






广告位:
图像拼接论文精读专栏
—— 图像拼接领域论文全覆盖(包含数据集),省时省力读论文,带你理解晦涩难懂的论文算法,学习零散的知识和数学原理,并学会写图像拼接领域的论文(介绍、相关工作、算法、实验、结论、并附有参考文献,不用一篇一篇文章再找)
图像拼接论文源码精读专栏
—— 图像拼接有源码的论文全覆盖(有的自己复现),帮助你通过源码进一步理解论文算法,助你做实验,跑出拼接结果,得到评价指标RMSE、SSIM、PSNR等,并寻找潜在创新点和改进提升思路。
超分辨率重建专栏
—— 从SRCNN开始,带你读论文,写代码,复现结果,找创新点,完成论文。手把手教,保姆级攻略。帮助你顺利毕业,熟练掌握超分技术。
有需要的同学可以点上面链接看看。
文章目录
简介
前言:最近在看EfficientNet,里面用到了与MobileNetV2相似的结构,所以找来看一下并记录。
MobileNetV2是一个轻量化网络,论文题目和地址如下:
论文题目:MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文地址:
https://arxiv.org/abs/1801.04381
重点干货
- 倒残差模块/反向残差模块(Inverted Residuals)
- 线性瓶颈(Linear Bottleneck)
其中,倒残差模块中还用了
深度卷积(Depthwise Convolution,DW)
和
逐点卷积(Pointwise Convolution,PW)
,我们后续介绍。
倒残差模块/反向残差模块(Inverted Residuals)
深度卷积(Depthwise Convolution,DW)
- 深度卷积(Depthwise Convolution,DW)
:完全在二维平面上进行,一个卷积核负责一个通道;一个通道只被一个卷积核卷积。结构如下图:
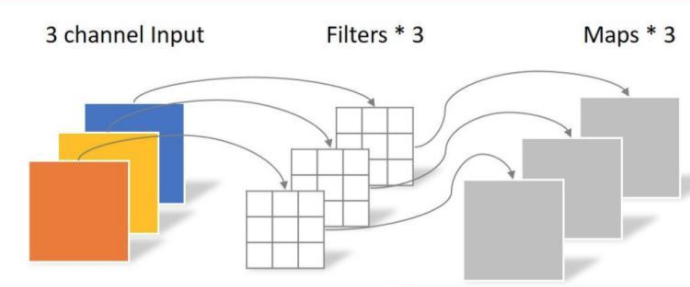
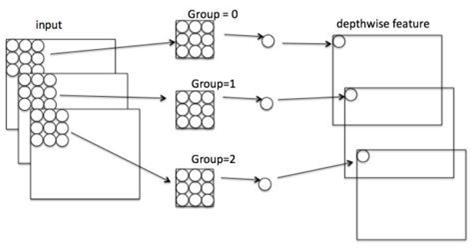
可以看到,DW操作的输入通道数=Feature Map数=输出通道数,且每个通道之间无相互关联,单独进行卷积运算,就相当于分组进行了计算。在Pytorch中可以用nn.Conv2d()实现。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,bias=True)
其中参数含义分别为:(
输入通道
,
输出通道
,卷积核大小,步长,补0,卷积核间隙,
分组
,偏置)。实现倒残差模块应该设置
in_channels=out_channels=groups
由于DW操作每个通道单独操作,没有利用不同通道的feature信息,所以需要PW操作来整合不同通道的信息,产生新的特征
逐点卷积(Pointwise Convolution,PW)
- 逐点卷积(Pointwise Convolution,PW)
:卷积核大小为1×1×in_channels,将上一步操作的特征图在通道方向上加权组合,生成新的feature map,大小与输入一致。以较小的计算量进行降维或者升维操作,"混合"通道信息。

就是一个1×1卷积,输出通道数改变。
nn.Conv2d(in_channels,out_channels,kernel_size=1,padding=0,bias=False)
将DW操作和PW操作结合起来,叫
深度分离卷积(Depthwise Separable Convolutions)
,整体结构如下:
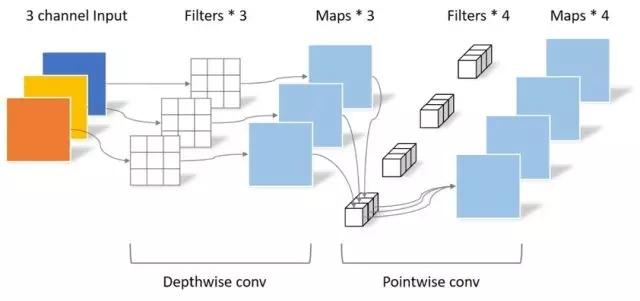
- 倒残差模块
:输入经过1×1卷积进行通道扩张(通过增加卷积核的个数扩大通道数,文中扩大6倍),然后使用3×3的DW,最后用1×1的PW将通道压缩回去。
线性瓶颈(Linear Bottleneck)
