






 本文深入解析Mask R-CNN的工作原理及创新点,包括其在Faster R-CNN基础上的扩展,如何有效检测图像目标并生成高质量分割掩码,以及RoIAlign、FCN等关键技术的详细介绍。
本文深入解析Mask R-CNN的工作原理及创新点,包括其在Faster R-CNN基础上的扩展,如何有效检测图像目标并生成高质量分割掩码,以及RoIAlign、FCN等关键技术的详细介绍。
在博文https://blog.csdn.net/fengbingchun/article/details/87195597 中对Faster R-CNN进行了简单介绍,这里在Faster R-CNN的基础上简单介绍下Mask R-CNN。
Mask R-CNN是faster R-CNN的扩展形式,能够有效地检测图像中的目标,并且Mask R-CNN训练简单,只需要在Faster R-CNN的基础上增加一个较小的开销,同时还能为每个实例生成一个高质量的分隔掩码(segmentation mask)。Mask R-CNN是Kaiming He等人在2017年提出的,论文名字为”Mask R-CNN”,可以从https://arxiv.org/pdf/1703.06870.pdf 直接下载。
Mask R-CNN的构建方法是:在每个兴趣点RoI上加一个用于预测分隔掩码的分层,称为掩码层(mask branch),使该层并行于已有box层和分类层,具体框架结构如下图所示:

Mask R-CNN可实现像素级别的图像实例分隔(Instance Segmentation),Mask R-CNN将物体检测和目标分隔同时并行处理,取得较好实例分隔效果。Mask R-CNN是在Faster R-CNN基础上发展而来,在其基础上增加RoIAlign以及全卷积网络(Fully Convolutional Network, FCN),Mask R-CNN将分类预测和掩码(mask)预测拆分为网络的两个分支,分类预测分支与Faster R-CNN相同,对兴趣区域给出预测,产生类别标签以及矩形框坐标输出,而掩码预测分支产生的每个二值掩码依赖分类预测结果,基于此刻分隔出物体。Mask R-CNN对每个类别均独立地预测一个二值掩码,避开类间的竞争。Mask R-CNN是逐像素分隔。
Mask R-CNN框架结构:当我们在该网络中输入一张任意大小的图像,系统会通过深度卷积网络完成两个任务,第一个任务是Faster R-CNN的RPN网络,主要实现候选区域;第二个任务是目标检测。KaiMing He等人做出的第一点改进就是将原来的RoIPool改为了RoIAlign,如下图所示,主要原因是对于分隔操作是基于像素的,而Faster R-CNN在对图像进行RoIPool时,有两次量化过程,这中间出现像素的输入与输出没有一一对应。RoIAlign直接将feature map划分成m*m的bin,然后采用双线性插值就可以保证池化过程中像素在输入前后的一一对应关系。

