






公众号:尤而小屋
作者:Peter
编辑:Peter
今天给大家分享一篇关于机器学习建模实战的文章:基于机器学习树模型的信用卡欺诈检测。
导入库
首先导入建模所需要的各种库,包含:可视化、数据预处理、特征工作、模型评估等
In [2]:
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
import plotly.graph_objs as go
import plotly.figure_factory as ff
from plotly import tools
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
import gc
from datetime import datetime
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from catboost import CatBoostClassifier
from sklearn import svm
import lightgbm as lgb
from lightgbm import LGBMClassifier
import xgboost as xgb
import warnings
warnings.filterwarnings("ignore")导入数据
数据基本信息
In [3]:
df = pd.read_csv("creditcard.csv")
df.head()Out[3]:
1、整体的数据量:
In [4]:
df.shapeOut[4]:
(284807, 31)2、数据的字段类型:
In [5]:
df.dtypesOut[5]:
Time float64
V1 float64
V2 float64
V3 float64
V4 float64
V5 float64
V6 float64
V7 float64
V8 float64
V9 float64
V10 float64
V11 float64
V12 float64
V13 float64
V14 float64
V15 float64
V16 float64
V17 float64
V18 float64
V19 float64
V20 float64
V21 float64
V22 float64
V23 float64
V24 float64
V25 float64
V26 float64
V27 float64
V28 float64
Amount float64
Class int64
dtype: object3、数据的描述统计信息:
In [6]:
df.describe()4、直接查看数据信息:包含字段名、非缺失值数量、字段类型、数据占用内存等信息
In [7]:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Time 284807 non-null float64
1 V1 284807 non-null float64
2 V2 284807 non-null float64
3 V3 284807 non-null float64
4 V4 284807 non-null float64
5 V5 284807 non-null float64
6 V6 284807 non-null float64
7 V7 284807 non-null float64
8 V8 284807 non-null float64
9 V9 284807 non-null float64
10 V10 284807 non-null float64
11 V11 284807 non-null float64
12 V12 284807 non-null float64
13 V13 284807 non-null float64
14 V14 284807 non-null float64
15 V15 284807 non-null float64
16 V16 284807 non-null float64
17 V17 284807 non-null float64
18 V18 284807 non-null float64
19 V19 284807 non-null float64
20 V20 284807 non-null float64
21 V21 284807 non-null float64
22 V22 284807 non-null float64
23 V23 284807 non-null float64
24 V24 284807 non-null float64
25 V25 284807 non-null float64
26 V26 284807 non-null float64
27 V27 284807 non-null float64
28 V28 284807 non-null float64
29 Amount 284807 non-null float64
30 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MB缺失值情况
In [8]:
df.isnull().sum()Out[8]:
Time 0
V1 0
V2 0
V3 0
V4 0
V5 0
V6 0
V7 0
V8 0
V9 0
V10 0
V11 0
V12 0
V13 0
V14 0
V15 0
V16 0
V17 0
V18 0
V19 0
V20 0
V21 0
V22 0
V23 0
V24 0
V25 0
V26 0
V27 0
V28 0
Amount 0
Class 0
dtype: int64In [9]:
total = df.isnull().sum().sort_values(ascending = False)
percent = (df.isnull().sum()/df.isnull().count() * 100).sort_values(ascending = False)
pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])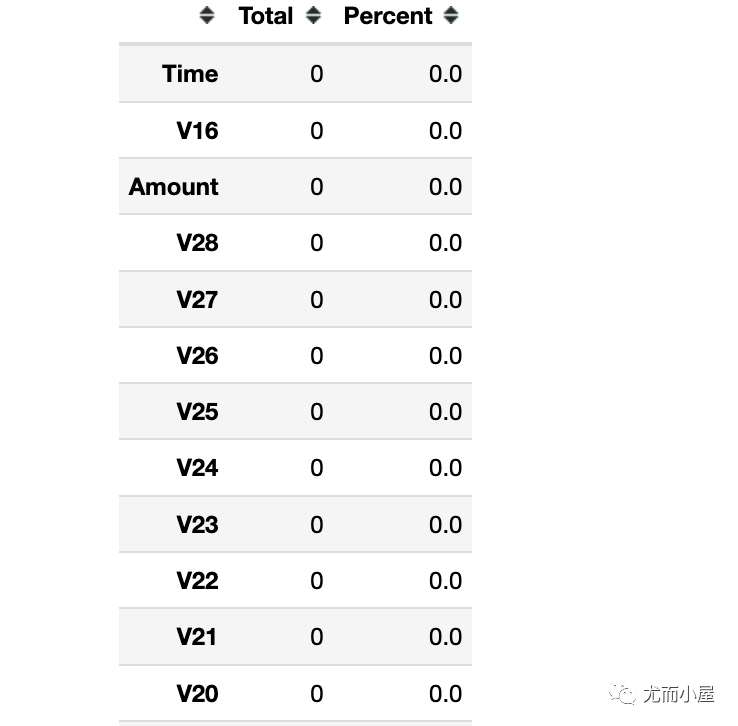
