







 本文介绍了Turing架构中的RT Core,这是一种专用于计算射线与三角形交点的ASIC流水线,显著提升了光线追踪性能。此外,还提及了Dram、Localmemory、CTA、SMSPs、Warp等GPU内部概念,帮助理解GPU的工作原理。
本文介绍了Turing架构中的RT Core,这是一种专用于计算射线与三角形交点的ASIC流水线,显著提升了光线追踪性能。此外,还提及了Dram、Localmemory、CTA、SMSPs、Warp等GPU内部概念,帮助理解GPU的工作原理。
背景
在写kernel分析或者看一些博客的时候经常遇到一些名词,这里记录一下
具体
下面的名词解释都是基于turing架构,一个简单的架构图共展示说明。
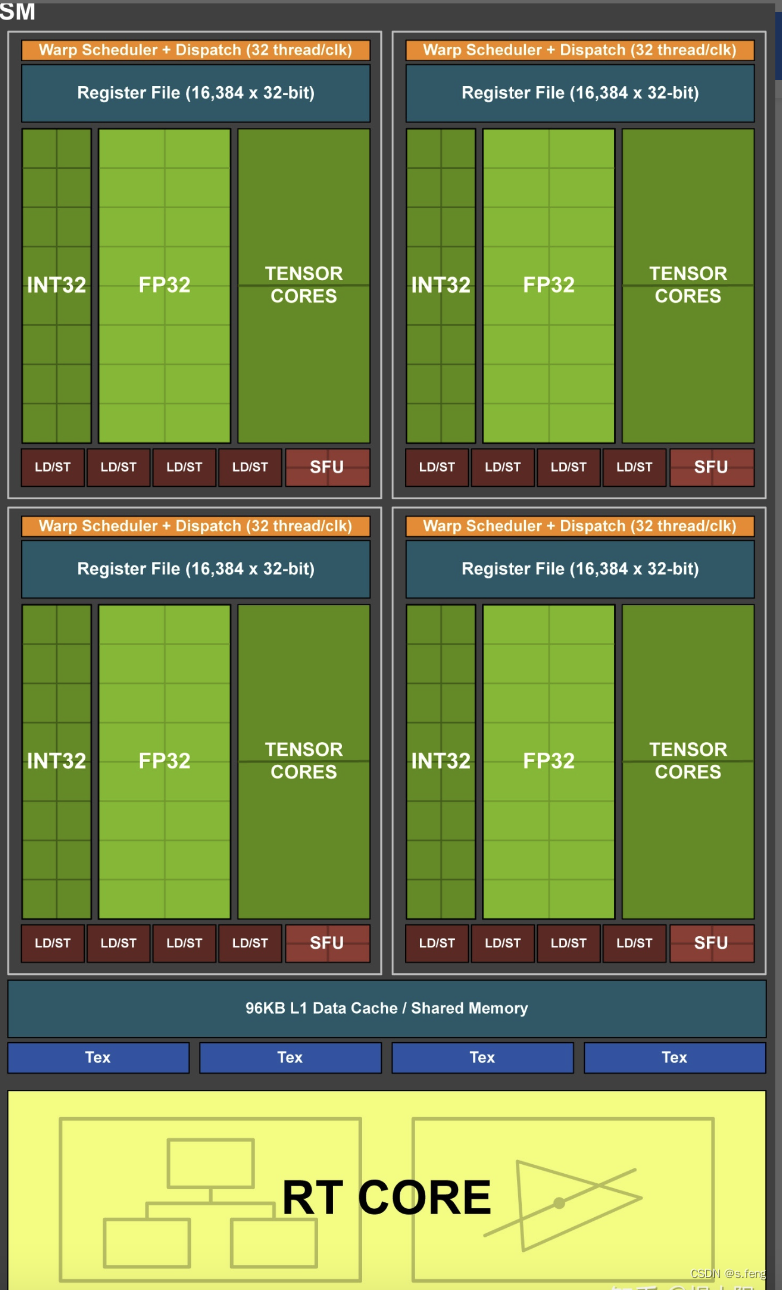
RT core实质上就是SM里面加了一条专用的流水线(ASIC)来计算射线和三角形求交,可以访问BVH,由于是ASIC专用电路逻辑,所以和用shader code来做求交计算相比,性能/mm^2可以有数量级的提升
| 名词 | 说明 |
|---|---|
| dram | 设备内存(也叫显存,也叫主存(main memory)), 是存放global memory 和 local memory |
| Local memory | local memory不是一种物理的内存类型,算是一个抽象的global memory, |
| CTA | cooperrative thread arrays, 也就是block, 其实就是warp的上一层,不知道为啥搞一个很玄学的名字 |
| SMSPs | 每个SM(如上图)被切分四个处理单元 被称为SM sub partitions, 这些处理单元是SM的主要组成部分,一个子单元负责一个固定尺寸的warps pool. |
| warp | 一个warp由32个线程组成,可以认为是最小执行单元,一个warp会被分在一个sub partition中,从launch到结束 |
| instruction | 指令指的是一个SASS(汇编指令),每一个执行的指令可能会产生0或者多个request(请求),一般情况是等于一个请求, |
| sector | cuda里的一种计数单位,32字节(bytes) |

















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









