







概述
内存加载分为缓存加载和没有缓存加载,仔细研究这个说法有点奇怪,具体如下:
- 缓存加载
数据先经过L2 cache, 然后经过L1 cache, 最后到达线程的寄存器。
- 非缓存加载
数据先经过L2 cache, 到达线程的寄存器。
L1 cache 和L2 cache
L1的取数窗口是每次可以取128bit数据,L2的取数窗口是每次可以取32bit的数据.
当一个线程束要获取数据时,如果每个线程束需要3bit数据,那么32个线程束一共要获取96bit,那么会生成一个获取96的数据的内存请求。一个内存的数据如果正好在一个cache line(cache的取数窗口)中,那么就会变成一个cache line 请求, 如下:

一个内存的数据如果处在不同的cache line(cache的取数窗口)中,那么就会变成多个cache line 请求, 假设cache line 是128的话,下图就会出现3个cache line request:

cache line
我这里通俗的解释为取数窗口,这个取数窗口有两个属性,第一的长度固定,L1是128,L2是32。第二是地址开始位置固定,是长度的整数倍。
情况1
分析,每个线程需要4字节,一个warp需要128个字节,而发现这128个字节正好在一个cache line中,所以一个内存事务(cache line request)就可以完成。

情况2
分析,每个线程需要4字节,一个warp需要128个字节,而发现这128个字节正好在一个cache line中,所以一个内存事务(cache line request)就可以完成。这里有个疑惑是这个cache line是如何把数据分配到每个线程的寄存器中的?上面一对一好理解,这里跟同事请教说也是可以的,这个cache line reques确实可以把数据分配到各个线程的寄存器中,记住就好了。

情况3
分析,每个线程需要4字节,一个warp需要128个字节,而发现这128个字节正好在2个cache line中,所以需要2个内存事务(cache line request)可以完成。可以发现两个内存事务的利用率是有50%,因为有一半的数据没有使用。

nvprof --metrics gld_efficiency ./a.out ## 查看内存事务的利用率
nvprof --metrics gld_transactions ./a.out ## 查看内存事务的个数
题外话
一个warp会生成几个memory request跟每个线程要获取的数据大小有关系。(待定是指load store unit)
If the size of the words accessed by each thread is more than 4 bytes, a memory request by a warp is first split into separate 128-byte memory requests that are issued independently:
Two memory requests, one for each half-warp, if the size is 8 bytes,
Four memory requests, one for each quarter-warp, if the size is 16 bytes.
__device__ void store(float4* values, int id, int index)
{
// Generate 32 different store instructions, the first done only on the first thread,
// the next done only on the first two threads, etc. and the last done on all threads.
#pragma unroll
for (int numThreads = 1; numThreads <= 32; ++numThreads)
if (id < numThreads)
values[index] = float4(); // Store a dummy value
}
__global__ void sameAddress (float4* values) { store(values, threadIdx.x, 0); }
__global__ void sequentialAddresses(float4* values) { store(values, threadIdx.x, threadIdx.x); }
__global__ void separateCacheLines (float4* values) { store(values, threadIdx.x, threadIdx.x * 128 / sizeof(float4)); }
int main()
{
// Allocate enough for worst case example: all 32 threads in the warp access a
// different 128-byte cache line.
float4* values = 0;
cudaMalloc((void**)&values, 32 * 128);
// Launch example kernels with one warp.
sameAddress <<<1,32>>>(values); // All threads access same element
sequentialAddresses<<<1,32>>>(values); // Threads access sequential elements ("ideal")
separateCacheLines <<<1,32>>>(values); // Each thread accesses a different 128-byte sector
cudaDeviceSynchronize();
return 0;
}
上述代码相关说明:链接,如果理解了上述代码和相关说明,对于内存处理的相关问题,基本算是达到及格线水平了。
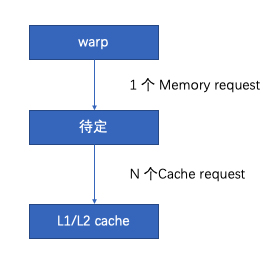
在nvidia中还会遇到instruction,request,transaction三个名词,那么这三个的意思是啥?下面是知乎cloudcore大佬给的解释:
instruction就是每个warp发射的指令数。request一般是硬件模块级的叫法,load store单元到l1,l1到l2,l2到hbm,都可以称为request。模块间转移数据一般有颗粒度,cache一般是按cacheline来,发一次数据就是一个transaction。这样一个request可能需要多个transaction,比如数据不在一个cacheline的情况。
根据大佬的解释,一个warp中比如每个线程都要获取一个int(4字节),接下来warp会生成一个instruction发送给load store unit,接下来load store unit就会发给L1一个memory request. 而L1每次的cache line假如是128字节, 那么L1每次能转移的数据单元就是128字节,假如global memory 目前全部在缓存L1中,那么L1就会看这个memory request, 如果请求的32个int都在一个cache line的话,就一个transaction发出去,如果分的很散(比如32个地址隔的都比较远)就会用32个transaction发出去。
补充
现在当下的内存cache line默认是32个字节(指令LD.E),也就是说一个warp中,每个线程访问一个字节,且内存地址是对齐的,那么这个带宽利用率一定是100%, 但是我们经常可以看到利用float2, float4等来加速,这样的话来看,这个在实际sass中可以看到,使用的是LD.64, LD.128, 我理解是内存事务调整为64和128。















 1749
1749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