结果表明:本次数据中没有缺失值的。
数据不均衡性
本次数据有一个突出的特点:就是极其不均衡。我们查看目标变量Class中不同取值的情况:
In [10]:
sns.countplot(df["Class"])
plt.show()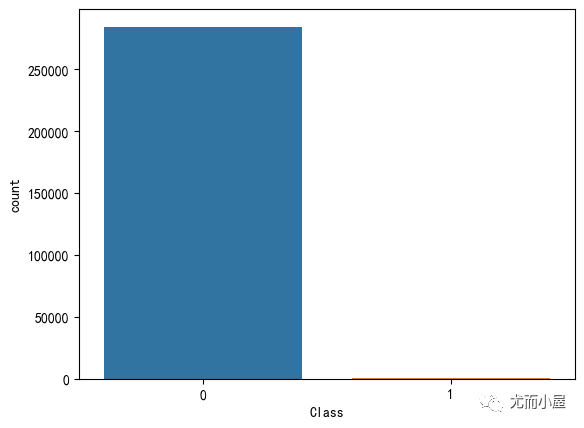
基于plotly库的写法:
In [11]:
df["Class"].value_counts().to_frame()Out[11]:
| Class | |
|---|---|
| 0 | 284315 |
| 1 | 492 |
In [12]:
df_class = df["Class"].value_counts().to_frame()In [13]:
trace = go.Bar(
x = df_class.index.tolist(),
y = df_class.Class.tolist(),
name = "数据不均衡性对比 (Not fraud = 0, Fraud = 1)",
marker = dict(color="Red"),
text = df_class["Class"].tolist()
)
data = [trace]
layout = dict(title = "数据不均衡性对比 (Not fraud = 0, Fraud = 1)",
xaxis = dict(title="Class", showticklabels=True),
yaxis = dict(title="Number", showticklabels=True),
hovermode = "closest",
width=600
)
fig = dict(data=data, layout=layout)
iplot(fig, filename='class')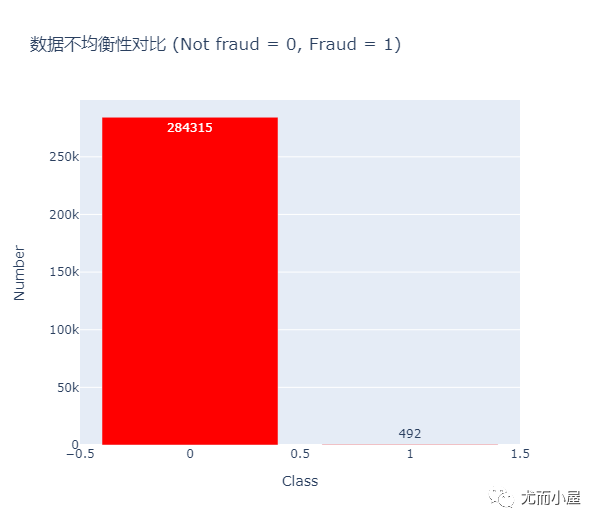
数据EDA
Time
单独取出Class为0或者1的数据:
In [14]:
class_0 = df[df["Class"] == 0]["Time"] # not fraud
class_1 = df[df["Class"] == 1]["Time"] # fraudIn [15]:
hist_data = [class_0, class_1]
group_labels = ['Not Fraud', 'Fraud']In [16]:
fig = ff.create_distplot(hist_data,
group_labels,
show_hist=False,
show_rug=False)
fig['layout'].update(title='Credit Card Transactions Time Density Plot',
xaxis=dict(title='Time [s]'))
iplot(fig)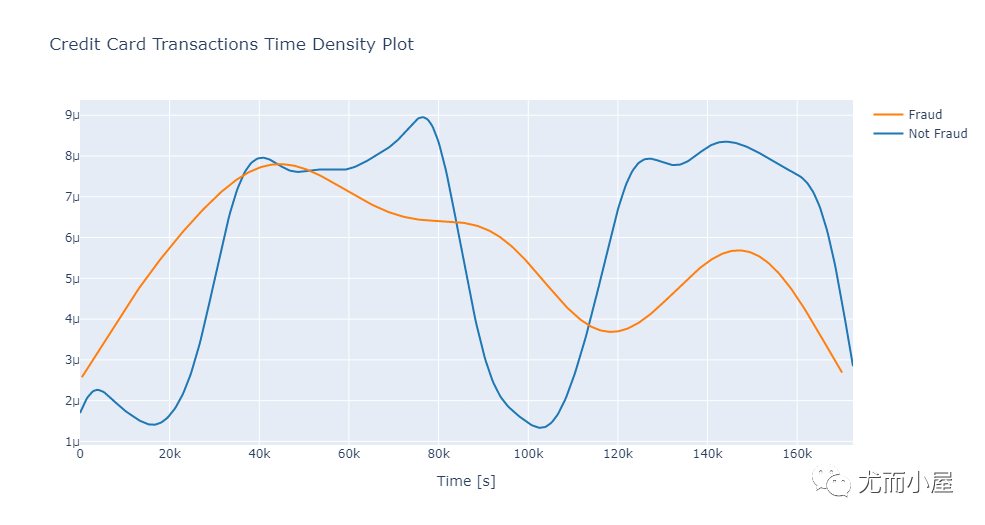
基于不同时间频率下的交易金额统计:
In [17]:
df["Hour"] = df["Time"].apply(lambda x: np.floor(x / 3600)) # 时间转成小时基于小时Hour和Class的聚合统计:
In [18]:
tmp = df.groupby(['Hour', 'Class'])['Amount'].aggregate(['min', 'max', 'count', 'sum', 'mean', 'median', 'var']).reset_index()
tmp.head()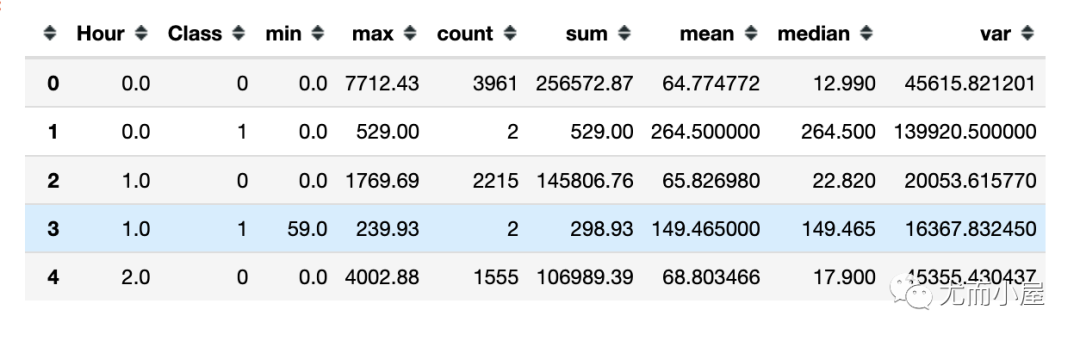
对字段的重命名操作:
In [19]:
# 重命名
tmp.columns = ["Hour", "Class", "Min", "Max", "Transactions", "Sum", "Mean", "Median", "Var"]总和sum对比
1、欺诈或非欺诈的总和对比:
In [20]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Sum", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Sum", data=tmp.loc[tmp.Class==1],color="red")
plt.suptitle("Total Amount/Hour")
plt.show()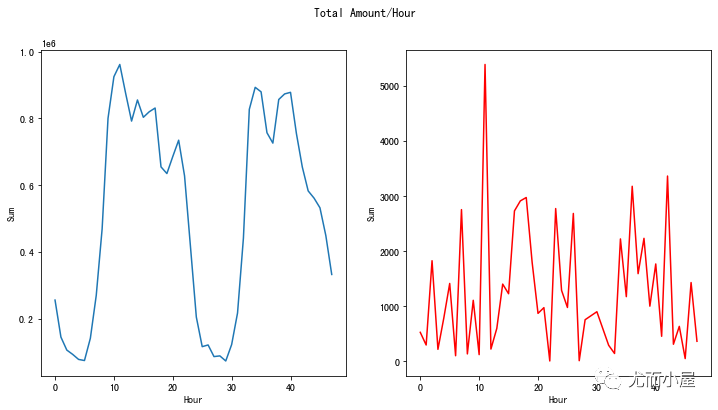
次数count对比
In [21]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Transactions", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Transactions", data=tmp.loc[tmp.Class==1],color="blue")
plt.suptitle("Transactions/Hour")
plt.show()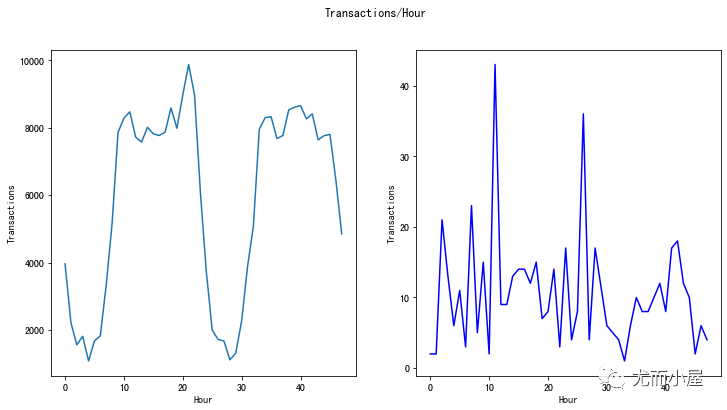
均值mean对比
In [22]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Mean", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Mean", data=tmp.loc[tmp.Class==1],color="blue")
plt.suptitle("Mean/Hour")
plt.show()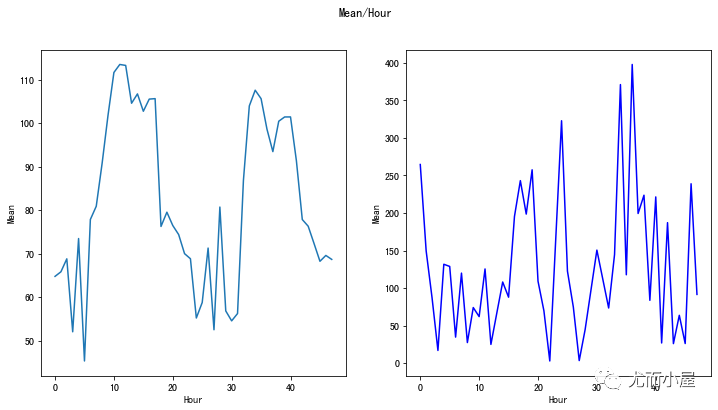
最大值max对比
In [23]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Max", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Max", data=tmp.loc[tmp.Class==1],color="red")
