







1、Q_learning
探索者游戏,从开始位置左右移动到终点位置,结束的时候奖励值为1,其余时刻奖励值为0
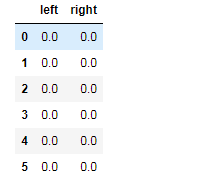
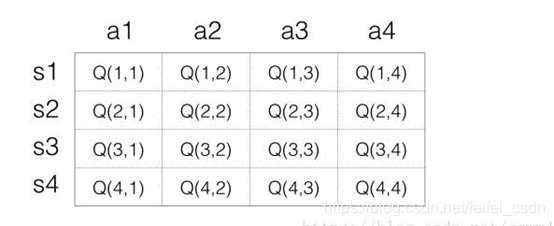
q_table/值函数矩阵
states + actions
choose action
Left或者right,how to choose action?
行动策略(action policy)是ε-greedy策略,引入的一个参数是epsilon greedy,
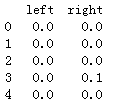
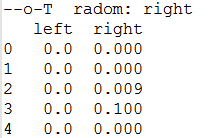
Left:0 right:0.1 此时action为right
#产生一个随机数
#print(np.random.uniform() )
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()):
action_name = np.random.choice(ACTIONS)
print("radom: "+action_name)
else: # act greedy 90%
action_name = state_actions.idxmax() 最大动作值函数/行为值函数ε-greedy 可以参考【RL入门到放弃】【一】
Reward
magbe you can saw env feedback
