







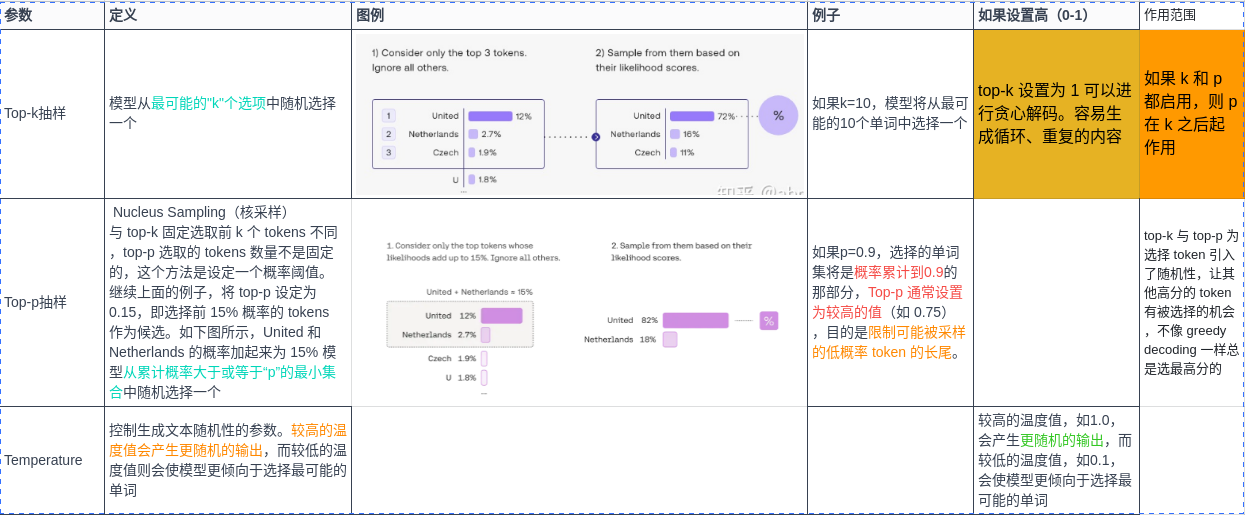
| Top-k抽样 | 模型从最可能的"k"个选项中随机选择一个 | 如果k=10,模型将从最可能的10个单词中选择一个 |
|---|---|---|
| Top-p抽样 | 模型从 累计概率大于或等于“p”的最小集合 中随机选择一个 | 如果p=0.9,选择的单词集将是 概率累计到0.9的那部分 |
| Temperature | 控制生成文本随机性的参数。较高的温度值会产生更随机的输出,而较低的温度值则会使模型更倾向于选择最可能的单词 | 较高的温度值,如1.0,会产生更随机的输出,而较低的温度值,如0.1,会使模型更倾向于选择最可能的单词 |
前言
上一篇文章介绍了几个开源LLM的环境搭建和本地部署,在使用ChatGPT接口或者自己本地部署的LLM大模型的时候,经常会遇到这几个参数,本文简单介绍一下~
- temperature
- top_p
- top_k
关于LLM
上一篇也有介绍过,这次看到一个不错的图
A recent breakthrough in artificial intelligence (AI) is the introduction of language processing technologies that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pre-trained Transformer language models, or simply large language models, vastly extend the capabilities of what systems are able to do with text.

LLM看似很神奇,但本质还是一个概率问题,神经网络根据输入的文本,从预训练的模型里面生成一堆候选词,选择概率高的作为输出,上面这三个参数,都是跟采样有关(也就是要如何从候选词里选择输出)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6282
6282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