plt.suptitle("Max/Hour")
plt.show()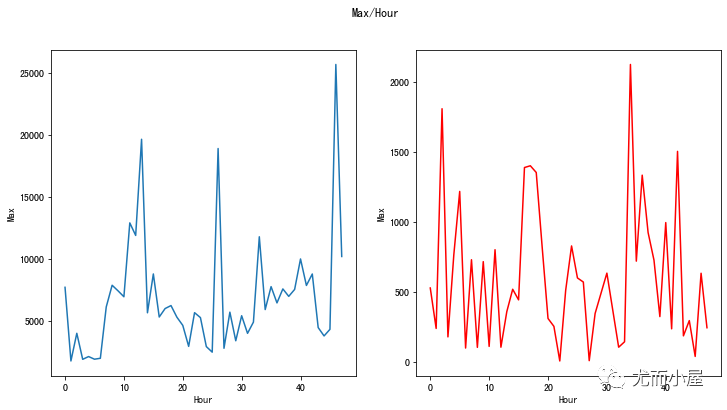
最小值Min对比
In [24]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Min", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Min", data=tmp.loc[tmp.Class==1],color="red")
plt.suptitle("Min/Hour")
plt.show()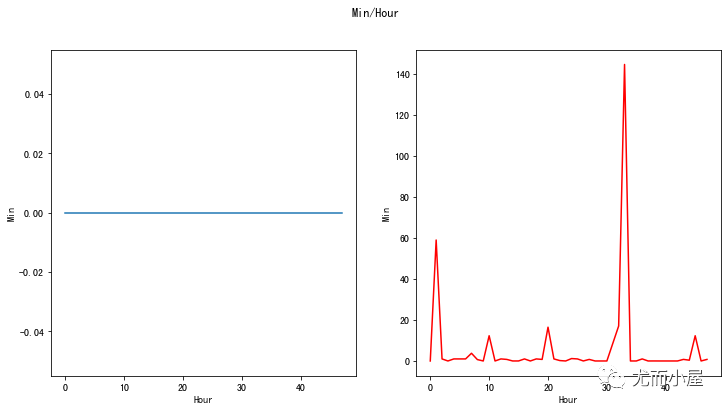
中位数median对比
In [25]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.lineplot(ax=ax1, x="Hour", y="Median", data=tmp.loc[tmp.Class==0])
s = sns.lineplot(ax=ax2, x="Hour", y="Median", data=tmp.loc[tmp.Class==1],color="red")
plt.suptitle("Median/Hour")
plt.show()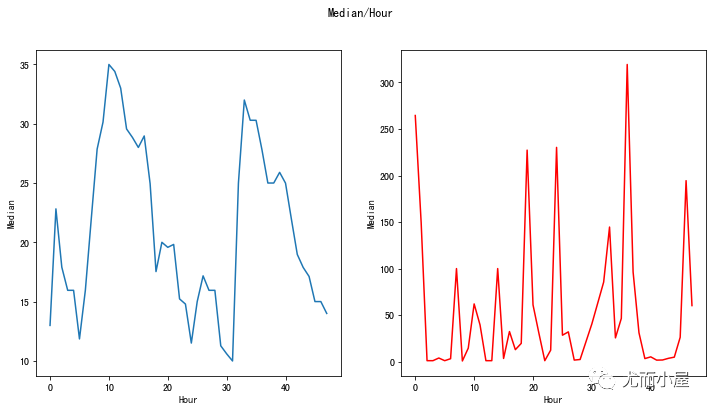
Amount对比
In [26]:
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
s = sns.boxplot(ax = ax1, x="Class", y="Amount", hue="Class", data=df, palette="PRGn",showfliers=True)
s = sns.boxplot(ax = ax2, x="Class", y="Amount", hue="Class", data=df, palette="PRGn",showfliers=False)
plt.show()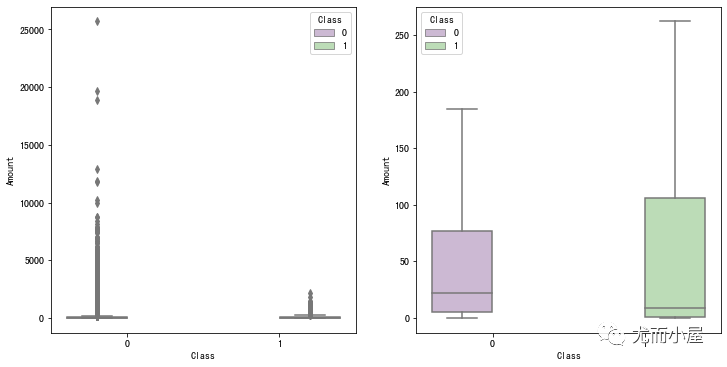
欺诈或者非欺诈情况下Amount的描述统计信息对比:
In [27]:
df_copy = df[["Amount","Class"]].copy()
df_0 = df_copy[df_copy["Class"]==0]["Amount"]
df_1 = df_copy[df_copy["Class"]==1]["Amount"]In [28]:
df_0.describe()Out[28]:
count 284315.000000
mean 88.291022
std 250.105092
min 0.000000
25% 5.650000
50% 22.000000
75% 77.050000
max 25691.160000
Name: Amount, dtype: float64In [29]:
df_1.describe()Out[29]:
count 492.000000
mean 122.211321
std 256.683288
min 0.000000
25% 1.000000
50% 9.250000
75% 105.890000
max 2125.870000
Name: Amount, dtype: float64欺诈情况下的数据分布:
In [30]:
fraud = df[df["Class"]==1] # 欺诈In [31]:
fig = go.Figure(data=go.Scatter(x = fraud['Time'],
y = fraud['Amount'],
name = "Amount",
marker=dict(
color='rgb(238,23,11)',
line=dict(color='red',width=1),opacity=0.5,),
text= fraud['Amount'],
mode = "markers"
))
fig.update_layout(dict(title = 'Amount of Fraud',
xaxis = dict(title = 'Time [s]',
showticklabels=True),
yaxis = dict(title = 'Amount'),
hovermode='closest'))
fig.show()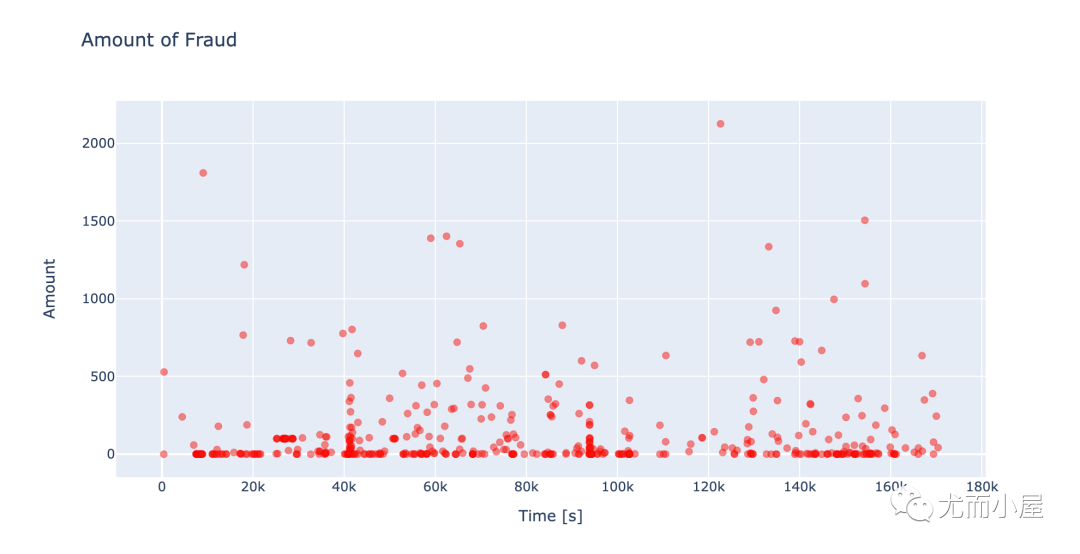
特征相关性分析
相关性热力图
In [32]:
corr = df.corr()In [33]:
plt.figure(figsize = (12,8))
sns.heatmap(corr, # corr = df.corr()
xticklabels=corr.columns,
yticklabels=corr.columns,
linewidths=.02,
cmap="YlGnBu")
plt.title('Credit Card Transactions features correlation plot (Pearson)')
plt.show()
特征两两关系
可以看到特征之间没有明显的相关性。但是一些特征和时间Time(和V3负相关)或者总额Amount(V7和V20直接相关)具有一定的关系。
探索V7和V20与Amount的关系:
In [34]:
s = sns.lmplot(x='V20',
y='Amount',
data=df,
hue='Class',
fit_reg=True,
scatter_kws={'s':2})
s = sns.lmplot(x='V7',
y='Amount',
data=df,
hue='Class',
fit_reg=True,
scatter_kws={'s':2})
plt.show()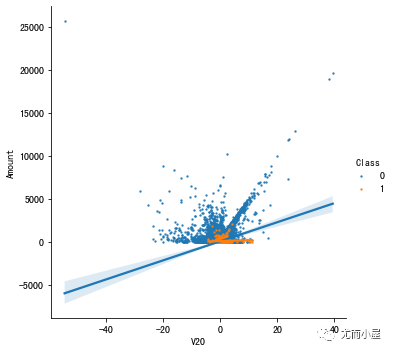
从结果中观察到:Class=0具有一定的回归斜率;而Class=1的斜率不是很明显。
下面绘制的是具有反相关的特征和Amount的关系图:
In [35]:
s = sns.lmplot(x='V2',
y='Amount',
data=df,
