







前提
默认对Anaconda安装成功,不需要安装Cuda等和GPU相关的任何包,因为在虚拟环境中有相应的方法进行安装。故,本教程只需要在电脑中安装Anaconda即可。
电脑配置:
本文是在ubuntu18.04+3080环境下实现。
Nerf数据集下载
原文中提供了bash的下载方法,其对大多用户不可用,同时速度较慢,采用网盘下载。网盘链接

如果只是用Nerf的话可以下载llff_data。如果用mipnerf则下载synthetic,synthetic是有相机参数的文件夹。
下载成功后将数据集放在MipNerf文件夹中的Data文件夹下即可。
MipNerf的运行和使用
MipNerf文章地址:MipNerf
MipNerf的GitHub地址:代码地址
但由于MipNerf的原版安装有很多问题,后来根据其他资料换成了另一个地址:新代码地址,后续也是按照新代码进行环境配置和更改。
环境安装
MipNerf中已经详细介绍了环境安装的教程,但是在一步一步使用之后,发现会出现如下错误:

这表明系统上安装的 NVIDIA 驱动程序版本较老,与当前的 PyTorch 版本不兼容。而服务器的NVIDA我又没办法自己升级,因此考虑降低PyTorch版本。
使用指令:
nvcc -V
查看CUDA版本是11.4:
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2021 NVIDIA Corporation
Built on Mon_Oct_11_21:27:02_PDT_2021
Cuda compilation tools, release 11.4, V11.4.152
Build cuda_11.4.r11.4/compiler.30521435_0
在官网中查看pytorch_lightning1.5对应的pytorch应该≥1.7, ≤1.10,如下:

因此,安装相应的Pytorch

因此需要更改指令为如下方式:
conda create -n mipnerf -y python=3.8
conda activate mipnerf
python -m pip install --upgrade pip
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
安装成功后运行指令:
python train.py --out_dir out_fox --data_path ./data/ima --dataset_name blender exp_name exp
可以看到,在GPU地方已经变为True,表明环境可以正确调用GPU进行训练。

到此,环境正确安装。
问题一
安装成功后,运行过程发生如下错误:
AttributeError: module ‘PIL.Image’ has no attribute ‘ANTIALIAS’
这是因为在高版本的Pillow中移除了ANTIALIAS,查看Pillow的版本,如果大于10则手动降低:
pip install Pillow==9.5.0
重新运行训练程序,可以工作。
问题二
RuntimeError: CUDA out of memory. Tried to allocate 384.00 MiB (GPU 0; 11.77 GiB total capacity; 7.96 GiB already allocated; 163.31 MiB free; 8.03 GiB reserved in total by PyTorch)
这是因为GPU内存不足,3080的内存只有12GB,而一次MipNerf的训练可以达到20-30GB,故会出现此问题。修改./configs/lego.yaml代码:
seed: 4
num_gpus: 1
exp_name: 'lego'
train:
batch_size: 1024
batch_type: 'all_images' # single_image: inputs a full image; all_images: inputs batch_size rays sampled from different image
num_work: 4
randomized: True
white_bkgd: True
val:
batch_size: 1
batch_type: 'single_image' # For "single_image", the batch must set to 1
num_work: 4
randomized: False
white_bkgd: True
check_interval: 10000
chunk_size: 8192 # The amount of input rays in a forward propagation
sample_num: 4 # Total number of images verified during once validation
问题三
ValueError:
val_check_interval(10000) must be less than or equal to the number of the training batches (2083). If you want to disable validation setlimit_val_batchesto 0.0 instead.
这是验证集上进行的间隔检查超出了训练批次的数量,修改train.py的代码。
seed: 4
num_gpus: 1
exp_name: 'lego'
train:
batch_size: 1024
batch_type: 'all_images' # single_image: inputs a full image; all_images: inputs batch_size rays sampled from different image
num_work: 4
randomized: True
white_bkgd: True
val:
batch_size: 1
batch_type: 'single_image' # For "single_image", the batch must set to 1
num_work: 4
randomized: False
white_bkgd: True
check_interval: 2000
chunk_size: 8192 # The amount of input rays in a forward propagation
sample_num: 4 # Total number of images verified during once validation

