







1、RL和ML和DL之间的关系
2、马尔卡夫
马尔卡夫性:
系统的下一个状态St+1仅与当前状态St相关
定义:状态st 是马尔科夫的,当且仅当P[st+1 |st ]=P[st+1 |s1 ,…,st]。定义中可以看到,当前状态st 其实是蕴含了所有相关的历史信息s1 ,…,st ,一旦当前状态已知,历史信息将会被抛弃。【这样定义马尔卡夫性有什么意义呢?】
马尔科夫性描述的是每个状态的性质,但真正有用的是如何描述一个状态序列。数学中用来描述随机变量序列的学科叫随机过程。所谓随机过程就是指随机变量序列。若随机变量序列中的每个状态都是马尔科夫的,则称此随机过程为马尔科夫随机过程。
马尔卡夫过程:
定义:马尔科夫过程是一个二元(S,P),且满足,S代表有限状态集合,P是状态转移概率,状态转移概率矩阵为
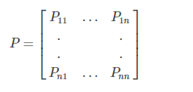
对于这个例子,假设下面这个表格填写上数字,这个table就是马尔卡夫过程。
等价于下面这个图:
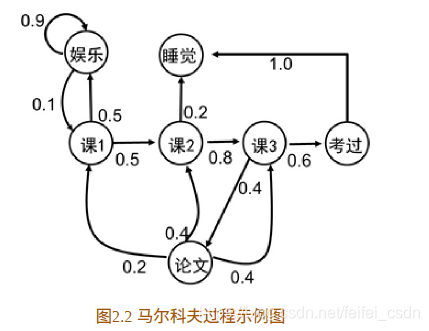
马尔卡夫链:一条状态序列就被称为一条马尔卡夫链。
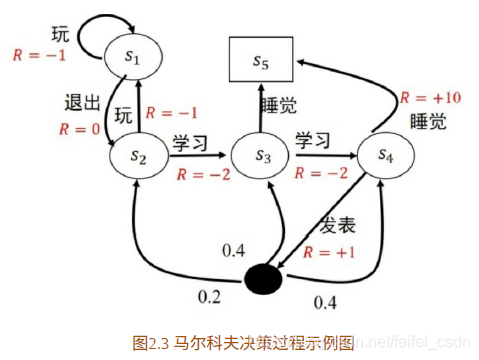
马尔卡夫决策:
在马尔卡夫过程中加上reward和action就是马尔卡夫决策,简称MDP。马尔卡夫决策过程由元祖(S,A,P,R,γ)也就是元祖里面多了几个元素。
S:有限状态集合
A:有限动作集合
P:状态转移概率 :包含动作
![]()
马尔卡夫过程的p
![]()
R:回报函数
γ: 折扣因子,是在计算累计期望回报的时候使用的一个参数
策略:
策略是动作到状态的映射,策略常⽤符号π表⽰,它是指给定状态s时,动作集上的一个分布![]()
强化学习的策略往往是随机策略。采用随机策略的好处是可以将探索耦合到采样的过程中。
给定策略是指在一个state选择每个action的概率是确定的,强化学习的策略一般包含【本博客后面的内容】
2.1的公式属于是随机策略,确定性策略的表示如下:
a=π(s)
累积回报
累积回报是一个序列通过如下公式计算的累积回报值。
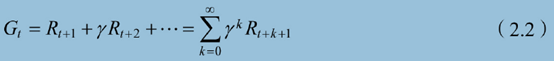
给定策略【确定的或者是随机的】之后,累积回报具有多个值,而且现在策略经常是随机的,所以累积回报也是随机的。如果我们要评价S1的价值
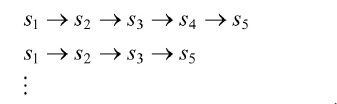
使用累积回报Gt是无法评估的,但是Gt的期望确是固定的。
值函数
值函数分为状态值函数+状态行为值函数
状态值函数
当智能体采用策略π时,累积回报服从一个分布,累积回报在状态s处的期望值定义为状态-值函数
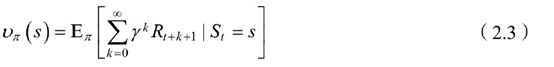
注意:状态值函数是与策略π相对应的,这是因为策略π决定了累积回报G的状态分布
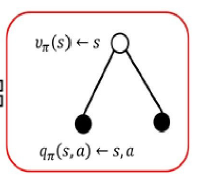
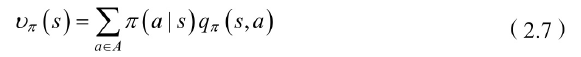
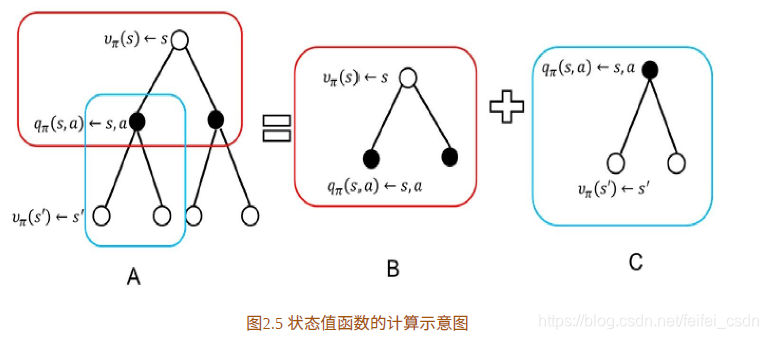
状态值函数为状态行为值函数的和
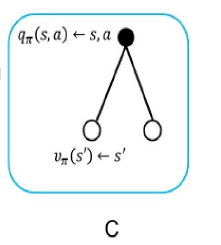
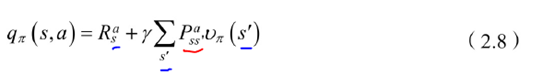
状态-行为值函数为当前状态的reward+r*sum(上一个状态:(状态转移概率×状态值函数))
带入得到公式:
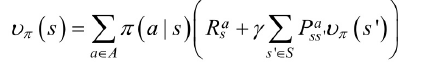
状态行为值函数
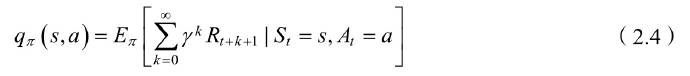

