







思想
最朴素的思想是一个gemm起一个kernel,然后循环就可以n次就行,但是有些gemm尺寸比较小,这样一个wave下sm无法全部利用,为此用多stream来启动,这样就可以保证多个kernel可以一块执行,但是效果不是很好,可能是因为多次启动的原因。为此需要继续优化思路,这里利用 persistent kernel的思想去处理,简单的来说就是kernel不切出去,一直循环加载待处理问题。
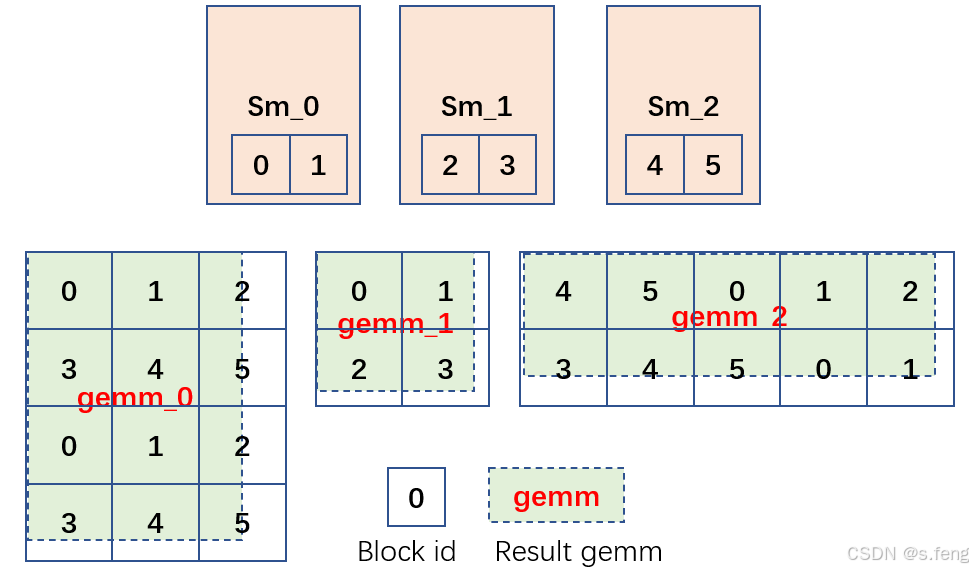
上面这幅图简单的介绍了思想,这里要注意,绿色块的gemm是指结果矩阵,假如每个sm里面可以放得下2个block, 那就是6个常驻block,这里假如有3个gemm,那么每个block需要负责的区域如上图。这有个隐藏的问题是某个gemm的k极大,那么负责那个gemm的几个block就会一直在那计算,但是其他block都已经完成工作了,所以就需要提前进行排序,把耗时多的tile尽量都放在一个wave里面完成。
数据初始化
int64_t total_elements_A = 0;
std::vector<int64_t> lda_host;//存每个problem的数据个数,存在host里,后面拷贝到device的lda
lda_host.resize(problem_count());
for (int32_t i = 0; i < problem_count(); ++i) {
auto problem = options.problem_sizes.at(i);
lda_host.at(i) = LayoutA::packed({problem.m(), problem.k()}).stride(0);
offset_A.push_back(total_elements_A);
int64_t elements_A = problem.m() * problem.k();
total_elements_A += elements_A;
lda.reset(problem_count());
block_A.reset(total_elements_A);// device 一共需要多少A数据量,同时cudamalloc
}
综上在device上:
lda=[size_0, size_1, …, size_14 ];
problem_sizes_device=[[m0,n0,k0], [m1, n1, k1],…[m14,n14,k14]]
block_A=[all value]
ptr_A=[ptr_0, ptr_1,…ptr_14]
using ElementA = cutlass::half_t;
using ElementB = cutlass::half_t;
using ElementOutput = cutlass::half_t;// C和D都是half_t, 但是A*B的中间值用float
using ElementAccumulator = float;
using LayoutA = cutlass::layout::ColumnMajor;
using LayoutB = cutlass::layout::ColumnMajor;
using LayoutC = cutlass::layout::ColumnMajor;
using GemmKernel = typename cutlass::gemm::kernel::DefaultGemmGrouped<
ElementA,
LayoutA,
cutlass::ComplexTransform::kNone,
8,//因为是half,所以单条指令访问128bit/16bit=8
ElementB,
LayoutB,
cutlass::ComplexTransform::kNone,
8,
ElementOutput, LayoutC,
ElementAccumulator,
cutlass::arch::OpClassTensorOp,
cutlass::arch::Sm80,
cutlass::gemm::GemmShape<128, 128, 32>,
cutlass::gemm::GemmShape<64, 64, 32>,
cutlass::gemm::GemmShape<16, 8, 16>,
cutlass::epilogue::thread::LinearCombination<
ElementOutput, 128 / cutlass::sizeof_bits<ElementOutput>::value,
ElementAccumulator, ElementAccumulator>,
// NOTE: Threadblock
cutlass::gemm::threadblock::GemmBatchedIdentityThreadblockSwizzle,
4>::GemmKernel;
using GemmGrouped = cutlass::gemm::device::GemmGrouped<GemmKernel>;
计算
这个就是和之前的gemm没啥区别了,重要的是problem_visitor的实现,一种方式在cpu上算好放在share memory中,一种是在gpu上运行,我比较推荐在cpu上,逻辑简单清楚一些,做计算的时候只要关注gemm就行。
总结
这里简单记录一下group的思想,在hopper架构上,为了隐藏prelogue 和epilogue的延迟也是这个思想写的,这里可以先热身了解一下

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