作者的结论:
- If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation
- ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
经过一系列特征提取过程后,会产一个兴趣流形,如果它经过ReLU后得到非零结果,那它就对应一个线性变换。ReLU只有当输入流形存在于输入空间低维度时才可以完整保存输入流形的信息。
个人理解:轻量级网络的思想就是降维,减少参数。但是降维的话ReLU会损失更多的信息,而ReLU没有损失的部分就相当于一个线性分类器。所以干脆直接用线性分类器来提高性能。
总结:将PW操作的激活函数由ReLU换成Linear
将线性瓶颈应用到倒残差模块中,结构如下:
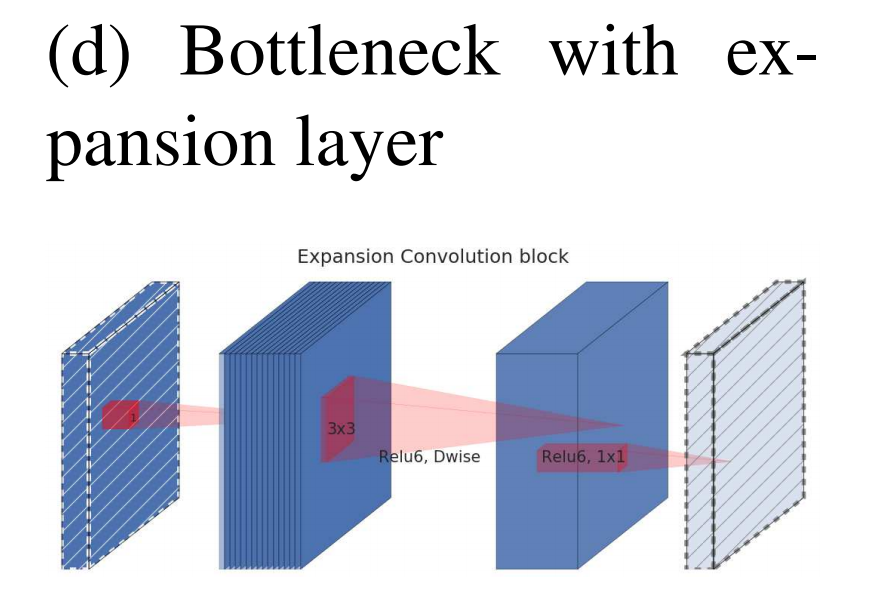
MobileNetV2整体结构与具体网络参数
MobileNetV2网络的整体结构如下
:
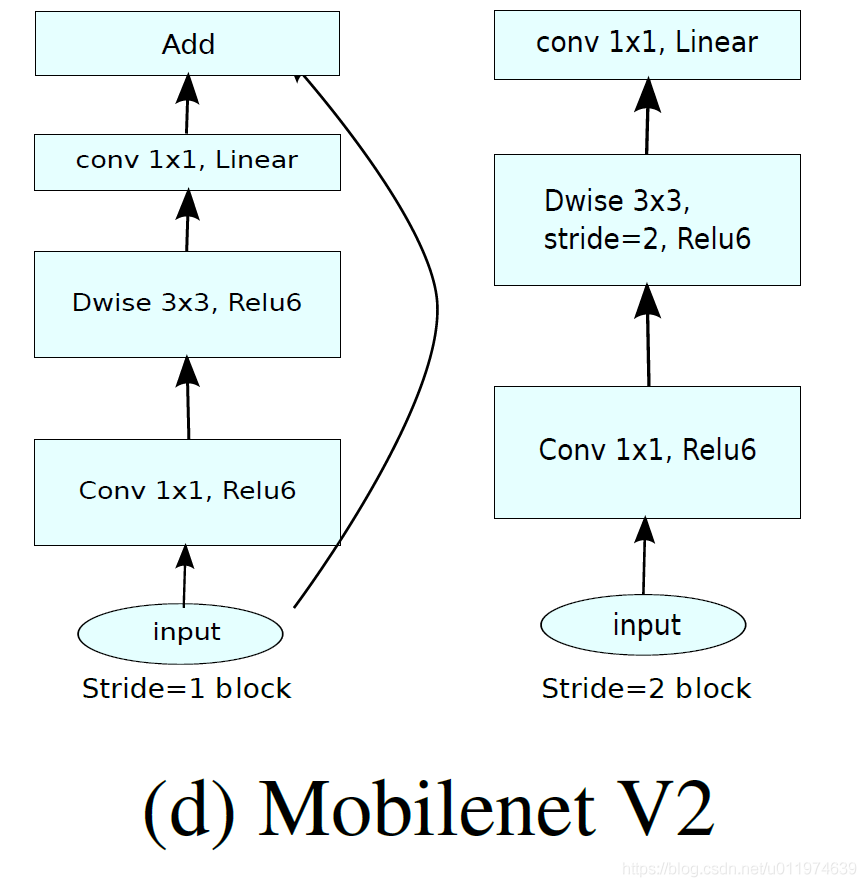
- stride = 1时,输入先经过一个1×1卷积和ReLU6,再经过一个3×3的DW操作,其中padding=1(保证输入和输出大小相同),再经过一个1×1的PW操作,最后通过shortcut将PW后的结果与初始相加得到最终结果。
只有当步长为1且in_channels!=out_channels时才使用shortcut,否则shortcut无意义
- stride = 2时,省略shortcut操作
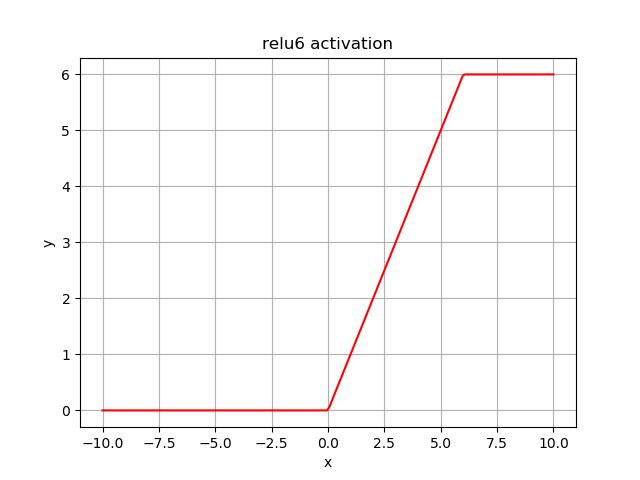
ReLU6:
f
(
x
)
=
m
i
n
(
m
a
x
(
0
,
x
)
,
6
)
f(x) = min(max(0,x),6)
f
(
x
)
=
min
(
ma
x
(
0
,
x
)
,
6
)
具体网络参数如下
:

其中,t代表扩张倍数;c代表输出通道数;n代表该层重复n次;s为步长。
注意
:
All layers in the same sequence have the same
number c of output channels. The first layer of each
sequence has a stride s and all others use stride 1.
- 重复层序列的输出通道数都相同
- 重复层中的第一层的步长为s,其余均为1
Pytorch实现MobileNetV2
线性瓶颈块:
import torch
import torch.nn as nn
class BottleNeck(nn.Module):
def __init__(self, in_channels, out_channels, stride, t):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, in_channels*t, 1, bias=False),
nn.BatchNorm2d(in_channels*t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels*t, in_channels*t, 3, stride=stride, padding=1, groups=in_channels*t, bias=False),
nn.BatchNorm2d(in_channels*t),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels*t, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.conv(x)
if self.stride == 1:
out += self.shortcut(x)
return out
MobileNetV2整体:
class MobileNetV2(nn.Module):
def __init__(self, class_num=1000):
#根据自己数据集的分类类别修改class_num
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
#cin,cout,t,n,s
self.bottleneck1 = self.make_layer(32, 16, 1, 1, 1)
self.bottleneck2 = self.make_layer(16, 24, 6, 2, 2)
self.bottleneck3 = self.make_layer(24, 32, 6, 3, 2)
self.bottleneck4 = self.make_layer(32, 64, 6, 4, 2)
self.bottleneck5 = self.make_layer(64, 96, 6, 3, 1)
self.bottleneck6 = self.make_layer(96, 160, 6, 3, 2)
self.bottleneck7 = self.make_layer(160, 320, 6, 1, 1)
self.conv2 = nn.Sequential(
nn.Conv2d(320, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace=True)
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.linear = nn.Linear(1280, class_num)
def make_layer(self,in_channels, out_channels,t,n,s):
layers = []
#第一层
layers.append(BottleNeck(in_channels, out_channels, s, t))
while n-1:
#其他重复层,输入输出通道相同,步长为1
layers.append(BottleNeck(out_channels, out_channels, 1, t))
n -= 1
#layers是所有Bottleneck块列表,每个元素是Bottleneck块,*将layers拆成每个元素
return nn.Sequential(*layers)
def forward(self, x):
#2,3,32,32
x = self.conv1(x)
#2,3,32,32
x = self.bottleneck1(x)
x = self.bottleneck2(x)
x = self.bottleneck3(x)
x = self.bottleneck4(x)
x = self.bottleneck5(x)
x = self.bottleneck6(x)
x = self.bottleneck7(x)
#2,320,4,4
x = self.conv2(x)
#2,1280,4,4
x = self.avgpool(x)
#2,1280,1,1
x = torch.flatten(x,1)
#2,1280
x = self.linear(x)
#2,1000
return x
测试网络结构:
def test():
net = MobileNetV2()
x = torch.randn(2,3,32,32)
y = net(x)
#print(y.size())
test()
没有硬件条件,需要云服务的同学可以扫码看看:


















 6101
6101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









