






每次看badcase时,都会怀疑自己的能力,是我哪里做的不对吗?这都学不会?

幸运的话,会找到一批有共性的问题,再有针对性地加入训练数据或者改动模型解决。而不幸的话,就是这儿错一个那儿错一个,想改动都无从下手。
今天,就推荐一篇香侬科技出品的「NLP模型可解释性综述」,帮大家寻找模型预测结果的根据所在,从而更有针对性地进行优化。
论文:Interpreting Deep Learning Models in Natural Language Processing: A Review
这篇文章描述的「可解释性」,旨在理解模型为什么给出当前的预测结果。从预测结果根据的出处来看,作者把可解释性方法分为三类:
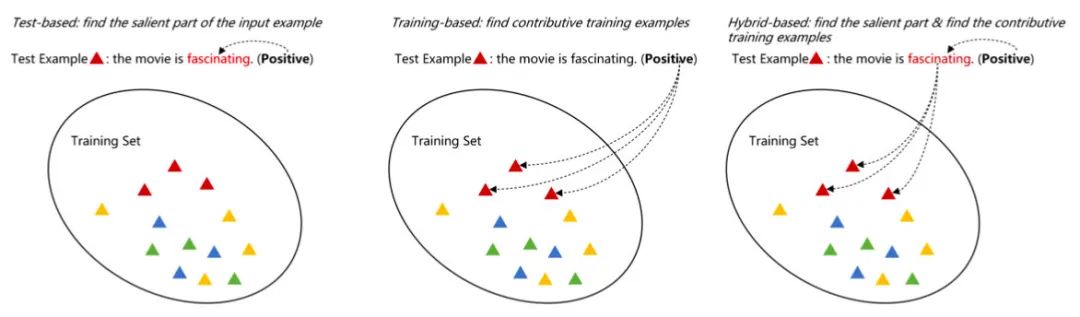
Training-based:从训练数据找根据,比如某条训练样本使得模型将当前测试样本预测为A类
Test-based:从测试数据本身找根据,比如某个词、某个片段
Hybrid-based:同时从训练数据和测试数据找根据
从可解释性方法的使用来看,又可以分为两种:
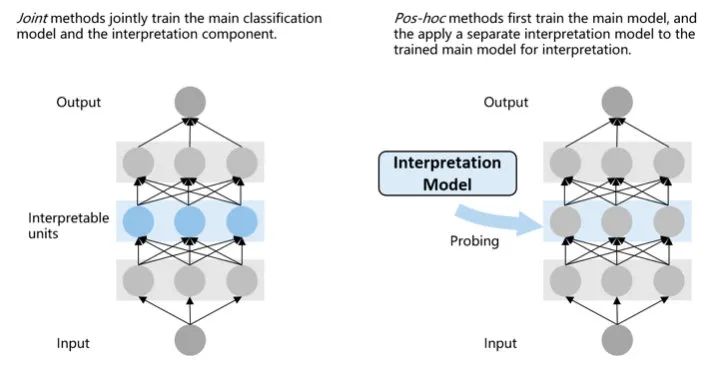
Joint methods:把负责可解释性的模块加入到模型中一起训练
Pos-hoc methods:在训练后加入可解释性模块
接下来的梳理主要以第一种分类体系为主线,不过作者也同时给出了每个方法的使用方式:
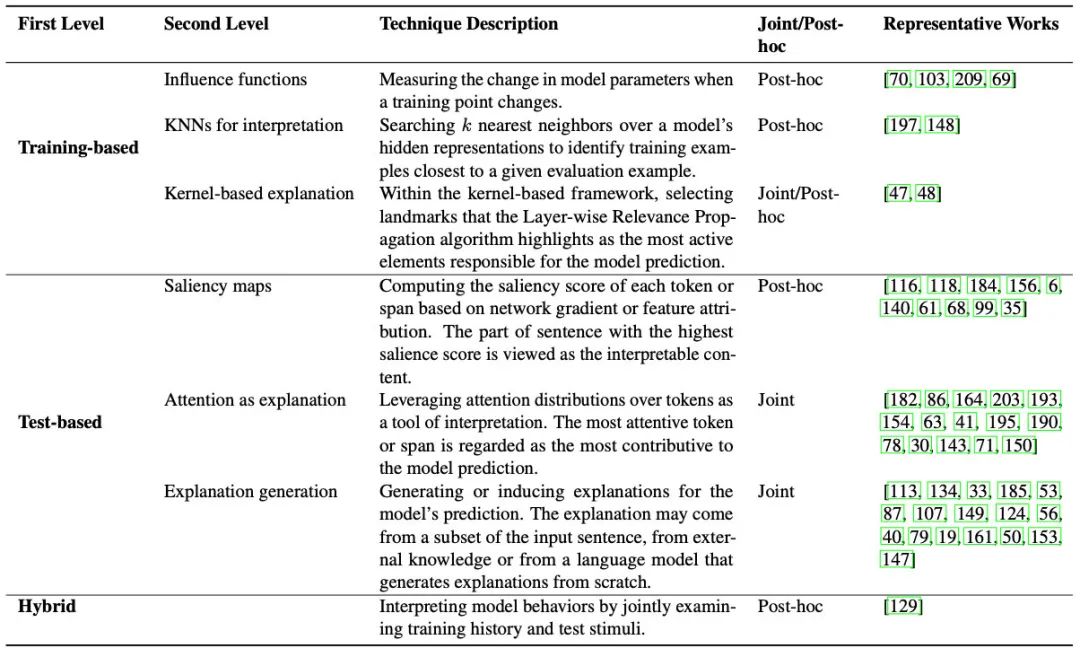
Training-based
Influence Functions
这类方法主要通过一个函数,来衡量训练样本z对于测试样本x的影响。最naive的方法就是去掉z再训练一个模型,但这样测完的时候就可以领盒饭走人了。不过我们有数学呀!于是在计算训练loss的时候,我们可以给样本z的loss加一个扰动,然后就能计算出z对于模型权重的影响,再把x输入进去,就能计算出每个z对每个x的影响情况。
由于公式太复杂,我就不列出来杀大家的脑细胞了。其中有个问题是Hessian矩阵比较难算,对于深度模型简直是灾难。于是又有学者提出了更简单的方法:Turn over dropout。
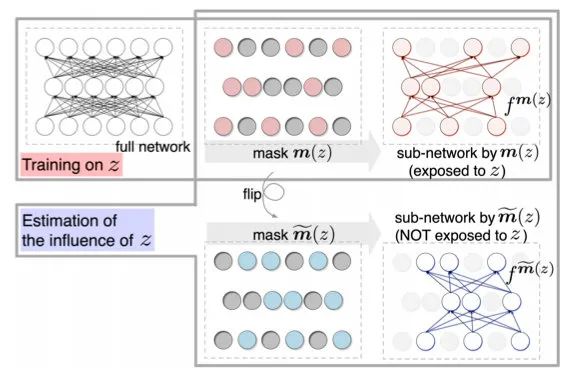
该方法的核心思想是,在训练完模型后,得到每个样本的一个mask矩阵m(z),应用mask之后可以分离出那些不受样本z影响的神经元。于是我们可以应用矩阵得到两个子网络,再输入x后预测,就能计算出预测的diff。
KNNs Based Interpretation
基于KNN的方法旨在通过测试样本的隐层表示找到相近的训练样本。
这个方法理解起来就容易多了,而且很实用。比如我们在做分类任务时,有的测试样本置信度没那么高,这时就可以通过KNN的方法去找相近的TopK个训练样本,根据它们的label分布来帮助预测:

Kernel based Interpretation
这类方法比较老了,参考文献都是18、19年的。具体做法是,先用核函数对预测样本x和多个训练样本l计算相似度K(x,l),之后把相似度矩阵投影成更高维的表示,再输入神经网络进行预测。之后再利用LRP(Layerwise Relevance Propagation)反向计算每层、每个神经元的相关性分数,传导回训练样本那一层就能知道每个样本对测试数据的影响了。
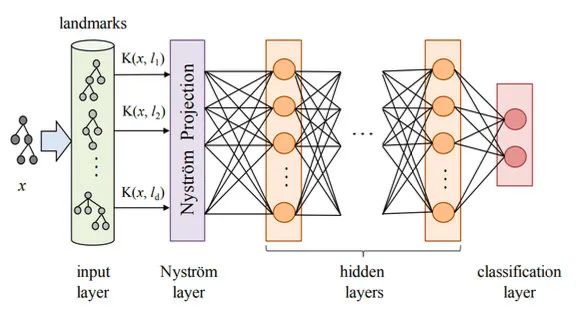
在训练时,Kernel和投影层都是一起训练的,所以这种方法既需要在训练时加入,又需要训练后的计算。
Test-based
Saliency-based Interpretation
这种方法的核心思想是利用一些metric计算测试样本中token、spen的重要程度。作者列出了很多种可以用的metirc:

Attention-based Interpretation
这个相信大家都熟悉了,就是通过观察attention矩阵来分析token的重要程度。
但有意思的事,作者也在参考文献中发现了一些质疑的声音:Attention确实能给可解释性提供帮助吗?
在一篇19年的工作《Attention is not explanation》中,该作者提到,如果注意力权重真的能提供可解释性,那它应该具备两个性质:
注意力权重应该和基于特征的Saliency-based方法有很高的相关性
改变注意力权重会影响预测结果
但是之后,该作者通过一系列的实验,证实attention不具备上述两个性质。所以直到现在(2021年11月),注意力机制是否能提供可解释性这个问题还处于争论之中。
不过该工作的实验是基于BiLSTM+Attention的,仍然有很多基于BERT的实验表明,注意力机制确实学到了不少的语言知识。
Explanation Generation
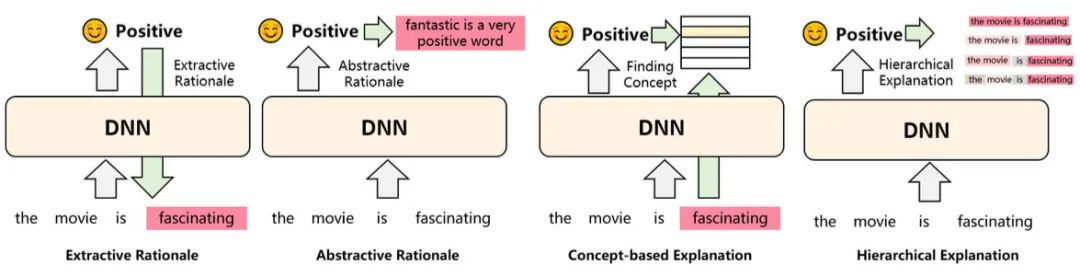
这个方法就有意思了,上述我们介绍的可解释性方法,对于人类来说可读性都比较弱。而这类方法就要求输出对人类更友好的「解释」。比如:
Extractive/Abstractive Rationale:通过抽取或者生成的方式,把样本中对结果影响大的部分输出出来
Concept-based:将预测样本联系到一些抽象概念上,比如在对餐厅的评价中,哪些词语是形容口味的、环境的等等,相当于给出了推理过程
Hierarchical:自底向上分别给句子的每个token、span打分,哪个片段是正向、哪个是负向,也相当于给出了推理过程
总结
可解释性算是一个没那么热的方向,首先是深度模型确实太复杂了、太随机了,有时候自己想的一堆idea都没用,一个bug反而有提升。到了解释的时候全靠猜,可能是哪里分布不一致?或者是模型已经足够强了,我加的输入知识它不需要?其次是大部分人都是结果导向,有时间研究不确定的可解释性,不如花心思在指标提升上。
要说可解释性重不重要,那肯定是重要的。如果对模型的了解更深入,就可以避免一些高风险的badcase。比如风控领域,一个反动内容可能会灭了一家公司,再比如医疗领域,一个错误的预测可能影响患者的生命。
论文的结尾,作者列出了很多的开放问题等待大家探索:
到底怎样才算可解释?
如何评估这些探究可解释性的方法?
是为算法工程师提供解释,还是为看到结果的用户提供解释?
目前的可解释性方法大多研究分类任务,而其他任务呢?
很多可解释性方法提供的结果不一致
是否要牺牲性能获取更高的可解释性?
可解释性方法如何应用?它的价值有多少?
那么最后,深度模型是否真的可解释?这个问题我也没有想清楚,世上无法解释的东西太多了。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群554839127,加入微信群请扫码:
















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