Rt:0/Rt:1 when r=1
Gt:0/Gt:1
When s_ is terminal R=1 otherwise R=0 including it is wall
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'right': # move right
if S == N_STATES - 2: # terminate
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else: # move left
R = 0
if S == 0:
S_ = S # reach the wall
else:
S_ = S - 1
return S_, R
fade code
arbitrarily : 随机地

Episode : 回合/幕【经验】
Q( s, a ) : 状态值函数
TD : TD差分目标
![]()
r : 立即回报
目标策略:贪婪策略
q 值更新
mdp:(S, A, P, R,γ)
N_STATES : 5
ACTIONS = [‘left’, ‘right’]
EPSILON = 0.9
ALPHA = 0.1
GAMMA = 0.9【0~1】
One episode
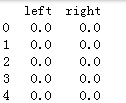

![]()
* = 0 + 0.1*[1+0.9*0 - 0] = 0.1
Two episode
* = 0 + 0.1*[0+0.9*0.1 - 0] = 0.009
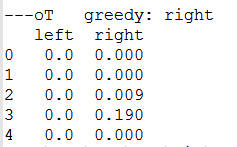
* = 0.1 + 0.1[1+0.9*0 – 0.1] = 0.19
完整code可见
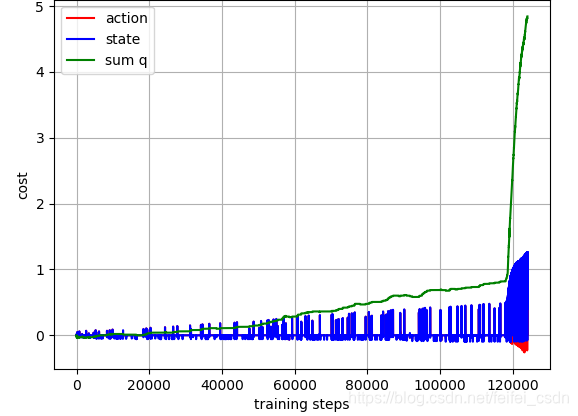
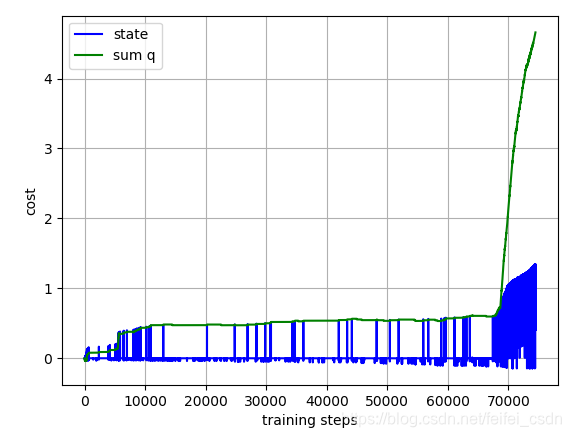
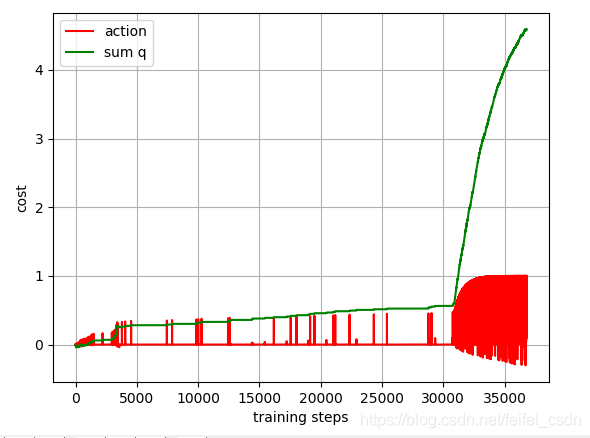
结果:
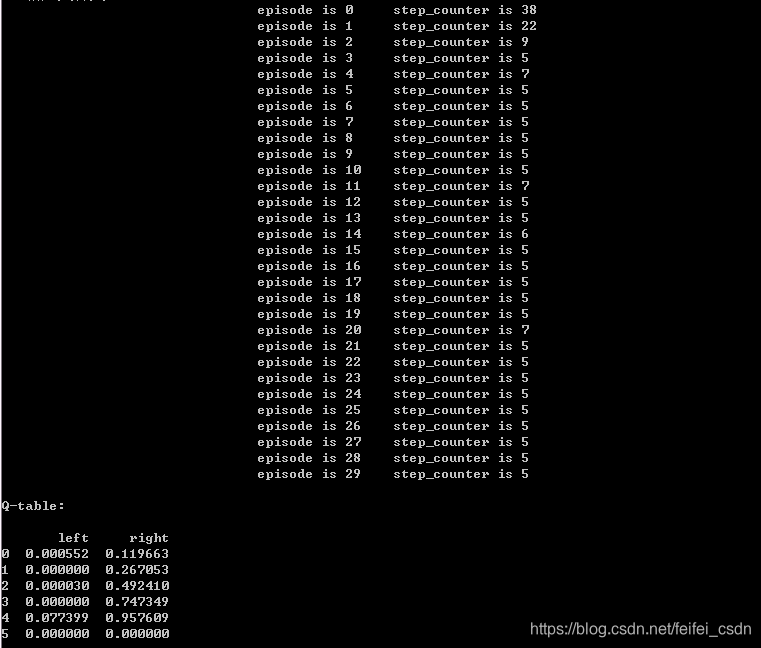
训练1000次,可以看到动作值函数是收敛的【这里可能错了,因为我是直接对所有的q值求和,应该是直接append计算的那个q值】
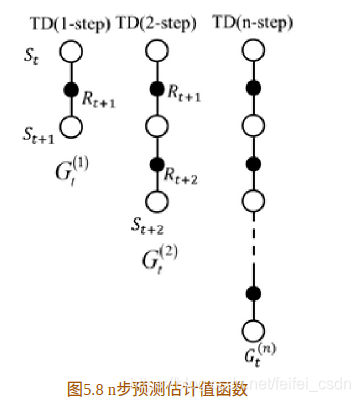
探索者游戏里面的三个图像数据如下:
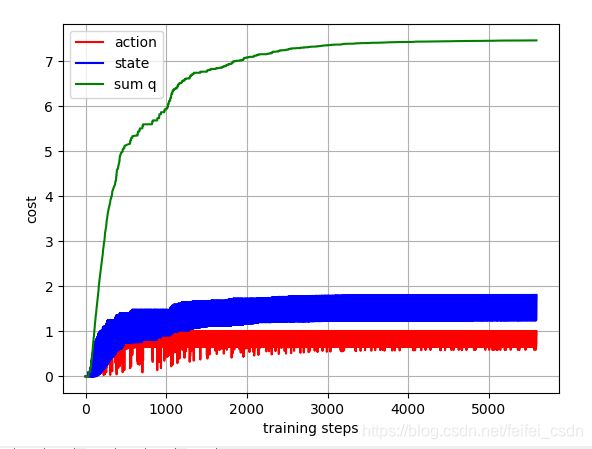
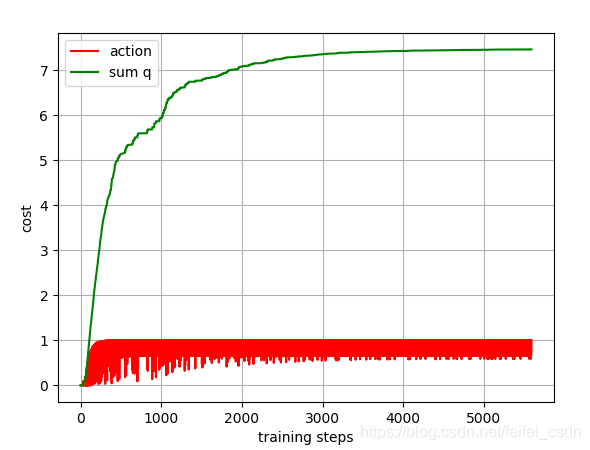
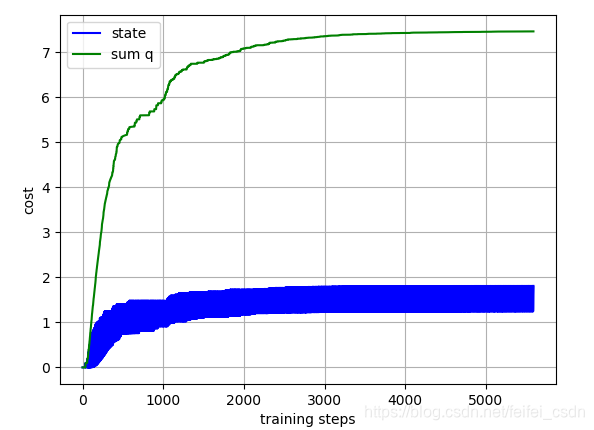
在网格一下子天堂一下子地狱的问题里面
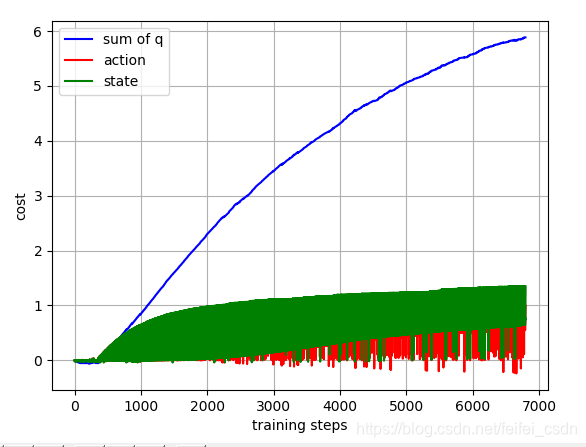
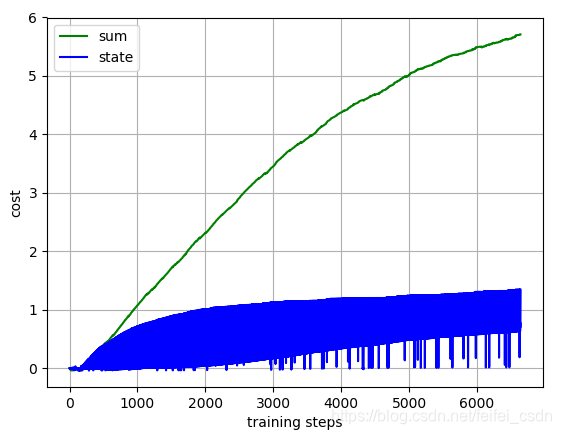

特点:异策略+时间差分
off-policy
就是指行动策略和评估策略不是同一个策略,行动策略采用了贪心的ϵ-greedy策略(第5行),
而评估策略采用了maxπQ(s,a)贪心策略(第7行)!