hue='Class',
fit_reg=True,
scatter_kws={'s': 2})
s = sns.lmplot(x='V5',
y='Amount',
data=df,
hue='Class',
fit_reg=True,
scatter_kws={'s': 2})
plt.show()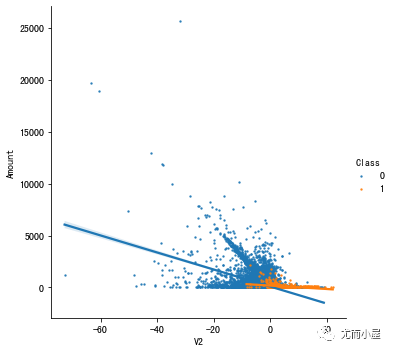
同样的结论:在Class=0的时候负相关性明显。
特征分布密度图
In [36]:
columns = df.columns.values
columnsOut[36]:
array(['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9',
'V10', 'V11', 'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18',
'V19', 'V20', 'V21', 'V22', 'V23', 'V24', 'V25', 'V26', 'V27',
'V28', 'Amount', 'Class', 'Hour'], dtype=object)In [37]:
i = 0
t0 = df[df["Class"] == 0]
t1 = df[df["Class"] == 1]
sns.set_style("whitegrid")
plt.figure()
fig, ax = plt.subplots(8,4,figsize=(12,20))
for column in columns:
i += 1
plt.subplot(8,4,i)
sns.kdeplot(t0[column], bw=0.5, label="Class = 0")
sns.kdeplot(t1[column], bw=0.5, label="Class = 1")
plt.xlabel(column, fontsize=12)
locs, labels = plt.xticks()
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show()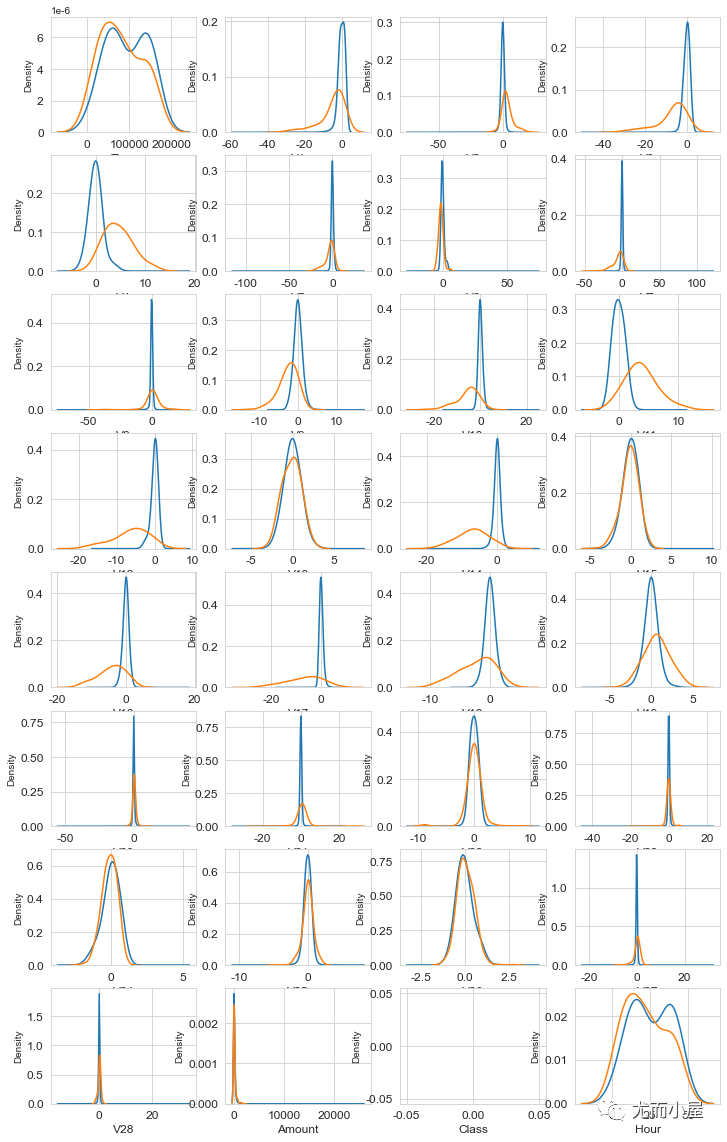
可以看到,部分特征有下面的特点:
V4和V11在Class=0或者1的情况下,分离性很好
V12、V14、V18 有部分分离
V25、V26、V28具有接近相同的数据分布
建模
目标和变量
定义预测目标变量和特征:
In [38]:
# 目标
target = 'Class'
# 特征
features = ['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7',
'V8', 'V9', 'V10','V11', 'V12', 'V13', 'V14','V15',
'V16', 'V17', 'V18', 'V19','V20', 'V21', 'V22',
'V23', 'V24', 'V25', 'V26', 'V27', 'V28','Amount']切分数据
先切分训练集和测试集:
In [39]:
TEST_SIZE = 0.20 # 测试集比例
RANDOM_STATE = 2023 # 随机种子
train_df, test_df = train_test_split(df,
test_size=TEST_SIZE,
random_state=RANDOM_STATE,
shuffle=True )再切分验证集:
In [40]:
VALID_SIZE = 0.20 # 验证集比例
train_df, valid_df = train_test_split(train_df,
test_size=VALID_SIZE,
random_state=RANDOM_STATE,
shuffle=True )RandomForestClassifier
模型训练与预测
基于随机森林建模;树模型不需要数据的归一化操作:
In [41]:
# rf
RFC_METRIC = 'gini'
NUM_ESTIMATORS = 100
NO_JOBS = 4In [42]:
clf = RandomForestClassifier(n_jobs=NO_JOBS, # 4
random_state=RANDOM_STATE, # 2023
criterion=RFC_METRIC, # 评估指标
n_estimators=NUM_ESTIMATORS, # 评估器个数
verbose=False)实施模型训练:
In [43]:
clf.fit(train_df[features], train_df[target].values)Out[43]:
RandomForestClassifier(n_jobs=4, random_state=2023, verbose=False)基于clf模型对验证集valid_df的预测:
In [44]:
valid_pred = clf.predict(valid_df[features])
valid_predOut[44]:
array([0, 0, 0, ..., 0, 0, 0], dtype=int64)特征重要性
随机森立模型的feature_importances属性可以返回特征的重要性:
In [45]:
clf.feature_importances_Out[45]:
array([0.0137962 , 0.01290299, 0.01301561, 0.0156942 , 0.03348877,
0.01203327, 0.01123946, 0.02267493, 0.01520727, 0.03879355,
0.08446134, 0.06249404, 0.13079459, 0.01028684, 0.13948669,
0.0114192 , 0.05495422, 0.17256602, 0.02514331, 0.01279881,
0.01048097, 0.01514546, 0.00886384, 0.00656329, 0.00914622,
0.00887252, 0.01777976, 0.01047754, 0.00909545, 0.01032364])In [46]:
fi = pd.DataFrame({"Features":features,"Importance":clf.feature_importances_})
fi.head()Out[46]:
| Features | Importance | |
|---|---|---|
| 0 | Time | 0.013796 |
| 1 | V1 | 0.012903 |
| 2 | V2 | 0.013016 |
| 3 | V3 | 0.015694 |
| 4 | V4 | 0.033489 |
按照重要性降序排列:
In [47]:
fi.sort_values("Importance",ascending=False,inplace=True, ignore_index=True)
fi.head(10)Out[47]:
| Features | Importance | |
|---|---|---|
| 0 | V17 | 0.172566 |
| 1 | V14 | 0.139487 |
| 2 | V12 | 0.130795 |
| 3 | V10 | 0.084461 |
| 4 | V11 | 0.062494 |
| 5 | V16 | 0.054954 |
| 6 | V9 | 0.038794 |
| 7 | V4 | 0.033489 |
| 8 | V18 | 0.025143 |
| 9 | V7 | 0.022675 |
In [48]:
plt.figure(figsize = (7,4))
plt.title('Features Importance Based On RandomForestClassifier',fontsize=14)
s = sns.barplot(x='Features',y='Importance',data=fi)
s.set_xticklabels(s.get_xticklabels(), rotation=90)
plt.show()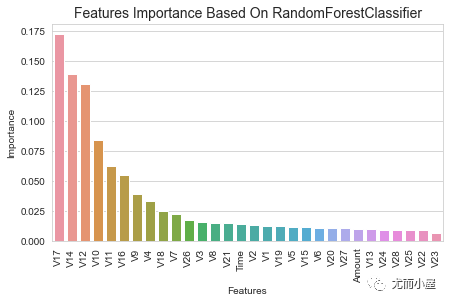
可以看到前5个重要的特征是:V17、V14、V12、V10、V11
混淆矩阵
In [49]:
cm = pd.crosstab(valid_df[target].values, valid_pred, rownames=['Actual Value'], colnames=['Predicted Value'])
fig, (ax1) = plt.subplots(ncols=1, figsize=(8,6))
sns.heatmap(cm,
xticklabels=['Not Fraud', 'Fraud'],
yticklabels=['Not Fraud', 'Fraud'],
annot=True,
ax=ax1,
linewidths=.2,
linecolor="Darkblue",
cmap="YlGnBu_r"
)
plt.title('Confusion Matrix Based On RandomForestClassifier', fontsize=20)
plt.show()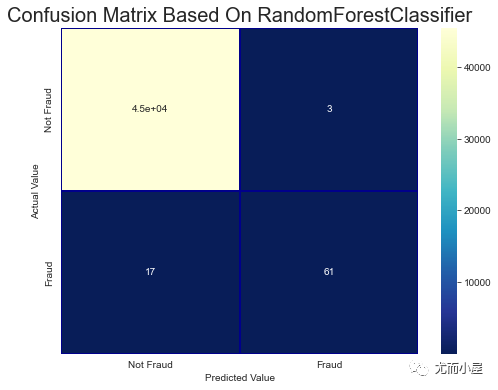
在分类问题中,当数据极度不均衡的时候,混淆矩阵一般不能够很好地反应结果。可以考虑一类错误或者二类错误。
我们可以考虑使用其他分类问题中的评估指标,比如:ROC-AUC
In [50]:
roc_auc_score(valid_df[target].values, valid_pred)Out[50]:
0.8909926674704323AdaBoostClassifier
Adaptive Boosting Classifier 表示自适应提升分类器,一种分类算法的组装方法,即将弱分类器组装成强分类器的方法。
模型训练与预测
In [51]:
ada = AdaBoostClassifier(random_state=RANDOM_STATE, # 2023
algorithm='SAMME.R',
learning_rate=0.8,
n_estimators=NUM_ESTIMATORS # NUM_ESTIMATORS = 100
)ada模型的训练:
In [52]:
ada.fit(train_df[features], train_df[target].values)Out[52]:
AdaBoostClassifier(learning_rate=0.8, n_estimators=100, random_state=2023)In [53]:
valid_pred = ada.predict(valid_df[features])
valid_predOut[53]:
array([0, 0, 0, ..., 0, 0, 0], dtype=int64)特征重要性
In [54]:
fi = pd.DataFrame({"Features":features,"Importance":ada.feature_importances_})
# 排序
fi.sort_values("Importance",ascending=False,inplace=True, ignore_index=True)In [55]:
plt.figure(figsize = (7,4))
plt.title('Features Importance Based On AdaBoostClassifier',fontsize=14)
s = sns.barplot(x='Features',y='Importance',data=fi)
s.set_xticklabels(s.get_xticklabels(), rotation=90)
plt.show()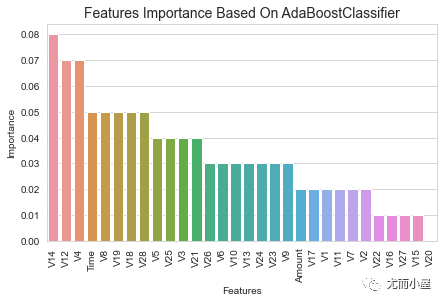
混淆矩阵
In [56]:
cm = pd.crosstab(valid_df[target].values, valid_pred, rownames=['Actual Value'], colnames=['Predicted Value'])
fig, (ax1) = plt.subplots(ncols=1, figsize=(8,6))