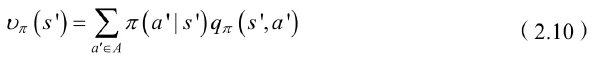
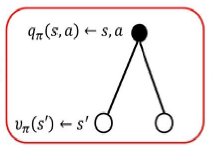
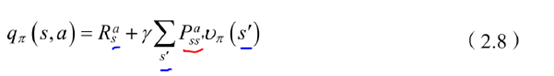
合并得到:
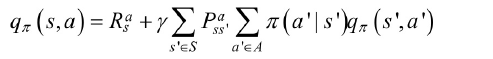
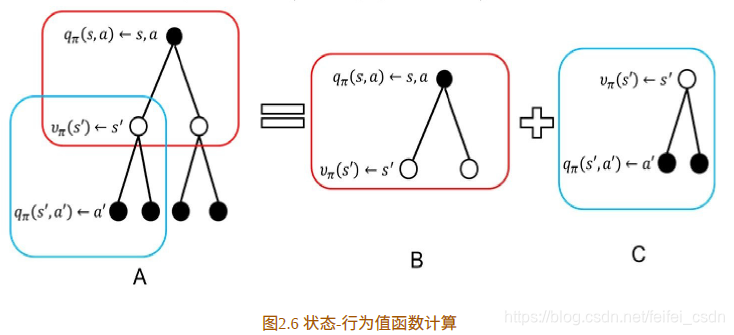
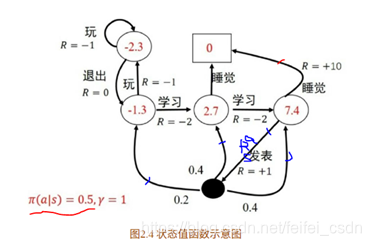
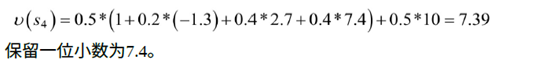
状态值函数和状态行为值函数的贝尔曼方程
状态值函数的贝尔曼方程
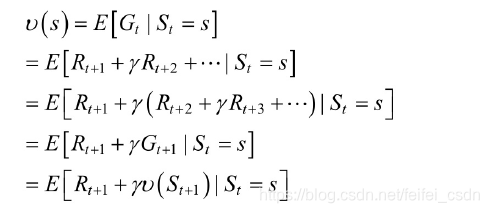
最后一个等式证明【没看懂】
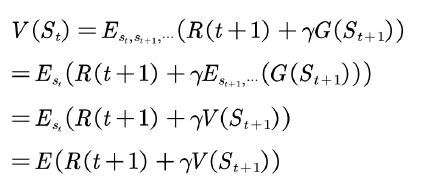
这里需要注意的是对哪些变量求期望。
状态行为值函数的贝尔曼方程
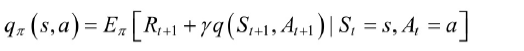
值函数和最优策略
从最开始引入值函数的概念入手,值函数是用来评估S1的价值,假设我们每一点都选择最具有价值的action来走的话,那最后的就是最优的policy
最优状态值函数υ* (s) 为在所有策略中值最大的值函数