时间差分
上面提到的TD目标
反思
1、为什么选择q值最大的action会是最优的策略,因为q值是评价S价值的标准
2、为什么s-greedy策略,因为要顾及探索性
3、何时终止探索,给出最优的序列呢?其实后面例子看多了,也就会了。
2、sarsa

一般sarsa算法和q_learning算法需要相互比较
依旧是网格,一念天堂一念地狱的游戏
3、TD(lambda)
更新当前值函数,用到了下一个状态的值函数
![]()
利用第二步值函数来估计当前值函数可以表示为
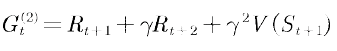
以此类推,利用第n步的值函数更新当前值函数可表示
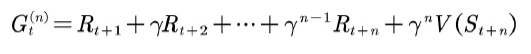
可以利用n步值函数来估计当前值函数,也就是说当前值函数有n种估计方法。
在![]() 乘上加权因子
乘上加权因子![]() 需要加权的原因如下:
需要加权的原因如下:
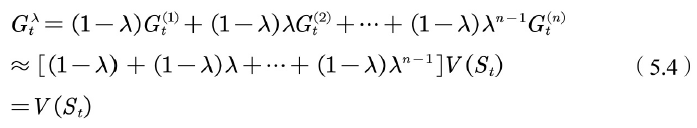
利用 ![]() 更新当前状态的值函数的方法称为
更新当前状态的值函数的方法称为 ![]() 的方法。一般可以从两个视角理解
的方法。一般可以从两个视角理解![]()
前向视角
第一个视角是前向视角,该视角也是 ![]() 的定义。
的定义。
假设一个人坐在状态流上拿着望远镜看前面,前面是将来的状态。估计当前状态的值函数时,从![]()
的定义中可以看到,它需要用将来时刻的值函数。也就是说,前向观点通过观看将来状态的值函数来估计当前的值函数