Mask R-CNN网络经过区域推荐网络提取候选区域,区域推荐网络是一个轻量的神经网络,通过滑动窗口扫描特征图进行卷积操作,结合不同的尺寸与长宽比,生成互相重叠区域,即anchor,并给出每个anchor默认预置的位置信息,用以后续提取候选区域。区域推荐网络针对每个anchor输出两种信息,第一种信息是对anchor前景或背景类别的预测,前景类别代表该anchor中具有一定概率存在某类或多类目标,背景类别指待检测目标之外的其它物体,后续会滤除。第二种信息是预置边框的精调,当目标的中心与前景anchor的中心不完全重合,即存在偏移时,输出位置信息(x, y, w, h)的变化百分比,以精确地调整anchor位置,对目标位置的拟合更正确。在前景anchor中存在互相重叠的现象,通过非极大值抑制方法滤除前景得分低的anchor,保留得分最高的anchor,最终得到的兴趣区域。
Mask R-CNN采用RoIAlign网络层对兴趣区域尺寸进行统一定义,然后分别输入进两个分类器分支,Faster R-CNN网络进行类别以及位置的预测,FCN网络进行像素级分割。通过FCN网络来预测并输出m*m二值掩膜(Binary Mask),m*m是所提取的局部小特征图的尺寸。为了减少计算量且达到较好分割效果,采用RoIAlign网络层将m*m特征图映射回原始输入图像上,RoIAlign网络层映射质量的好坏直接影响到图像分割掩膜位置的准确度,RoIAlign插值算法的选取对Mask R-CNN网络分割速度具有较大影响。
FCN分支网络:常规神经网络如 Faster R-CNN,为达到像素级别的像素分类,选取某像素邻域图像像素块,输入神经网络进行训练或者预测,像素块的使用造成数据重复存储;预测物体类别以及位置时,将特征图压缩到全连接层,并输出一维特征向量存储预测信息,该过程破坏了特征图的平面结构,无法进行空间上的卷积计算。而图像在做实例分割时,像素生成的预测掩膜是对输入图像在空间结构上的编码,输出像素的预测掩膜无需压缩特征图为向量。
FCN网络传统卷积神经网络中的全连接层全部都换成卷积层,故称为全卷积网络。采用 RoIAlign 层更精确地将兴趣区域于特征图进行映射,由于兴趣区域在特征图上位置精确,故可以直接对特征图进行卷积,以卷积形式表达图像各像素点之间的位置以及映射关系。
经典卷积神经网络,先是连续的5个卷积层,第 6 以及第 7 层压缩特征图,得到长度为4096的一维特征向量,第8层对该向量进一步处理使得长度减小为1000,分别对应预测得到的1000类别的概率。FCN网络将后3层的一维特征向量进行改变,将其同样表示为卷积层,即(4096,1,1)、(4096,1,1)、(1000,1,1),可将其视为1*1的卷积核,如下图所示:
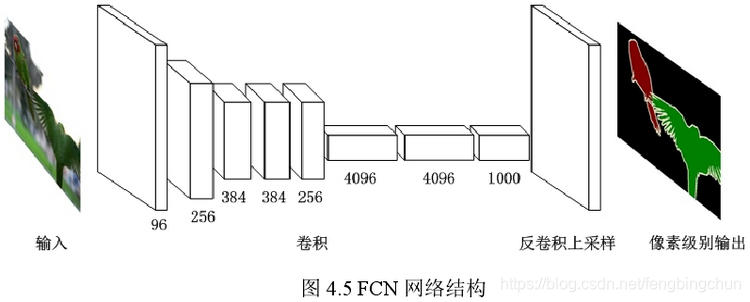
在多个卷积层后边周期性的插入池化层,导致特征图在网络中的分辨率越来越低,FCN使用上采样(Upsample)方法,使特征图从低分辨率恢复到较高的分辨率,经过5次卷积层以及池化层的搭配之后,图像的原始分辨率依次被降低到了1/ 2、1/4、1/8、1/16、1/32。为得到分辨率较高的特征图,需对最后一层的输出结果进行32倍上采样,该过程可通过添加反卷积层(Deconvolution Layer)实现,反卷积层对网络中最后一层卷积层的输出的特征图进行上采样操作,最终得到原图相同的尺寸输出,且特征图的分辨率提升。特征图经历上采样操作之后,经过神经网络最后的softmax分类器,预测某像素属于某类别的概率,在上采样的特征图上进行逐像素的预测分类,同时对原始图像的空间结构未造成破坏。
FCN在图像分割领域与使用CNN系列网络方法进行对比,具有两大优势:一是输入图像的尺寸不受限定,训练图像和后续测试图像的尺寸不做统一要求;二是效率更高,FCN不采用CNN方式将像素块输入网络,避免了重复存储问题。
RoIAlign:Mask R-CNN的主干网络,即Faster R-CNN经RPN产生众多anchor,将其映射的特征图上,再经非极大值抑制得到兴趣区域。常规的Faster R-CNN网络采用Ro IPool层对特征图中大小各异的兴趣区域进行尺寸上的统一,将兴趣区域转化成不同细粒度的特征图,后续使用最大池化进行特征提取。任意尺寸的特征图输入RoIPool层,输出固定尺寸特征图。
