative Sampling
前文曾经提到过,必须计算词典中所有词的输出向量,这给计算量带来了极大的负担。为了解决这个问题,现在只计算部分的输出向量。
期望输出的那个词必须在取样的样本中,然后再选取部分词作为负样本。
后续的计算过程与Hierarchical Softmax类似,这里不再赘述。
参考文献
[1] Rong X. word2vec Parameter Learning Explained[J]. Computer Science, 2014.
[2] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.














 1759
1759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