sns.heatmap(cm,
xticklabels=['Not Fraud', 'Fraud'],
yticklabels=['Not Fraud', 'Fraud'],
annot=True,
ax=ax1,
linewidths=.2,
linecolor="Darkblue",
cmap="YlGnBu_r"
)
plt.title('Confusion Matrix Based On AdaBoostClassifier', fontsize=20)
plt.show()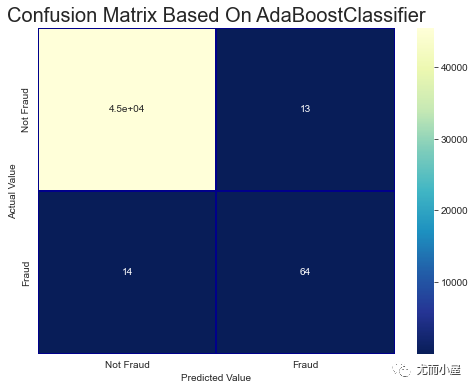
ROC-AUC的值:
In [57]:
roc_auc_score(valid_df[target].values, valid_pred)Out[57]:
0.9101135248505058CatBoostClassifier
CatBoostClassifier分类提升分类器也是一种梯度提升树,它支持处理分类型数据。
模型训练与预测
In [58]:
VERBOSE_EVAL = 50
cbc = CatBoostClassifier(
iterations=500,
learning_rate=0.02,
depth=12,
eval_metric='AUC',
random_seed = RANDOM_STATE, # 2023
bagging_temperature = 0.2,
od_type='Iter',
metric_period = VERBOSE_EVAL,
od_wait=100
)模型的训练:
In [59]:
cbc.fit(train_df[features], train_df[target].values,verbose=True)
0: total: 510ms remaining: 4m 14s
50: total: 16.9s remaining: 2m 28s
100: total: 32.6s remaining: 2m 8s
150: total: 47.9s remaining: 1m 50s
200: total: 1m 2s remaining: 1m 33s
250: total: 1m 17s remaining: 1m 17s
300: total: 1m 33s remaining: 1m 1s
350: total: 1m 48s remaining: 45.9s
400: total: 2m 3s remaining: 30.4s
450: total: 2m 18s remaining: 15s
499: total: 2m 33s remaining: 0usOut[59]:
<catboost.core.CatBoostClassifier at 0x1edb47a9190>基于cbc模型对验证集进行预测:
In [60]:
valid_pred = cbc.predict(valid_df[features])
valid_predOut[60]:
array([0, 0, 0, ..., 0, 0, 0], dtype=int64)特征重要性
In [61]:
fi = pd.DataFrame({"Features":features, "Importance": ada.feature_importances_})
# 排序
fi.sort_values("Importance", ascending=False, inplace=True, ignore_index=True)In [62]:
plt.figure(figsize = (7,4))
plt.title('Features Importance Based On CatBoostClassifier',fontsize=14)
s = sns.barplot(x='Features',y='Importance',data=fi)
s.set_xticklabels(s.get_xticklabels(), rotation=90)
plt.show()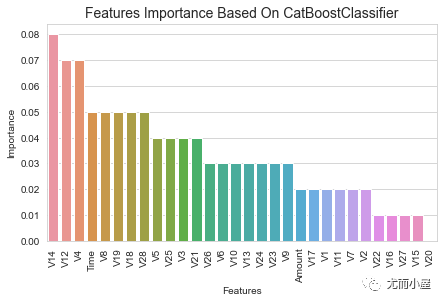
混淆矩阵
In [63]:
cm = pd.crosstab(valid_df[target].values, valid_pred, rownames=['Actual Value'], colnames=['Predicted Value'])
fig, (ax1) = plt.subplots(ncols=1, figsize=(8,6))
sns.heatmap(cm,
xticklabels=['Not Fraud', 'Fraud'],
yticklabels=['Not Fraud', 'Fraud'],
annot=True,
ax=ax1,
linewidths=.2,
linecolor="Darkblue",
cmap="YlGnBu_r"
)
plt.title('Confusion Matrix Based On CatBoostClassifier', fontsize=20)
plt.show()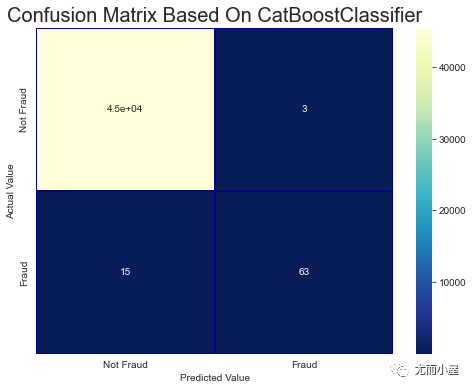
ROC-AUC的值:
In [64]:
roc_auc_score(valid_df[target].values, valid_pred)Out[64]:
0.9038131802909452XGBoost
XGBoost也是一种梯度提升树算法
数据准备
现将3个数据转成XGBoost模型所需要的数据格式:
In [65]:
dtrain = xgb.DMatrix(train_df[features], train_df[target].values)
dvalid = xgb.DMatrix(valid_df[features], valid_df[target].values)
dtest = xgb.DMatrix(test_df[features], test_df[target].values)In [66]:
watchlist = [(dtrain, 'train'), (dvalid, 'valid')]设置模型参数
In [67]:
params = {}