最优状态-⾏为值函数q* (s,a)为在所有策略中最⼤的状态-⾏为值函数

最优状态值函数和最优状态-动值函数的⻉尔曼最优⽅程:

若已知最优状态-动作值函数,最优策略可通过直接最大化q* (s,a)来决定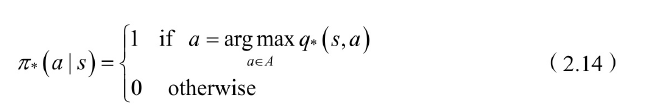
3、RL和MDP之间的关系
应该说MDP是最简单的强化学习的数学模型,因为他本身做了很多限制
- 面对的state,数量是有限的
- 采取的action,数量也是有限的
- 对于特定的state,当下的reward是明确的
- 在某一时刻,采取行动at,st切换至st+1,st+1有多种可能,
就是指st+1不确定,state转换概率![]() 状态转换只依赖当前状态和先前的状态无关
状态转换只依赖当前状态和先前的状态无关
对马尔卡夫过程的各种限制,不断放松,研究相应的算法,就是RL的目标
Eg:
- st数量有限,但是十分巨大,如何降低DP的运算成本
- st数量无线,DP失效,如何改进算法
- st不能被完全观察,只能被部分观察到,如何改进算法
- st完全不能被观察,只能通过其他现象推测其潜在的状态,如何改进算法
- st的数量是无限的,且不是离散的,是连续的值
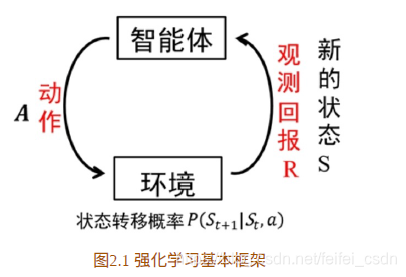
4、RL学习框架

5、RL常用的随机策略
贪婪策略

贪婪策略是⼀个确定性策略,即只有在使得动作值【动作值函数或者称他为行为值函数】函数q* (s,a)最⼤的动作处取概率1,选其他动作的概率为0
ε-greedy策略

后面的参数和 这样的意义应该是一样的,因为这里都是动作值函数
这样的意义应该是一样的,因为这里都是动作值函数
ε-greedy策略是强化学习最基本最常⽤随机策略。其含义是选取使得动作值函数最⼤的动作的概率为

其余为:

ε-greedy平衡了利⽤(exploitation)和探索(exploration),其中选取动作值函数最⼤的部分为利⽤,其他⾮最优动作仍有概率为探索部分。
高斯策略
一般高斯策略可以写成πθ=μθ+ϵ,ϵ∼N(0,σ2)πθ=μθ+ϵ,ϵ∼N(0,σ2)。其中μθμθ为确定性部分,ϵϵ为零均值的高斯随机噪声。高斯策略也平衡了利用和探索,其中利用由确定性部分完成,探索有ϵϵ完成。高斯策略在连续系统的强化学习中应用广泛。
玻尔兹曼分布
对于动作空间是离散的或者动作空间并不大的情况,可采用玻尔兹曼分布作为随机策略,即 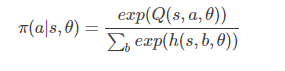
其中Q(s,a,θ)Q(s,a,θ)为动作值函数,该策略的含义是动作值函数大的动作被选中的概率大,动作值函数小的动作被选中的概率小
6、RL算法的形象化描述



















 5184
5184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









