







问题
GLGExplainer是一种用于提取GNN全局解释的方法。它通过将局部解释嵌入到低维空间中,并使用逻辑组合的方式来生成全局解释。这种方法可以帮助我们理解GNN在图数据上的决策过程。
目的动机
- 现有的解决方案要么简单地列出给定类的局部解释,要么生成给定类的最大得分的合成原型图,对于GNN的行为提供全局解释的探索要少得多,尽管它在可解释性和调试方面具有潜力。
- 局部解释:解释了为什么网络预测特定输入样本的某个值
- 全局解释:捕捉模型的整体行为,抽象出单个嘈杂的局部解释,以支持模型的单一鲁棒概述。
- 实例级解释是通过模型确定输入中的重要特征或该输入的决策过程来解释对给定输入示例的预测。
- 模型级别的解释旨在通过研究哪些输入模式可以导致某种预测来解释模型的一般行为,而不考虑任何特定的输入示例。
- 基于概念的可解释性,其中解释是使用“概念”构建的,即,中级、高级和语义上有意义的信息单元,通常被人类用来解释他们的决策。
- 概念瓶颈模型和原型零件网络是两种流行的架构,它们利用概念学习来学习可解释的设计神经网络。
- 逻辑解释网络(LEN)为根据一组输入概念表达的每个类生成基于逻辑的解释。这种基于概念的分类器提高了人类的理解,因为它们的输入和输出空间由可解释的符号组成。
然而,这些解决方案并不是为了解释已经学习的GNN而设计的。
- GLocalX 是通过将局部解释分层聚合成全局规则来产生黑盒模型的全局解释。然而,这种解决方案不容易适用于GNN,因为它需要将局部解释表达为逻辑规则。
- 全局性解释:XGNN其将GNN的全局解释问题框定为输入优化的形式,使用策略梯度为每个类生成合成原型图。该方法需要先验的领域知识,这是不总是可用的。此外,它无法识别返回的解释中的任何组合性,并且没有原则性的方法来识别为给定的类生成替代解释。
方法
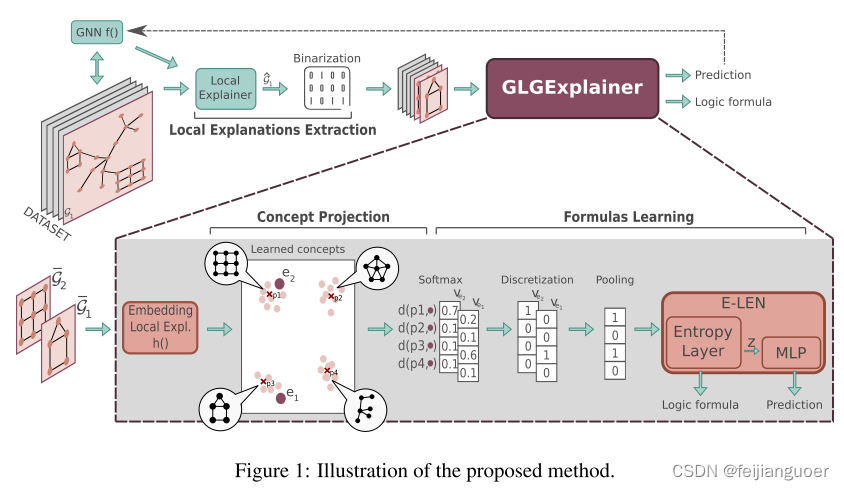 使用可用的本地解释器之一以获得数据集中每个样本的本地解释。然后,我们将这些局部解释映射到一些学习原型,这些原型将代表最终的高级概念(例如图中的主题)。最后,对于公式提取,我们将概念激活向量输入到基于熵的 LEN (E-LEN),该向量经过训练以匹配 f 的预测。
使用可用的本地解释器之一以获得数据集中每个样本的本地解释。然后,我们将这些局部解释映射到一些学习原型,这些原型将代表最终的高级概念(例如图中的主题)。最后,对于公式提取,我们将概念激活向量输入到基于熵的 LEN (E-LEN),该向量经过训练以匹配 f 的预测。
具体有以下步骤
- Local Explanations Extraction:我们传输过程的第一步是提取局部解释。原则上,每个输出可以映射到输入样本的子图的本地解释器都与我们的方法兼容。在这项工作中,我们依赖 PGExplainer ,因为它允许提取任意不连续的主题作为解释,在实验中给出了出色的结果。
为了一般性,令 LEXP(f, G) = G 是通过应用局部解释器 EXP 生成 GNN f 在输入图 G 上的预测的局部解释而获得的加权图,其中每个 Aˆ ij 相对于^G 是边 (i, j) 成为重要边的可能性。通过使用阈值 θ ∈ R 对局部解释器 ˆG 的输出进行二值化,我们获得了一组连通分量 ,使得 U i G̅ i ⊆ ˆG。为了方便起见,我们今后将把这些 ́Gi 中的每一个称为局部解释。 - Embedding Local Explanations:学习每个局部解释的嵌入,该嵌入允许将功能相似的局部解释聚集在一起。通过标准 GNN h,它将任何图 G 映射到固定大小的嵌入 h(G) ∈R 。由于每个局部解释 G 是输入图 G 的子图,因此在我们的实验中,我们使用数据集的原始节点特征。但请注意,可以任意增强这些功能以使聚合更容易。该聚合的结果由图嵌入的集合
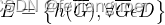 组成。
组成。 - Concept Projection:将每个嵌入e ∈ E的图投影到m个原型的集合P {pi ∈ Rd| i = 1,…,m},通过以下距离函数:
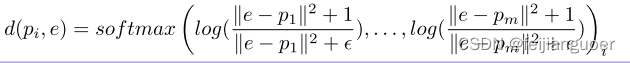
原型是从均匀分布中随机初始化的,并与架构的其他参数一起沿着学习。随着训练的进行,原型将对齐为每个局部解释集群的原型表示,这将代表图形概念的最终组。因此,该投影的输出是集合V = {ve,e ∈ E},其中ve = [d(p1,e),.,d(pm,e)]是包含图嵌入e(因此映射到它的局部解释)到m个概念的概率分配的向量,并且此后将被称为概念向量。
补充:原型的个数m是自行定义的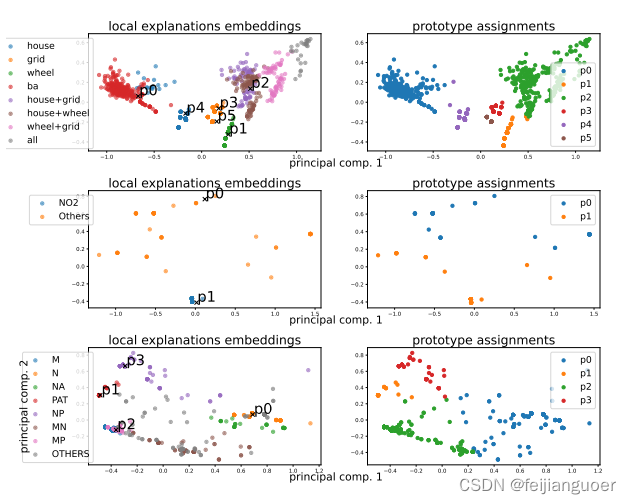
-
如图所示,3个数据集上,在第一列的三个图上,通过第二步节点嵌入将相似的局部解释聚集在一起,学习原型。
-
再通过softmax距离函数计算每个输入的子图-G到各个原型的距离。把他称为概率向量。
-
由于学习概念就是需要得到一个真值表,因此概念向量需要具有离散性,使用离散Gumbel-Softmax技巧来实现离散性。再进行池化得到一个总的概念向量。
这里有些不好理解,举个例子说明:如流程图中e1和e2经过离散化的概念向量分别为(1,0,0,0)和(0,0,1,0),这说明e1与p1原型更接近、e2与p3原型更接近。池化后的概念向量为(1,0,1,0)可能得到的概念也就是真值公式为p1+p3,通过这个公式去解释,其实也就是这篇论文的一个创新点。
- Formulas Learning: 由E-LEN 组成,即以熵层作为第一层实现的逻辑可解释网络。E-LEN学习将概念激活向量映射到类,同时鼓励稀疏使用概念,从而允许可靠地提取模拟网络行为的布尔公式。训练 E-LEN 来模拟 GNN f 的行为,并用从本地解释中提取的图形概念为其提供数据。给定输入图 Gi 的一组局部解释和相应的一组概念向量 ,通过池化算子聚合概念向量,并将得到的聚合概念向量馈送到E-LEN,提供 f(Gi) 作为监督。在实验中,使用了最大池化算子。
熵层学习从池化概念向量到
(i) 嵌入 z(作为任何线性层)的映射,其中将被连续的 MLP 用于匹配 f 的预测。
(ii) 真值表 T 解释网络如何利用概念对目标类别进行预测。 - Supervision Loss:GLGExplainer 经过端到端训练,损失如下:

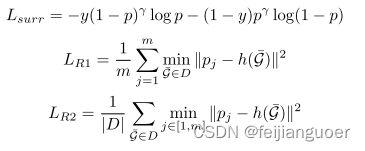
其中Lsurr对应于我们的 E-LEN 的预测和要解释的预测之间的Focal BCELoss,而LR1和LR2分别旨在推动每个原型pj接近至少一个局部解释,并推动每个局部解释接近至少一个原型。p和γ分别表示正类预测的概率和控制惩罚困难示例的程度的聚焦参数。
对于一个二分类模型,当模型对一个样本进行预测时,会给出一个表示正类预测概率的值。这个概率值可以理解为模型认为该样本属于正类的置信程度。概率越高,代表模型越确定该样本属于正类。
控制惩罚困难示例的程度的聚焦参数,是用来调节模型对困难示例的处理程度的参数。困难示例指的是那些对于模型来说比较难以分类的样本。通过调节聚焦参数,可以控制模型对困难示例的错误分类问题的关注程度。当该参数较高时,模型会更加注重困难示例的惩罚,试图减少对这类样本的错误预测。
换句话说,正类预测的概率和聚焦参数是用来调整模型对于正类预测和对困隐藏例的惩罚的程度。通过合理调节这两个参数,可以影响模型的分类行为,使其更加准确地预测正类,并在必要时对困隐藏例进行更严格的惩罚。















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