params['objective'] = 'binary:logistic'
params['eta'] = 0.039
params['silent'] = True
params['max_depth'] = 2
params['subsample'] = 0.8
params['colsample_bytree'] = 0.9
params['eval_metric'] = 'auc'
params['random_state'] = RANDOM_STATE训练模型
In [68]:
# 部分模型的参数设置
MAX_ROUNDS = 1000
EARLY_STOP = 50
OPT_ROUNDS = 1000
VERBOSE_EVAL = 50
IS_LOCAL = False
model = xgb.train(params, # 参数
dtrain, # 数据
MAX_ROUNDS,
watchlist,
early_stopping_rounds=EARLY_STOP,
maximize=True,
verbose_eval=VERBOSE_EVAL)
[17:52:22] WARNING: C:\buildkite-agent\builds\buildkite-windows-cpu-autoscaling-group-i-07593ffd91cd9da33-1\xgboost\xgboost-ci-windows\src\learner.cc:767:
Parameters: { "silent" } are not used.
[0] train-auc:0.86720 valid-auc:0.87807
[50] train-auc:0.92560 valid-auc:0.94196
[100] train-auc:0.95528 valid-auc:0.96492
[150] train-auc:0.97618 valid-auc:0.96857
[200] train-auc:0.98831 valid-auc:0.98431
[250] train-auc:0.99199 valid-auc:0.98761
[300] train-auc:0.99412 valid-auc:0.98951
[350] train-auc:0.99587 valid-auc:0.99085
[400] train-auc:0.99689 valid-auc:0.99157
[450] train-auc:0.99772 valid-auc:0.99227
[496] train-auc:0.99828 valid-auc:0.99207可以看到最好的ROC-AUC值是99.227%。
特征重要性
直接使用plot_importance方法绘制
In [69]:
fig, (ax) = plt.subplots(ncols=1, figsize=(8,5))
xgb.plot_importance(model,
height=0.8,
title="Features importance (XGBoost)",
ax=ax,
color="blue")
plt.show()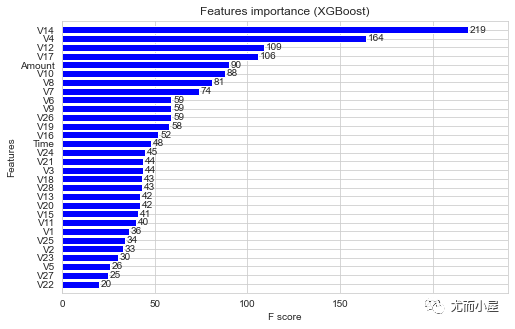
模型预测
基于模型的预测:
In [70]:
test_pred = model.predict(dtest)
test_predOut[70]:
array([5.2011404e-05, 2.5495124e-04, 1.5237682e-03, ..., 1.2446250e-04,
2.0297051e-03, 9.4309878e-05], dtype=float32)基于模型对测试集计算ROC-AUC值:
In [71]:
roc_auc_score(test_df[target].values, test_pred)Out[71]:
0.98309175770932LightGBM
定义模型参数
In [72]:
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric':'auc',
'learning_rate': 0.05,
'num_leaves': 7, # 小于的 2^(max_depth)次方
'max_depth': 4,
'min_child_samples': 100, # 最小子树个数
'max_bin': 100,
'subsample': 0.9,
'subsample_freq': 1,
'colsample_bytree': 0.7,
'min_child_weight': 0,
'min_split_gain': 0,
'nthread': 8,
'verbose': 0,
'scale_pos_weight':150,
}数据准备
In [73]:
train_df.head()转成lgb模型所需的格式:
In [74]:
dtrain = lgb.Dataset(train_df[features].values, # 特征
label=train_df[target].values, # 目标变量
feature_name=features) # 特征名称
dvalid = lgb.Dataset(valid_df[features].values,
label=valid_df[target].values,
feature_name=features)模型训练
In [75]:
evals_results = {}
model = lgb.train(params, # 参数
dtrain, # 数据
valid_sets = [dtrain, dvalid], # 交叉验证数据集
valid_names = ['train','valid'], # 名字
evals_result = evals_results,
num_boost_round = MAX_ROUNDS,
early_stopping_rounds= 2 * EARLY_STOP,
verbose_eval = VERBOSE_EVAL,
feval = None
)
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.011147 seconds.