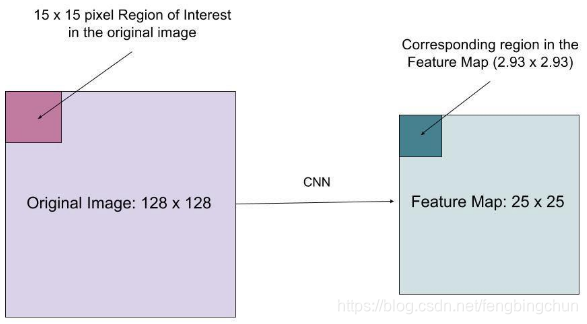
RoIPool是卷积神经网络中常用的特征提取方法,对特征图尺寸进行缩放归一化处理,Ro IPool过程采用最近邻插值方法,通常情况下,缩放后兴趣区域位置信息不是整数,但最近邻插值简单的进行四舍五入操作,赋给目标点最近像素点的像素值,会导致提取的特征和兴趣区域不重合,如下图所示,假设经卷积提取特征之后的特征图尺寸为128*128 ,将其池化为固定尺寸,如25*25的特征图,在将特征区域映射到原始图像上时,为将原始图像左下角15*15区域与特征图中的某特定特征区域建立联系,需进行插值操作。原始图像中长宽均为15个的区域像素,在特征图上对应尺寸为15*25/128≈2.93像素。在此情况下,若采用RoIPool会进行最近邻插值,非整数部分被四舍五入处理,得到特征区域如3*3,导致区域与真值之间一定程度的错位。在RoIAlign中会使用双线性插值法准确得到2.93像素的内容,这样就能很大程度上,避免了错位问题。
针对此问题采用舍弃经典RoIPool层,改进池化操作,加入ROIAlign层,使用ROIAlign 层对提取的特征和输入之间进行校准。基于四个采样位置使用双线性插值(Bilinear Interpolation),将兴趣区域归一化到一定尺寸,再将其池化到统一尺寸大小,在很大程度上避免了RoIPool方法造成的像素错位。双线性插值在两个方向上各自进行线性插值,可视为线性插值的精度升级,保证了空间的对称性。
在Faster R-CNN的网络设计上,并未考虑输入与输出之间的像素到像素对齐。而实际应用到目标上的核心操作执行的是粗略的空间量化特征提取,为了改进空间错位,Mask R-CNN提出了一种简单的方法,叫做ROIAlign,它可以保留精确的空间位置,并将掩码的准确度提高。
在Faster R-CNN中分为两个步骤进行训练,首先是RPN用于提取候选区域,然后,使用ROIPool对候选区域提取的特征进行分类和box回归,且使用共享权值来提高网络训练速度。Mask R-CNN同样采用两个步骤,第一步也是RPN提取候选区域,在第二步中,对于每个ROI,Mask R-CNN输出一个二值的掩码,将分类与box回归同时进行,简化了训练流程,网路结构如下图所示:
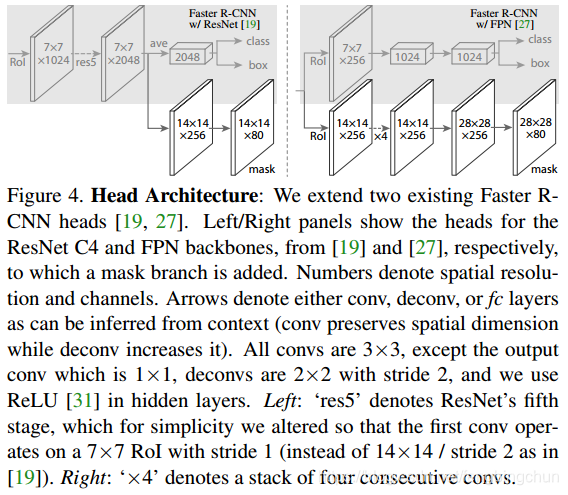
Mask R-CNN的思路很简洁,既然Faster R-CNN目标检测的效果非常好,每个候选区域能输出种类标签和定位信息,那么就在Faster R-CNN的基础上再添加一个分支从而增加一个输出,即物体掩膜(object mask),也即由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN将二进制mask与来自Faster R-CNN的分类和边界框组合,便产生惊人的图像精确分隔,如下图所示:Mask R-CNN是灵活通用的对象实例分割框架,它不仅可以对图像中的目标进行检测,还可以对每一个目标输出一个高质量的分割结果。另外,Mask R-CNN还易于泛化到其他任务,比如人物关键点检测。

以上内容均来自网络,主要参考文献如下:
1. 《基于深度学习的海面船舶目标检测》,哈尔滨工程大学,硕论,2018
2. 《基于深度学习的复杂背景下目标检测与分隔方法》,中北大学,硕论,2018
3. https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272
4. https://blog.csdn.net/jiongnima/article/details/79094159
6. https://www.jianshu.com/p/0db565b2ef7d

















 3216
3216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