然后可以正常运行,到这里解决了内存不足等问题。(但是有四块3080,似乎应该是可以跑满源代码的,不知道为什么一直提示第一块内存不足,这里还有问题需改进。)
发现了问题所在,在config/lego.yaml文件中,有一段num_gpus:
1,这个决定了最大使用的GPU,因此,我只需要把这里的1改为服务器中最大GPU数目,即可完成多GPU的调用。(注意,这里的修改只对train.py有用)。
问题四
pip安装后conda list 没有包。
先查看pip的路径:
which pip
/home/XXX/.local/bin/pip
显然,这个是全局pip,我们要做的是将包安装到虚拟环境中,这个pip安装到了base下面,有一个简单的方法是使用如下指令:
python -m pip install name_bao
就可以安装在虚拟环境中,具体修改pip的默认路径方法后续更新。
使用自己的数据集
本章大量使用博主《三维小菜鸡》的文章:nerf训练自己的数据,过程记录十分详细
具体过程可以参考该文章,本文只对其中报错部分进行相关的完善。
获得JSON文件
从网上下载COLMAP安装包即可,下载链接。
下载后安装即可,第二步需要下载instant_ngp的源码文件,这里的作用是产生MipNerf需要的json文件,博主发现ngp有一个函数提供了从COLMAP得到json文件的方法,自此说明。
instant-ngp源码,下载成功后,在终端中输入以下指令:
conda create -n ngp -y python=3.9
conda activate ngp
python =m pip install --upgrade pip
pip install -r requirements.txt
配置好ngp的环境后需要使用函数colmap2nerf.py,这个函数可以直接传入视频,也可以传入图片进行生成json文件。
python scripts/colmap2nerf.py --colmap_matcher exhaustive --run_colmap --aabb_scale 16 --images [图片路径]
最后在文件夹中会发现一个transforms.json文件,该文件就是数据集的相机文件。
MipNerf修改部分
再MipNerf的代码中,需要修改两个地方,一个是train.py需要使用的,一个是render_video.py需要的。
train.py
train的命令为:
python train.py --out_dir OUT_DIR --data_path UZIP_DATA_DIR --dataset_name blender exp_name EXP_NAME
在train.py函数中,会调用./configs/XXX.yaml文件,这个文件对train的GPU使用数目,训练轮次,batchsize进行了规定,为了更快地训练结束,我调整了格式如下:

修改此文件即可,其余部分不用修改。
render_video.py
render文件原来设定使用一个GPU,我修改让其使用多GPU训练,run_render函数代码如下:
def run_render(args):
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = MipNeRFSystem.load_from_checkpoint(args.ckpt).to(device).eval()
# 使用DataParallel包装模型以在四个GPU上运行
if torch.cuda.device_count() > 1:
print("Using", torch.cuda.device_count(), "GPUs!")
model = torch.nn.DataParallel(model, device_ids=[3, 4])
# Access hparams through the underlying model
if isinstance(model, torch.nn.DataParallel):
underlying_model = model.module
hparams = underlying_model.hparams
else:
hparams = model.hparams
exp_name = hparams['exp_name']
除此之外,需要修改相机参数camera_angle_x,这个值来自于json文件中的camera_angle_x。
parser.add_argument('--camera_angle_x', help='camera_angle_x in source dataset',
type=float, default=0.9156173236398449)
json文件格式如下:
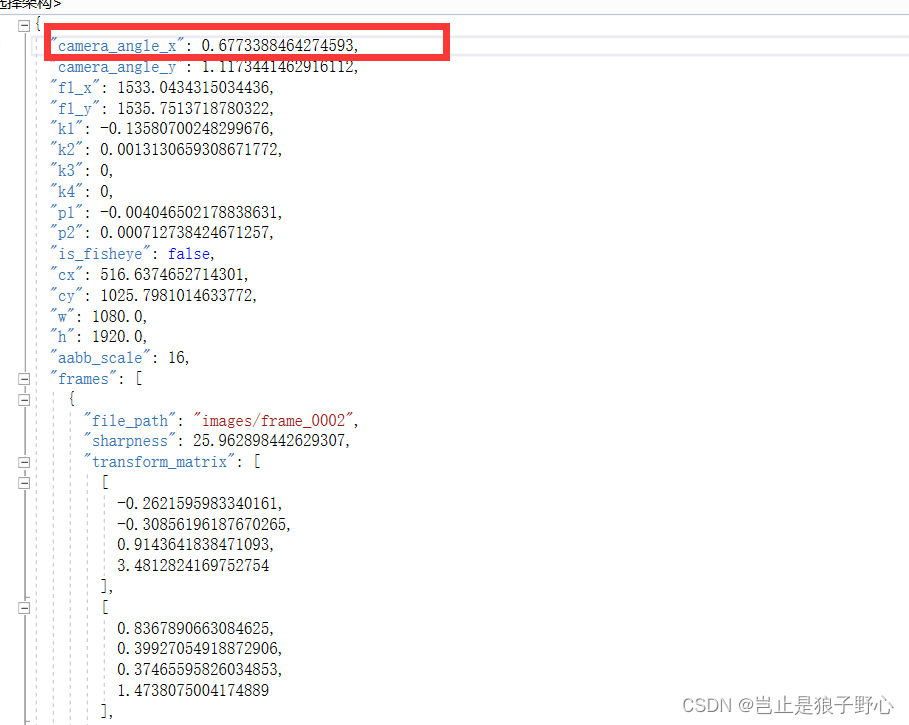
最终,运行函数就可以生成视频文件,mov文件需要转换为mp4才可以在windows下播放。
python render_video.py --ckpt OUT/ckpt/exp/epoch=0-step=9999.ckpt --out_dir OUT_vidio --scale 4
















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