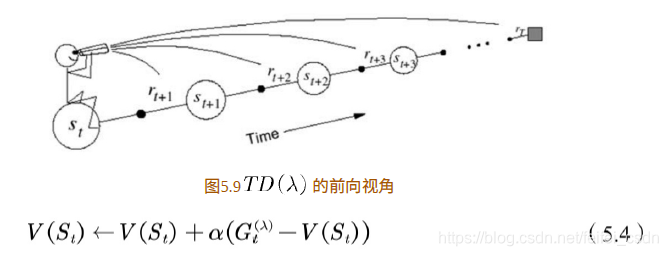
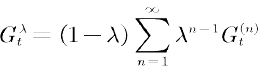
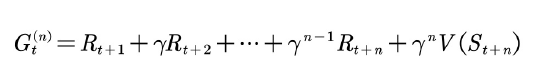
利用 ![]() 的前向观点估计值函数时,的计算用到了将来时刻的值函数,因此需要整个试验结束后才能计算,这和蒙特卡罗方法相似。是否有某种更新方法不需要等到试验结束就可以更新当前状态的值函数?有!这种增量式的更新方法需要利用
的前向观点估计值函数时,的计算用到了将来时刻的值函数,因此需要整个试验结束后才能计算,这和蒙特卡罗方法相似。是否有某种更新方法不需要等到试验结束就可以更新当前状态的值函数?有!这种增量式的更新方法需要利用![]() 的后向观点。
的后向观点。
后向视角
人骑坐在状态流上,手里拿着话筒,面朝已经经历过的状态流,获得当前回报并利用下一个状态的值函数得到TD偏差后,此人会向已经经历过的状态喊话,告诉这些状态处的值函数需要利用当前时刻的 TD偏差更新。此时过往的每个状态值函数更新的大小应该与距离当前状态的步数有关。假设当前状态为![]() ,TD偏差为
,TD偏差为![]() ,那么
,那么![]() 处的值函数更新应该乘以一个衰减因子
处的值函数更新应该乘以一个衰减因子![]() ,状态
,状态 ![]() 处的值函数更新应该乘以
处的值函数更新应该乘以![]() ,以此类推。
,以此类推。
