







1.监督学习和无监督学习的概念
样本有标签的叫监督学习,样本没有标签的叫无监督学习。
监督学习中,标签为类别的叫分类问题(classification),标签为实数的叫回归问题。
无监督学习一般比监督学习更难处理,聚类(clustering)是一种常见的无监督学习方法。经常先用PCA或者t-SNE(Principal Component Analysis , t-distributed Stochastic Neighbour Embedding)对样本进行降维处理,然后再对降维后的数据进行可视化,观察无监督数据的特点。
2.监督学习转换成无监督学习的例子
大部分人刚开始学习机器学习的时候,会从非常有名的数据集开始,比如泰坦尼克数据集(Titanic dataset)或者鸢尾花数据集(Iris dataset),这两个都是监督学习问题。
一些无监督学习的例子有顾客细分或者信用卡欺诈检测(通过聚类的方法对客户进行归类)。
大部分时候,可以把监督学习的数据集转换成无监督的数据集,通过可视化来观察数据的特点。
2.1MNIST数据集的无监督方法
MNIST,手写数字识别,是一个很流行的监督学习问题,一般是构造一个模型,可以根据输入数字的图片(0-9)判断出输入的数字是什么。
这个问题可以转换成无监督的问题进行可视化。
通过t-SNE方法将输入的图片数据降成2维,然后画出降维后的数据散点图。
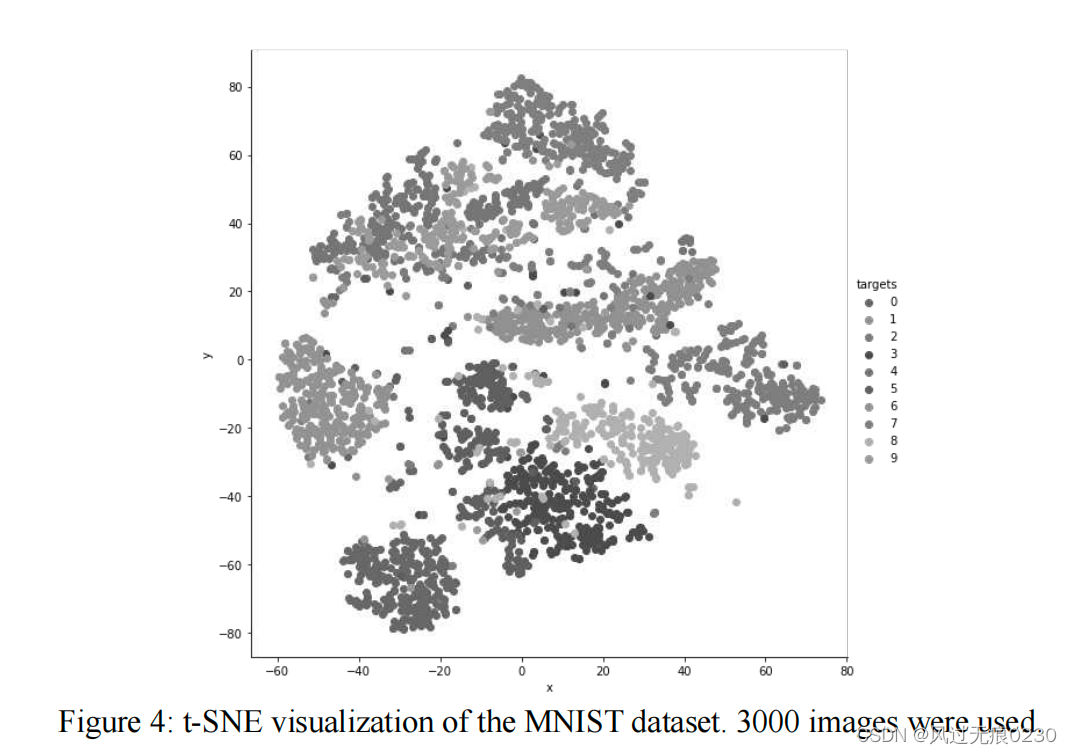
从可视化结果可以看到,降到2维后,不同数字的样本点有明显的聚类现象。
2.2具体代码
- 导入相关包,matplotlib和seaborn用来画图,numpy用来处理数组,pandas用来根据数组构建dataframe,sklearn用来获取MNIST数据和执行t-SNE。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn import datasets
from sklearn import manifold
# %matplotlib inline 可以在Ipython编译器比如jupyter notebook 或者 jupyter qtconsole里直接使用,
# 功能是可以内嵌绘图,并且省略掉plt.show()
%matplotlib inline
- 获取数据集,将标签由字符串格式改为整数格式
# 用fetch_openml方法获取MNIST数据集
data = datasets.fetch_openml('mnist_784',
version=1,
return_X_y=True)
# 数据集分为特征(dataframe)和标签(series)两部分
# pixel_values维度是(70000, 784),表明有70000张图片,每张图片尺寸为28*28=784
pixel_values, targets = data
# 标签本身为字符串格式,要转换成整数
targets = targets.astype(int)
- 可视化一张图片
# 取位置为1的样本,转换成数组,然后变成28 * 28的图片形状
single_image = np.array(pixel_values.loc[1, :]).reshape(28, 28)
# 方法2:可以用dataframe.values转换成数组
# single_image = pixel_values.loc[1, :].values.reshape(28, 28)
# 绘制热图,输入single_image为数组格式,cmap简单理解成图片颜色
plt.imshow(single_image, cmap='gray')
- 对前3000条数据进行tsne转换(降维)
# 创建tsne转换
tsne = manifold.TSNE(n_components=2, random_state=42)
# 对前3000条数据进行拟合转换,维度由(3000, 784)变成(3000, 2),结果为数组格式
transformed_data = tsne.fit_transform(pixel_values[:3000])
- 将降维后的特征和标签按列拼接,创建为dataframe
# 将降维后的特征和标签按列拼接,创建为dataframe
tsne_df = pd.DataFrame(
np.column_stack((transformed_data, targets[:3000])),
columns=["x", "y", "targets"]
)
#tsne_df["targets"] = tsne_df.targets.astype(int)
- 可视化3000条数据结果
# 根据targets进行分类,size为展示图片的尺寸
g = sns.FacetGrid(tsne_df, hue="targets", size=4)
# 绘制散点图,横纵坐标分别为x和y,添加图例
g.map(plt.scatter, "x", "y").add_legend()















 3758
3758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