You can set `force_col_wise=true` to remove the overhead.
Training until validation scores don't improve for 100 rounds
[50] train's auc: 0.986784 valid's auc: 0.92025
[100] train's auc: 0.982458 valid's auc: 0.906221
Early stopping, best iteration is:
[2] train's auc: 0.97387 valid's auc: 0.97051特征重要性
In [76]:
fig, (ax) = plt.subplots(ncols=1, figsize=(8,5))
lgb.plot_importance(model, # 使用 plot_importance方法
height=0.4,
title="Features importance (LightGBM)",
ax=ax,
max_num_features=30,
color="red"
)
plt.show()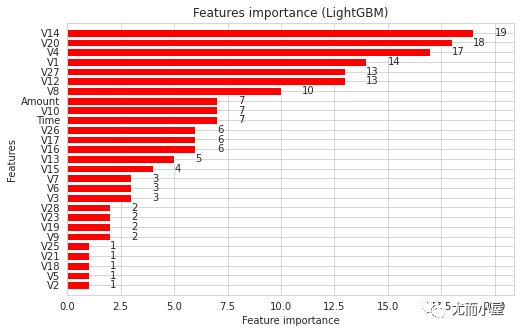
模型预测
In [77]:
test_pred = model.predict(test_df[features])
test_predOut[77]:
array([0.00295975, 0.00288036, 0.9999795 , ..., 0.00497163, 0.00295975,
0.00295975])计算ROC-AUC值:
In [78]:
roc_auc_score(test_df[target].values, test_pred)Out[78]:
0.951076589143652交叉验证 cross-validation
实施基于5折的交叉验证:
定义Kfold实例
In [79]:
NUMBER_KFOLDS = 5 # 折数
kf = KFold(n_splits = NUMBER_KFOLDS,
random_state = RANDOM_STATE,
shuffle = True)定义初始矩阵
定义全0矩阵,用来存储最终结果。
In [80]:
oof_preds = np.zeros(train_df.shape[0])
test_preds = np.zeros(test_df.shape[0])
feature_importance_df = pd.DataFrame()
n_fold = 0实施交叉验证
In [81]:
for train_idx, valid_idx in kf.split(train_df):
train_x, train_y = train_df[features].iloc[train_idx], train_df[target].iloc[train_idx]
valid_x, valid_y = train_df[features].iloc[valid_idx], train_df[target].iloc[valid_idx]
evals_result = {}
# 模型定义
model = LGBMClassifier(
nthread=-1,
n_estimators=2000,
learning_rate=0.01,
num_leaves=80,
colsample_bytree=0.98,
subsample=0.78,
reg_alpha=0.04,
reg_lambda=0.073,
subsample_for_bin=50,
boosting_type='gbdt',
is_unbalance=False,
min_split_gain=0.025,
min_child_weight=40,
min_child_samples=510,
objective='binary',
metric='auc',
silent=-1,
verbose=-1,
feval=None
)
# 模型训练
model.fit(train_x,
train_y,
eval_set=[(train_x, train_y), (valid_x, valid_y)],
eval_metric= 'auc',
verbose= VERBOSE_EVAL,
early_stopping_rounds= EARLY_STOP
)
# 模型预测概率
oof_preds[valid_idx] = model.predict_proba(valid_x, num_iteration=model.best_iteration_)[:, 1]
test_preds += model.predict_proba(test_df[features], num_iteration=model.best_iteration_)[:, 1] / kf.n_splits
# 特征重要性
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = features
fold_importance_df["importance"] = model.feature_importances_ # 原文是 clf.feature_importances_
fold_importance_df["fold"] = n_fold + 1
# 生成dataframe:feature + importance + fold
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
# roc-auc值
print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(valid_y, oof_preds[valid_idx])))
# 回收机制
del model, train_x, train_y, valid_x, valid_y
gc.collect()
n_fold = n_fold + 1
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=-1 will be ignored. Current value: num_threads=-1
[50] training's auc: 0.975109 valid_1's auc: 0.964242
Fold 1 AUC : 0.966735
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=-1 will be ignored. Current value: num_threads=-1
[50] training's auc: 0.973376 valid_1's auc: 0.97159
[100] training's auc: 0.974581 valid_1's auc: 0.975146
Fold 2 AUC : 0.976924
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=-1 will be ignored. Current value: num_threads=-1
[50] training's auc: 0.971525 valid_1's auc: 0.981105
[100] training's auc: 0.973605 valid_1's auc: 0.979233
Fold 3 AUC : 0.981177
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=-1 will be ignored. Current value: num_threads=-1
[50] training's auc: 0.970153 valid_1's auc: 0.981887
Fold 4 AUC : 0.983433
[LightGBM] [Warning] num_threads is set with n_jobs=-1, nthread=-1 will be ignored. Current value: num_threads=-1
[50] training's auc: 0.980285 valid_1's auc: 0.962565
Fold 5 AUC : 0.965422In [82]:
train_auc_score = roc_auc_score(train_df[target], oof_preds)
print('Full AUC score %.6f' % train_auc_score)
Full AUC score 0.949809
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