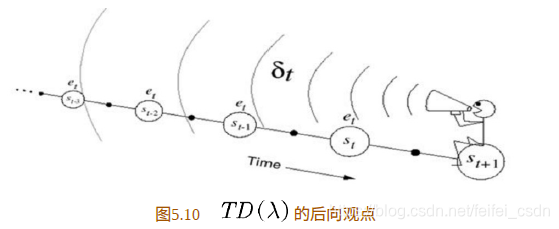
![]() 更新过程如下。
更新过程如下。
首先,计算当前状态的TD偏差
![]()
其次,更新适合度轨迹
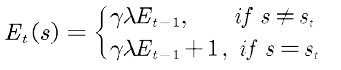
最后,对于状态空间中的每个状态s,更新值函数
![]()
前向和后向视角的异同


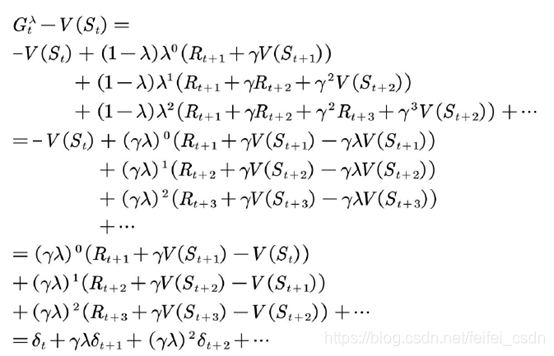
sarsa(N)的伪代码

也是网格游戏,一念天堂,一念地狱。
采用:self.eligibility_trace.loc[s, a] += 1
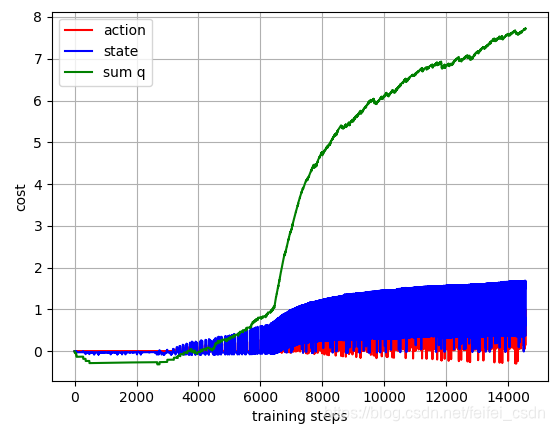
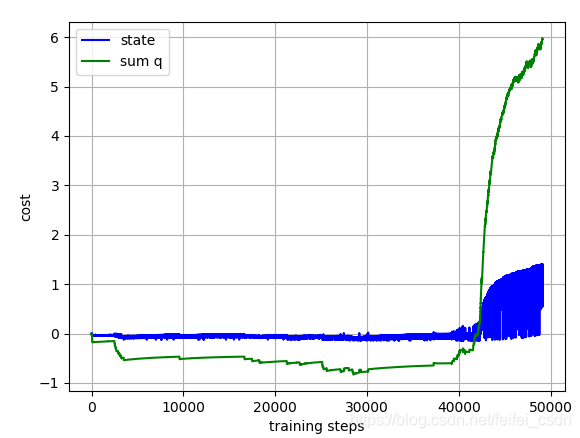
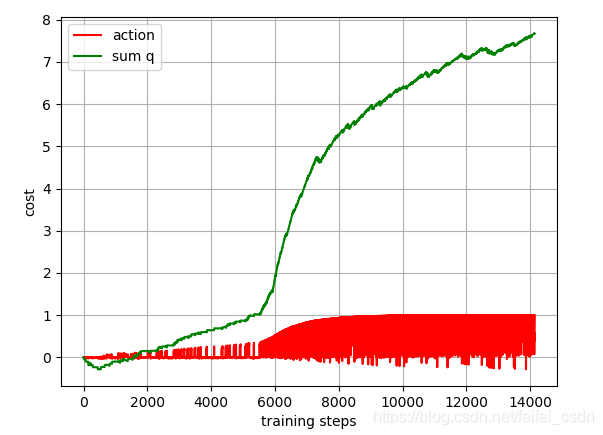
采用:
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
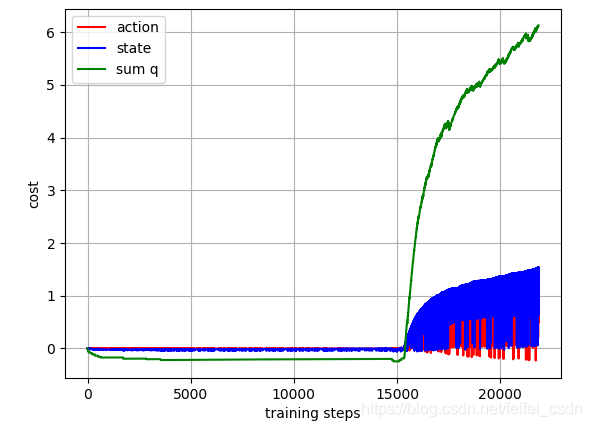
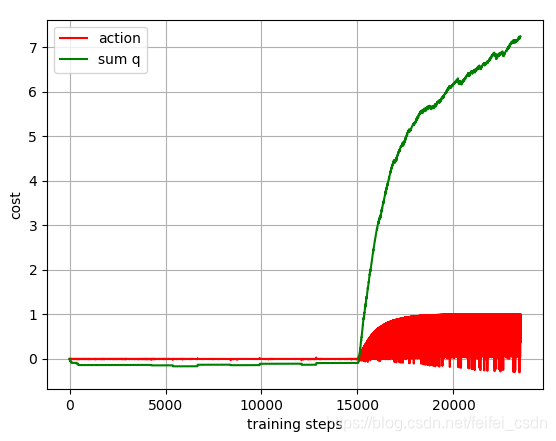
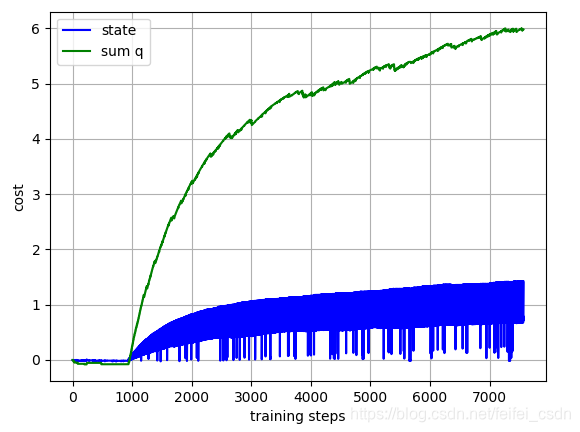
实际上一直都没有理解那个最后的终止条件到底是什么意思!!!!

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









